


For researchers in Natural Language Processing (NLP), this model is certainly new but its principle is already well known. More recently, Le Monde relied on the testimony of experts in NLP to qualify the hype: “GPT-3, artificial intelligence that has taught itself almost everything it knows”[4].
Let’s try to demystify what is behind GPT-3, this 3rd generation of “Generative Pre-Training”, the last link in the evolution from language models to Transformers architecture.
“Has GPT-3 enabled the discovery of generalist AI? The remarkable progress associated with it does not so much come from its ability to generate texts, but rather to carry out tasks after being exposed to a very small number of examples.”
A new generation of language models
In less than a decade, research in Natural Language Processing (NLP) has been overturned by the appearance of a suite of language models trained in an unsupervised manner on very large corpora. These models, trained to predict words, have proved capable of “capturing” the general linguistic characteristics of a language. Mathematical representations of words that could be obtained by opening the cover of these models proved to be very relevant. Therefore, they have become the bridge between language words and mathematical representations in the form of vectors that serve as the entry point for neural networks responsible for solving NLP tasks.
Originally, in 2013, word embeddings (such as Word2Vec, Glove, or Fasttext) were able to capture representations of words in the form of vectors taking into account the context of neighbouring words in large volumes of text. Two words appearing in similar contexts were “embedded” into N-dimensional space, to neighbouring points in this space. This approach has led to significant advances in the field of NLP, but also has its limitations. From 2018 a new way of generating these word vectors emerged. Rather than selecting the vector of a word in a previously learnt static “dictionary”, a model is responsible for dynamically generating the vector representation of a word. A word is thus projected to a vector not only according to its prior meaning, but also according to the context in which it appears. The models for effective realisation of these contextual projections (BERT [6], ELMO and derivatives, GPT and its successors) are based on a simple yet powerful architecture called Transformer.
Released in December 2017, Transformers [5] are the latest major technological revolution in the field of Natural Language Processing.
A Transformer consists of an encoder and a decoder:
- the encoder is responsible for encoding the input for maximum input context consideration;
- the decoder generates the prediction in an auto-regressive way: predictions are made step by step and the result of one prediction is used as input for the next prediction.
The key to success of this approach is the use, at all levels of this neural network, of an attention mechanism which allows the context to be efficiently handled. While previous approaches (“Recurrent Neural Networks” or “Convolutional Neural Networks”) could model contextual dependencies, they were always constrained by referencing words by their positions. Attention is about referencing by content. Instead of looking for relationships with other words in the context at given positions, attention allows you to search for relationships with all words in the context, and through a very effective implementation, it allows you to rely on the most similar words to improve prediction, whatever their position in context.
The outputs of these models have been followed at an increasingly rapid pace. Each new model was trained on larger and larger corpora (Wikipedia, then Common Crawl), its size became larger and larger (huge number of parameters) and the computing power required for its training became more and more significant. Of course, each new model could “capture” more general linguistic characteristics of a language than its predecessor. Multilingual models trained on data from different languages have even appeared, opening the way for new applications. In theory, each new model should therefore have been be more relevant for the applications where they were used by researchers to train their own models. In reality, things are a little bit more nuanced.
From BERT to GPT-3: A technological advance
According to François Yvon, researcher at the LIMSI/CNRS: “Technically, it is complicated. Conceptually, it is simple. I am more impressed by the technology than by the science behind GPT-3”[4]. Indeed, the GPT-3 model, the latest in the family of “Generative-Pre Training” models produced by OpenAI [16], builds on previous architectures but is trained on much more data.
OpenAI builds upon a strong belief in Generalised Artificial Intelligence. This belief assumes the emergence of cognitive capacities if the network exceeds a critical size, and that every reasoning tasks can be processed through the symbolism of language, by making the network manipulate the textual description of the task.
For the scientific community, the GPT-3 model has so many parameters that the question now arises as to whether it would be possible to implement a Turing machine using a similar language model. If so, this model would have the ability to solve all the tasks that can be assigned to a computer. However, as yet there is no theoretical answer to this question. For GPT-3, there is also no empirical or practical response. However, it is certain that this model marks a turning point, and the question will be asked again for subsequent models.
Efforts to create more powerful models will continue.
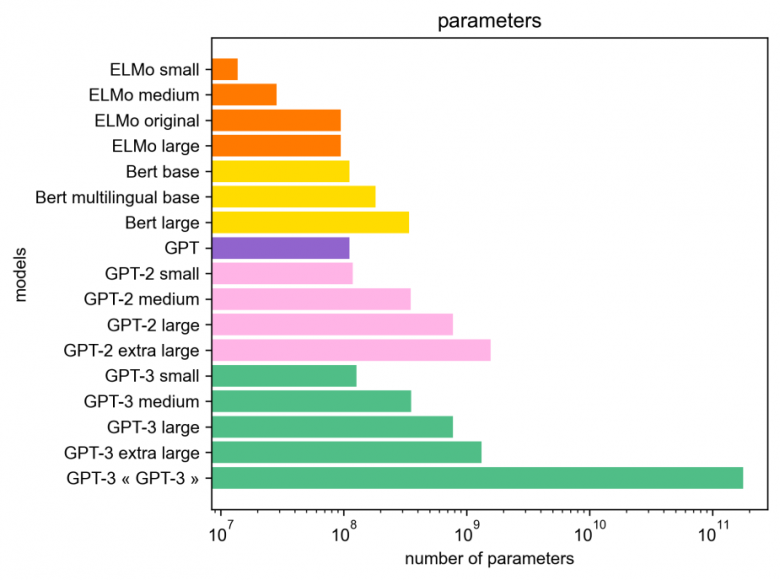
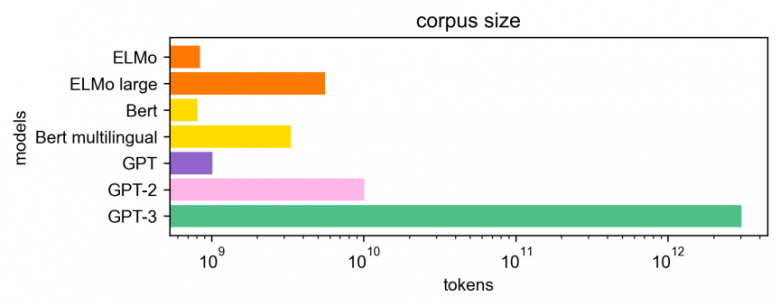
The significant advance of models such as GPT-3 is that they allow so-called “zero-shot”, “few-shots”, “one-shot” approaches, requiring little or no specifically annotated data for each task[7]. This is a clear advantage over supervised learning models which require annotated training data. In this sense, significant progress can be expected on tasks for which this model is well suited, such as generation. It should also be tested on close tasks, such as those of Dialogue, and more distant tasks such as Relation Extraction. The ability of the GPT-3 model to be trained or adapted to languages other than English or to be used in several languages at once (multi-languages) may also be of interest. Given the volume of data in English that was needed to train the original model, this question remains open for languages with fewer resources, including French.
Benoit Favre, researcher at the LIS laboratory at the University of Aix-Marseille with whom Orange regularly collaborates, shares his view here.
“Has GPT-3 enabled the discovery of generalist AI? The spectacular progress associated with it does not so much come from its ability to generate texts, but rather to carry out tasks after being exposed to a very small number of examples (“few-shots learning”), without the underlying Neural Network having been explicitly supervised for this purpose. The link between “predict the next word” supervision and the emergence of such capabilities remains a fundamental open question for the community. For example, it is not known whether these capabilities come from the supervision of the language model or from the architecture of the Transformers. Nor do we know whether the model stores the data it receives during training and is merely an elaborate mechanism for recalling the data. GPT-3 has been shown to perform some linguistic tasks, generate programmes, or even play chess, but it does not know how to do simple arithmetic operations (and is probably a poor chess player). These observations raise the question of the generality of this phenomenon and the nature of the tasks that can be derived from the model. Moreover, as was the case with the ‘discovery’ of linguistic regularities in word embedding spaces, the community is mainly interested in selected examples which are not very representative of the overall capabilities of the model. From a natural language processing perspective, GPT-3 extends relatively conventional approaches with larger models trained using more data. Today, it is unclear how to go beyond the distribution of these data from the web, how to exploit the model outside English, an overrepresented language, and how to address language diversity. Another problem related to distributional representativeness is the bias, especially societal bias, which language models merely reproduce. All these issues were already present before GPT-3 and remain current. As for the intelligence that would be associated with GPT-3, the community is divided on the textual nature of the data used to train it. What is certain is that GPT-3 raises the question of the nature of intelligence, and opens the way to new research directions beyond NLP, for example in cognitive sciences on the emergence of human brain capacities”.
Societal challenges
Models such as ELMO, BERT, GPT-2 have opened up the horizon of possibilities and, through their free availability, have stimulated or even accelerated global research. The number of scientific publications citing these models is evidence of this. But GPT-3 is not available to researchers. OpenAI offers it in a “as a service” mode, and is developing an API to adapt it to application needs (“finetuning”). In addition, Microsoft recently reserved OpenAI productions by purchasing an exclusive licence to operate.
Building an equivalent free model would be a dream. But only a few players could afford to do so. Given the size of the model (175 billion parameters, i.e. 1000 times more than the large networks used in images), it requires an enormous computing capacity to learn it. In addition to the financial costs (several tens of millions of euro), this learning would have an energy cost that would be difficult to meet [9] [10] [11].
Added to this is the cost for using these models. GPT-3 weighs 240GB, so it cannot be deployed in production without a cluster of GPU servers, which are well known for their financial and energy expenses.
Instead, the current trend is to limit the size of the models, facilitate deployment and reduce the energy footprint. This can be achieved, for example, by learning “distilled” models, which are simplified models learnt by being guided by a large original model. The method has already been successfully applied on GPT-2 and BERT for example[8]. However, the cost of this distillation remains high and it requires the original model to have already been trained. On the other hand, it is possible to obtain quite encouraging results, sometimes better than the original model!
The opacity of GPT-3 learning data also raises ethical issues. The learning packages are not freely accessible and only the authors of the model can check whether or not they have collected bias-free texts. Moreover, it seems difficult to achieve such package sizes without using some kind of data augmentation technique, which consists of using texts that contain an artificially generated part and thus are not derived from human production.
Transformers for NLP at Orange
At Orange, some teams work on a daily basis with Transformer-type models. They use these models to deal with most of the problems of language and natural dialogue, in research, but for a short while also in production, for opinion mining in customer feedback [17].
These Transformers have made significant improvements in the extraction of information from customer feedbacks in several languages. The multilingual capability of BERT models now makes it possible to envisage deploying a single model to analyse data from all countries where Orange has customers. At the same time, these models are being used for Natural Language Understanding and to carry on benchmarks for interaction services deployed within the Group.
The classification and information extraction tasks (sentiment analysis, personal data detection, detection and identification of named entities, syntactic dependency analysis, semantic parsing, co-reference resolution) applied to Orange data have all experienced a qualitative leap forward with the use of these contextual language models. Machine Reading Question Answering (MRQA), which consists of examining documents through questions, also relies on Transformers. The various components of the dialogue systems also use the latest generation of models. Finally, encoder-decoder Transformers such as GPT2 are used for natural language generation to help question-answering systems to generate answers to open-domain questions.
Conclusion
The release of the GPT-3 model has left its mark in the minds of journalists who have relayed their hopes, doubts and fears to the general public. It has also impacted the scientific community. This article seeks to put this release in context in order to ask rational questions about this model. It also answers some of them. Answers to all these questions will only be possible once GPT-3 is freely accessible. Nevertheless, the authors hope that they have provided new insights into a topic which is just one fascinating part of what they work on on a daily basis to achieve responsible and human AI.
Find out more:
- Podcast le nouveau monde de FranceInfo, 11/09/2020, https://www.francetvinfo.fr/replay-radio/nouveau-monde/nouveau-monde-gpt-3-cette-intelligence-artificielle-qui-ecrit-des-articles-presque-toute-seule_4087053.html
- Le Figaro, 21/08/2020, https://www.lefigaro.fr/secteur/high-tech/gpt-3-une-intelligence-artificielle-capable-de-rivaliser-avec-ernest-hemingway-20200821
- MIT Technology Review, 14/08/2020, https://www.technologyreview.com/2020/08/14/1006780/ai-gpt-3-fake-blog-reached-top-of-hacker-news/
- Le Monde, 03/11/2020, https://www.lemonde.fr/sciences/article/2020/11/03/gpt-3-l-intelligence-artificielle-qui-a-appris-presque-toute-seule-a-presque-tout-faire_6058322_1650684.html
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems.
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Agarwal, S. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
- Distillation https://github.com/huggingface/transformers/tree/master/examples/distillation
- Libération, blog Hémisphère gauche, 06/08/2020, http://hemisphere-gauche.blogs.liberation.fr/2020/08/06/lintelligence-artificielle-generale-comme-propriete-privee/
- Conférence Sustainable NLP: https://sites.google.com/view/sustainlp2020
- Strubell, E., Ganesh, A., & McCallum, A. (2019). Energy and policy considerations for deep learning in NLP. arXiv preprint arXiv:1906.02243.
- Kevin Lacker’s blog, 06/07/2020, https://lacker.io/ai/2020/07/06/giving-gpt-3-a-turing-test.html
- Qasim Munye, 02/07/2020, https://twitter.com/QasimMunye/status/1278750809094750211
- Amanda Askell (compte Twitter), 17/07/2020, https://twitter.com/AmandaAskell/status/1283900372281511937
- MIT Technology Review, 22/08/2020, https://www.technologyreview.com/2020/08/22/1007539/gpt3-openai-language-generator-artificial-intelligence-ai-opinion/
- OpenAI is a company founded in December 2015 by tech giants Elon Musk and Sam Altman, with support from Tesla, Amazon Web Services, Ycombinator, Peter Thiel, LinkedIn, with a budget of one billion dollars.
Its mission is to conduct research in generalised artificial intelligence (GAI) for the “common good”. Initially an association, it has evolved into a limited profit association. Microsoft has invested quite heavily, and recently signed an exclusive licence to use GPT-3 models.
For internal use:
17. https://hellofuture.orange.com/en/progress-in-the-semantic-analysis-of-the-voice-of-the-customer/
18. https://hellofuture.orange.com/fr/lintelligence-artificielle-expliquee-aux-humains/
19. https://hellofuture.orange.com/en/semantics-holy-grail-artificial-intelligence/







