


Exchange and processing of data sets in businesses
Data linking makes it possible to discover new information that is currently underexploited and could lead to significant developments in the practices and services offered by businesses. The use, management, and sharing of data repositories have therefore become crucial aspects of business competitiveness.
However, these data uses, which were previously closed and protected in the silos of businesses and organizations, have a number of problems associated with them. Consider the case of Paul the meteorologist. He has compiled a set of data on an approaching storm, called Jupiter, in a single working document. He thinks this information could be of interest to others and might be shared outside the limits of his project, his team, and even his business. To make sure his document can be found, he needs to set out its contents in a way that can be understood by anybody, regardless of prior knowledge.
The first thing to note here is that the released data is based on specialist expertise that not all users of the data set will necessarily have. This knowledge gap between the producer and the consumer means that the consumer cannot easily understand the data (insufficient understanding to deploy machine learning algorithms, for example). The second point is that opening a large number of data sets makes it substantially more complex to search for data (a challenge tackled by the new search engine Google Dataset, among others). As with traditional search engines, therefore, indexing efforts are required in order to allow users to quickly find the relevant data sets for their needs.
Many use cases require a breaking down of the barriers between data silos (correlating data from different sets, for example). This task is made more complex by many forms of data heterogeneity due to the different languages and formats or even the use of specialist terminology specific to each author. The same information can be represented in different ways depending on the storage file format or the representation model used (one database table may have a “customer Telephone” field and another one might have a “Ctc_CustTel” field).
Opening data up to third parties is an important development in terms of uses. However, businesses remain reluctant to share it for fear of the potential risks (the appropriation of a data sat without a prior agreement, for example). Symmetrically, the consumer expects guarantees regarding the precision, completeness, credibility and traceability of the data. Traceability and credibility are two concepts that are directly linked. Data traceability means that the consumer is aware of the process (the sequence of modification steps carried out by one or more contributors) that led to the production of the data set. Data on traceability is useful for understanding the current state of the data set and for validating its provenance and the reliability of each contributor. This ability to evaluate the data set allows consumers to determine whether they consider the data set to be suitably credible for the context in which they wish to use the data.
A metadata template to describe it all
To meet these needs, our team has designed and developed Dataforum, a search platform that provides a data set exchange service. This platform allows an ecosystem of businesses to describe, share and use their data quickly, easily and securely. Specifically, a common description template for data sets has been introduced in order to meet two objectives: first of all, to describe the contents of the data set in order to make it easier for the user to appropriate and understand, and to limit the need for a specialist to get involved; and secondly, to offer a metadata template that is generic enough to describe a wide variety of data sets and to be completed by “specialist” descriptions (healthcare, biology, telecommunications, etc.). Such a detailed and homogeneous description makes it easier to find and recommend data sets, making it possible to imagine new use cases that could potentially create added value.
For example, the statement “Paris is located in France” can be expressed in the form of an information triplet <subject, predicate, object>, where “Paris” is the subject, “is located” is the predicate, and “France” is the object. This information is then stored in a knowledge graph, which structures it and reconciles the different heterogeneous data sources. The proposed template, called sem4ds (semantics for data sets), is implemented using the semantic languages RDF, RDFS and OWL2. These languages formally define the concepts and properties that can be used to describe a data set via “information triplets” that can be read by both humans and IT programs.
To allow the sem4ds template to present the contents of a data set but also to specify the type of use that is permitted (for example, using the data set with or without the ability to modify it) and to show the various actions performed on that data set (copying, editing, etc.), a collection of semantic vocabularies that are in widespread use in the community has been used (DCAT[1], PROV-O[2], and CCREL[3]). This template has been extended to give precise information on the operations performed on the data sets during their creation, editing, and deletion.
The general metadata describes the data set and its distributions (the files associated with a data set) to make it easier to find, understand and use. The technical metadata provides information to make it easier to access and process the data set: location, size, document format, etc. Finally, the traceability metadata supplies information on the various operations performed on the data set. The template that has been selected to provide traces of use, PROV-O, is based on three main concepts: entity (the data set or distribution), activity (for the creation, editing, or deletion of an entity), and agent (who initiated the activity). It answers the questions: “who did what?”, “why?”, and “when did they do it?”. The figure below shows how the PROV-O template is used to trace an edit action: a Météo France technician modified the license on a data set on October 7, 2019 at 9:55am.
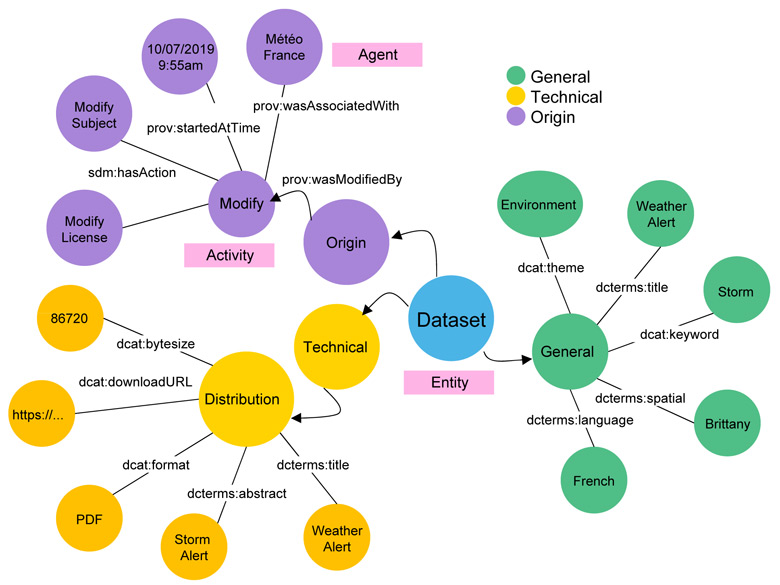
Figure 1 Detailed presentation of the descriptors of a data set with the technical, general, and provenance metadata.
For any data set, this machine-readable template enables an improved indexation of metadata in a knowledge base, making it easier to find thanks to a specialized search engine.
Data semantization, searching and recommendation
Providing a detailed description of a data set in a standardized form aimed at all potential users places a higher workload on the producers of the data to document the data set correctly. To minimize their investment, Dataforum partially automates the description of the contents of data sets using machine learning and automatic language processing technologies.
These tools make it possible to automatically extract certain important metadata such as the themes, key words, language, geographical coverage, or even the format and size of the data sets. This metadata is the concept for the sem4ds template. This semantization is done in two steps: firstly, the format of the document or data set and the language in which it has been drawn up are identified. The second step is to extract the key words from the text part, the theme, geographical coverage, and details on the structure of the data set.
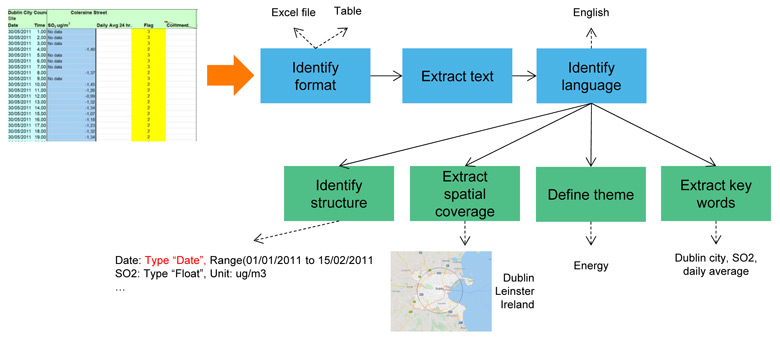
Figure 2 Automatic description of a data set.
The expressiveness of the sem4ds template means that Dataforum is able to offer a search engine with numerous filters such as key words, theme, license, language, format, or even last modified date. These filters correspond to particular items of metadata in the sem4ds semantic template and offer the user a wide range of search criteria, improving the relevance of the results.
All the metadata generated during the creation and updating of a data set will be fed into a knowledge base. When a user makes a search, the search engine queries that base. To do this, it automatically translates the search criteria selected by the user into a query in SPARQL, an RDF graph query language. The SPARQL query searches the global knowledge base graph for data sets that match the user’s query.
Imagine that our user wants to make the following query: “Give me all the data sets in English that deal with the theme of the environment and contain the key words ‘winter storm’.” The figure below gives a partial view of the current search engine interface (part A). The data sets matching the search are then presented in a way that is concise and easy to understand, thanks to the metadata from the sem4ds template (part B of the figure below).
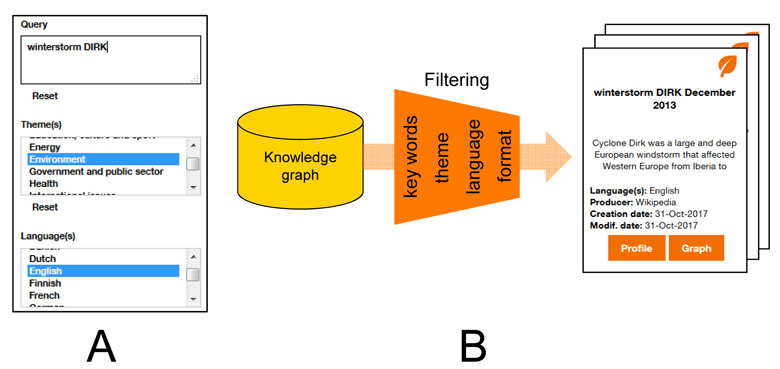
Figure 3 View of the search engine interface: the data sets matching the search are presented in a way that is concise and easy to understand, thanks to the metadata from the sem4ds template.
In addition to the search engine, Dataforum also offers a recommendation engine to make it even easier to identify the right data sets for a use case. Suppose a user is searching for data sets on storms similar to JUPITER (the one shared on Dataforum by Paul the meteorologist). The search engine presents the user with weather station documents about a storm called DIRK. Finally, the recommendation system returns a document about DIRK, but from an economic angle rather than an environmental one. The aim is to enable the discovery of new data sets based on those used by the user. The results of the recommendation are presented in a graph that gathers data sets with similar themes and key words into a single space. This enables the display of a large selection of data sets while also allowing the suggested data sets to be consulted one by one. The similarity of the different data sets is calculated on the basis of their content using the Reperio engine (Orange Labs).
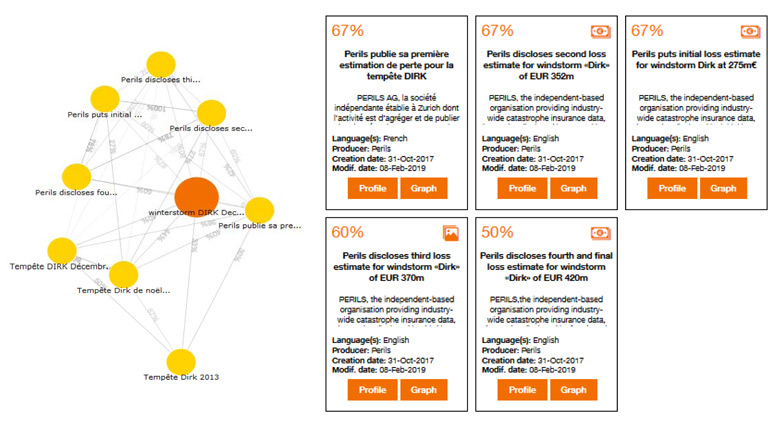
Figure 4 Similarity graph (how close one data set is to other data sets), left, and “map” view, right
Conclusion
Thanks to sem4ds, a common language for describing data sets, businesses can share data sets quickly, easily, and securely. They can also specify what they are looking for in detail, as the data set metadata contained in sem4ds can be used to filter the search results. Finally, a recommendation system suggests data sets that have metadata in common with an original data set. No matter what differences there are between organizations, Dataforum offers a single, optimized way to describe and share data.
Dataforum is the result of an integrative innovation process carried out by a team of ten people at Orange Labs in Belfort, Lannion, and Sophia Antipolis, which specialize in the Semantic Web, automatic language processing, and artificial intelligence, as well as a team of developers.
Development on this platform has been ongoing since 2017, and it now has the necessary quality level to be used in an operational context. Its main functions are currently being transferred to the provision of a data exchange platform to be used by departments within Orange for their internal needs. Improvements will be made in 2020. In particular, research is currently underway on the automatic characterization of tabular data. The aim here is to use semantic concepts to annotate the entities that form a table (cell, line, column, and relationships between and within columns) to allow the knowledge graph to be queried semantically (and not syntactically as at present). Another research effort focuses on the use of the Dataforum service through voice commands. This will give suppliers the option of describing the data sets they are publishing either manually or verbally, which in turn will make for a more flexible process of describing the data set carried out by the semantization chain. Users will be able to speak their queries out loud, making the service even easier to use. A voice recognition system will translate the various queries into text form, which will then be used either to augment the knowledge base or to construct a request with the appropriate syntax. A final improvement will be to provide a fully distributed architecture by providing each business with the ability to specify which of the other businesses in the ecosystem it wishes to share with and to change this configuration in a dynamic manner depending on its objectives at any given time.
[1] Data Catalog Vocabulary (DCAT)
[2] PROV-O: The PROV Ontology
[3] ccREL: The Creative Commons Rights Expression Language
Find out more:
- Ontologies for the rest of us!
- Chabot, P. Grohan, G. Le Calvez, and C. Tarnec, “Dataforum: Faciliter l’échange, la découverte et la valorisation des données à l’aide de technologies sémantiques [Dataforum: Facilitating the Exchange, Finding and Recovery of Data Using Semantic Technologies]”, EGC 2019: Conference on Knowledge Extraction and Management, 2019.
- Halevy et al., “Goods: Organizing Google’s Datasets”, Proceedings of the 2016 International Conference on Management of Data – SIGMOD ’16, 2016, pp. 795–806.
 Yoan Chabot
Yoan Chabot







