The Big Data paradigm (or buzzword, depending on your point of view) has been formulated on the basis of the 3Vs (Volume, Velocity and Variety). While researchers and engineers over the world are working hard to control the 3Vs of what is a true data tsunami, it is crucial that we address new scientific issues that could help in structuring the research in the field.
While giving a keynote at a recent Phi-Tab workshop (Phi-Tab is a data science think tank launched by Orange and the Mines-Telecom Institute), I attempted to define some challenges for the Big Data research.
Big Algebra
Whenever they are working on a Big Data solution to solve a given problem, data scientists bear a strong resemblance to alchemists. They carefully prepare the data, choose and configure the data processing method (or more often a succession of methods), they choose and configure the tools to visualize the results, interpret those results and their uncertainty… This process is a complicated tangle of steps where they invariably make good use of their know-how and expertise.

« chymie » before the invention of modern chemical equation notation – Diderot and d’Alembert Encyclopedia – Source Wikipedia.
When notation for chemical equations was invented, it was a real breakthrough leading to the appearance of modern chemistry, just as the invention of notation for modern algebra once boosted the development of mathematics.
In order to note, share or reason about Big Data operations, should we not invent a suitable algebra notation? In order to program a Big Data processing chain, should we not develop a suitable programming language?
Regarding that last point, one might well wonder whether APL, a mythical language that dates back to the 70s, might not be pressed into service once again… after undergoing a substantial facelift, naturally!
Big Noise
Data Mining specialists are well aware that simply accumulating data does not suffice to extract any useful information. As Pierre Dac (or was it Alphonse Allais?) used to say, “Everything is in everything… and vice versa”. The Spurious Correlations website proves the point in a humorous way: one will always find a sign (in this case, a simple correlation due to chance) in any very large mass of data.
The issue concerning how to tell “a sign” from “background noise”, or “information” from “random chance”, is still being debated throughout the scientific community.

From Data to information (Inspired from Big Data’s Argyle Principle)
Business and political decisions will increasingly be made by human beings (or machines, as in high-frequency trading) on the basis of Big Data analyses. As a result, new “data spam/scan” techniques are set to make an appearance, which will consist in generating massive amounts of false “data” aiming at manipulating aggregated information or at introducing a bias in the decisions made. For instance, a false tweet generator to create a buzz that will stem quite naturally from the Tweeter analysis robots; or a browser plugin that produces false Google requests to conceal from Google what the search engine user is actually doing, which will undermine the Google and Adsense data model.
The “inverse problem” is also a science topic to be widely debated: how can you, by injecting as little biased or false information as possible, succeed in modifying the findings of a data mining chain and in introducing a bias that is favourable to the cheater in its conclusions? How can you detect and prevent that kind of behaviour?
It will soon become necessary to fight against “data spam” to preserve the value of Big Data, and it will become crucial to meet the challenges facing source authentication and the “traceability” of decision-making chains.
Big Time
The integration of time in Big Data is poorly handled. To give an example, identifying that the birth rate depends on events (which come in a great variety) that happened 9 months earlier (factors that might have affected conception), or possibly factors having occurred 20 to 30 years earlier (education, war etc.), is not something that can be done with the usual Big Data tools. In the same way, being able to extract real-time information from a large stream of data or events (fast data) remains difficult. Lastly, the predictable upcoming explosion off sensors in the Internet of Things will generate the a tremendous increase in data collected that will far exceed our data storage capacity. It will therefore be necessary to choose which raw data to store, and which data to discard.

The issue of time is becoming a critical aspect of Big Data research, so as to make the difference between “causality” and “correlation”, as well as to allow for analysis/decision/action cycles in order to decide which data to store.
Big Structures
Historically, Big Data and data mining technology started out processing data of a very basic nature and structure: tables of numbers (for instance, age, pay, phone calls made etc.), tables of characteristics (male or female, hometown etc.), graphs (who is linked to whom)… In software terms, data science started with simple data types.
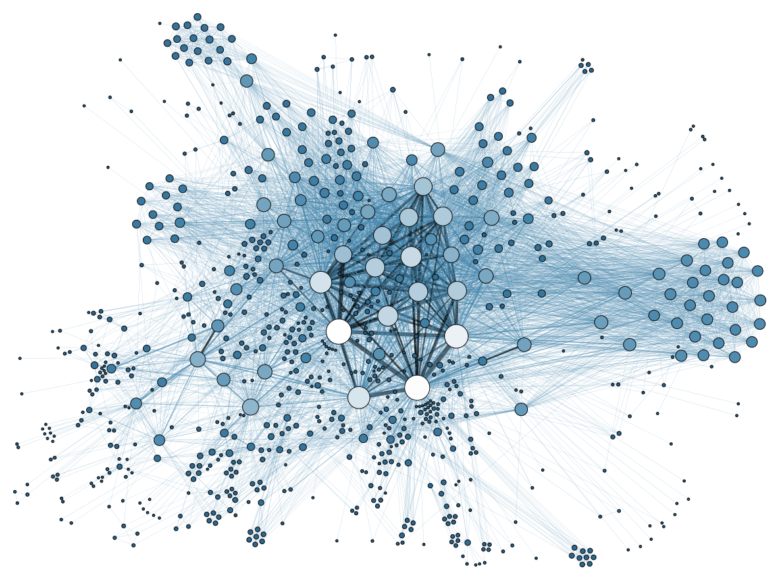
A visualization of a social network – Source: Wikimedia
But issues surrounding very large masses of data involve data whose nature and structure are far more diverse: images, videos, substantial corpuses of books like those held in the Bibliothèque Nationale de France, geographic data within geographic information systems, physical world parameters ranging from the subatomic scale to the astrophysical scale, living world parameters ranging from the unfolding of a protein to the complex dynamics of the entire biosphere, models of sophisticated technological objects and more.
The first age of massive data processing mainly involved “flat” tables and graphs, which are relatively basic data structures. In the future, it will be necessary to work on data structures that are more complex and hierarchical. We still have to come up with the right architectures and tools to collect, store and analyse such a great diversity of massive data structures.
Big Reality
The explosion in Big Data can actually help to quantify a growing share of our physical world and to supply information for models and decision-making in a growing number of fields: Big Data can provide tools to analyse physical phenomena like weather or astronomy, sources of knowledge like Web or document processing, or interaction analyses like those based on social graphs. However, that great Internet mirage, further amplified by the Big Data prism, carries the risk of believing that reality is what is illustrated as data. As a result, that which has not been measured is not found in the analyses.

The Big Data “mirage” should not blind us to the existence of that which in the real world has not yet been quantified. Photo ND
Big Human
One last point to consider concerns the multiple human factors related to Big Data. The fascination or rejection provoked by those new technologies will inevitably cause a string of miscellaneous fears and myths.
Given the human brain´s limited ability to grasp large amounts of information, we will be confronted with new problems in visualizing and illustrating massive data.
Our cognitive processes (including intuition), which have developed over millions of years to get the most information from a small amount of data, will be put to the test by those new abilities to analyse massive data.
“The only really valuable thing is intuition” (Albert Einstein). Source: Wikimedia
In the 18th century, statistical science revealed the limitations of our intuition. Now we face the issue of integrating Big Data capacities to enhance our cognitive processes.
Big Data evolution or revolution?
Ultimately, Big Data is nothing more than a technological evolution based on a simple change of scale: to do quickly and massively something that we were able to do with a small amount of data. Yet this change of scale is at the root of a profound change of paradigm in scientific fields with profound impact in the economic and in the political approaches for the future.
But couldn’t the true revolution concern human issues? A new way to perceive the world, a redefining of intuition, a new symbolic space with its own fears and its own myths?
Surely, this is not in the same league as Hilbert’s 23 problems (1), but I would be interested in finding out what the community thinks about those issues.
(1) Incidentally, Hilbert did a lot of work on the links between mathematics and intuition… if he had known about Big Data, he would undoubtedly also have taken a hard look at the links between “big mathematics” and intuition.
More info:
[1] Big Data – Wikipedia
[2] Alchimie et Histoire de la Chimie – Wikipedia
[3] Big Data’s Argyle Principle
[4] Les 23 problèmes de Hilbert
[5] Hilbert’s program – Standford Encyclopedia of Philosophy
Ecosystem:

Phi-TAB Coopération Orange – Telecom Paristech pour développer des méthodes d’optimisation et d’apprentissage statistique pour l’analyse de données massives. Contact Adam Ouorou – adam.ouorou@orange.com