DAGOBAH, a research platform resulting from Artificial Intelligence projects, aims at providing an end-to-end, context-free, semantic annotation system for tabular data, resulting in enriched knowledge graphs that users can then leverage on to meet several needs. DAGOBAH is an on-going collaborative research project developed by Orange Labs teams from Belfort and Rennes in association with EURECOM Data Science Department from Sophia Antipolis.
From table data to knowledge
“Information is not knowledge”[1]. Albert Einstein famous quote is based on the assumption that knowledge can only be gained from experience. If we apply this though to tabular data –that can be assimilated to raw information-, this implies it will be meaningless without people expertise (experience) in the corresponding domain. This is true. But if we consider expertise as a background knowledge that can be represented and encoded into a core referential, there might be a way to transform raw data into knowledge in the light of this seed, giving birth to new knowledge at the same time. We believe information can be knowledge. How so? Let’s board for a journey to DAGOBAH. [2]
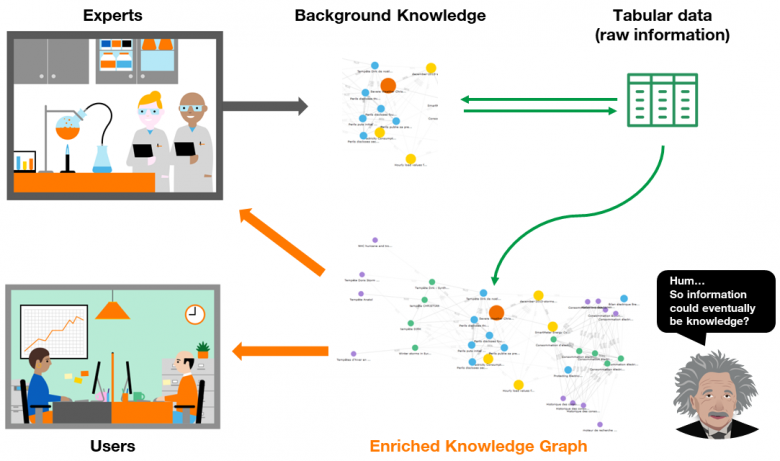
Figure 1: From Tabular Data to Semantic Knowledge
In order to make tabular data meaningful, it is necessary to understand the types of information within each column and row, as well as the relationships between them. This is done by adding semantic labels to every element of the table, also called “semantic annotation”, which could be divided into three main tasks:
- Column-Type Annotation (CTA): labeling the type of a given column (e.g. ‘film’ type);
- Cell-Entity Annotation (CEA): disambiguate the value of all cells in the table (e.g. the city of ‘Rennes’, the year ‘1990’, the movie title “Les Beaux Gosses”);
- Column-Property Annotation (CPA): find the semantic relationship between columns (e.g. <film> ‘released in’ <year>, <film> ‘shot in’ <location>).
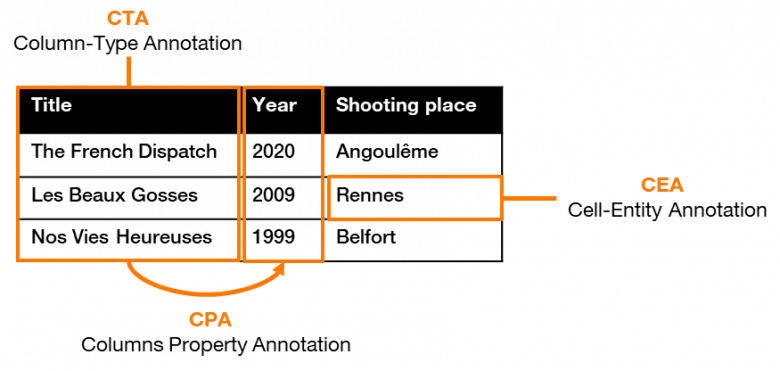
Figure 2: Semantic Annotation Tasks
If some high-level features can be generated from scratch through table analysis (e.g.: 4-digits type, string type), the labeling cannot be semantically explicit without the use of an existing knowledge base (e.g.: person type, country type, movie type) which are more and more available through graph representations. In this kind of representation, each entity has explicit attributes (e.g.: “Angoulême” is an instance of “commune of France”), and semantic relationships can be expressed in the form of an information triple <subject, predicate, object> (e.g.: “The French Dispatch” is the subject, “filming location” is the predicate, and “Angoulême” is the object).
The Wikidata knowledge graph acts as the central storage for structured data coming from its Wikimedia sister projects including Wikipedia, Wikivoyage, Wiktionary, Wikisource, and others. It gathers more than 80,000,000 data items, and grows every day. Knowledge graphs exist in many different domains, as can be seen from the Linked Open Data Cloud.
Table annotation using knowledge graphs is an important problem as large parts of both companies’ internal repositories and Web data are represented in tabular formats. This type of data is difficult to interpret by machines because of the limited context available to resolve semantic ambiguities and the layout of tables that can be difficult to handle. The ability to annotate tables automatically using knowledge graphs (encyclopedia graphs such as DBpedia and Wikidata or enterprise-oriented knowledge graphs) allows supporting new semantic-based services, both for experts and non-experts users. For example, it opens the way to more efficient solutions to query (e.g. “moving beyond keyword” for dataset search), manipulate and process heterogeneous table corpus. This can add great value if integrated within datasets sharing platform like Dataforum for instance. The DAGOBAH platform tackles this annotation challenge, through an end-to-end processing of tabular data.
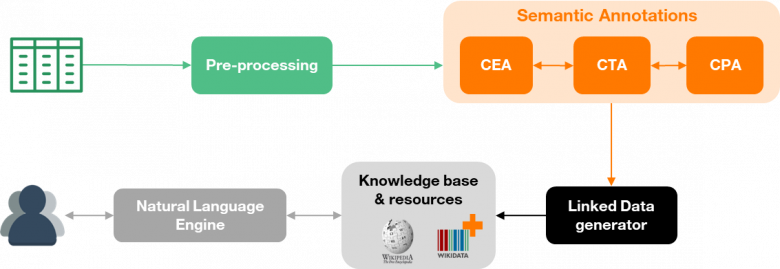
Figure 3: DAGOBAH Pipeline
Preprocessing for tables characterization
In order to make relevant labeling, it is necessary to proceed to a high-level cleaning of the data and convert the tables into a proper format to work with. Once this step is done, the first challenge that arises is to have the best understanding of the table structure, which is not trivial due to the very nature of the corpuses. Indeed, tables can have both structural (vertical or horizontal orientation, line/column fusion, no header…) and semantic heterogeneity (acronyms/abbreviations, phrases/short strings, numerical, multilingual…), as well as incomplete and sometimes dynamic data [Figure 4].
Figure 4: The Data Table Scream (aka The Format Nightmare)
In a context of real exploitation in which there is sometimes little or no knowledge for the tables, the information produced by this preprocessing is decisive for the quality of the annotations. The pre-processing toolbox of DAGOBAH, partly based on the DWTC extractor, generates four different types of information:
- Primitive cell typing (based on eleven pre-defined types, e.g.: string, floating number, date…)
- Table orientation detection (horizontal if attributes’ entries are in columns, vertical if they are in rows)
- Header extraction
- Key column detection (DWTC algorithm), which identifies the subject of the triples to be generated from the table data
We evaluate the DAGOBAH algorithms, which are based on a new homogeneity factor, and we observe significant better performance than the state-of-the-art for table orientation and header detection (from 62% to 85% in mean precision). The output of this preprocessing chain can then be used to run the core annotation phase.
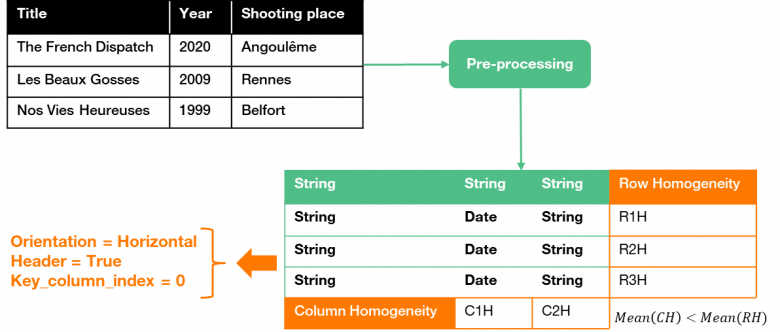
Figure 5: Table Pre-processing
Annotating using lookups and neural embedding techniques
A natural approach to add semantic labels to table elements is to use lookup services from existing knowledge sources (Wikidata API, DBpedia API…) in order to retrieve candidates from cell mention. We can use multiple lookup services at the same time and then count the number of occurrences of common results to select the most popular candidates and their corresponding types. Nonetheless, a basic type coverage of the cells criteria (i.e. choose the most frequent type through classical “majority voting” mechanism) is not relevant as right types might be more specific but not frequent enough to be consider as the target ones. To solve this issue, we make use of some heuristics combined with a simple TF-IDF-like method (Term Frequency – Inverse Document Frequency, often used in natural language processing to combine quantitative and qualitative characteristics of a given term). The type with the best balance between specificity and frequency is selected at the end (CTA task output) which is used to disambiguate the entities candidates (CEA output).
This baseline is easy to implement and can have high entities coverage as one can query all sources relevant to the table domain, but it has many drawbacks:
- Lookup services dependency (reliability)
- Blackbox results generation (indexing, scoring strategy…)
- Queries volumetry
As a consequence, the data cleaning phase becomes even more critical to increase the matching probability with knowledge bases entities.
To bypass these issues, DAGOBAH relies on embeddings techniques. The principle, first applied to unstructured text, is to encode each word taken into account its context (which is, in a nutshell, the preceding and following words) through a simple neural network learning the distribution of word pairs. After weights of hidden layer have been optimized, the hidden representation of each word is extracted, which corresponds to a vector in the target space. The interesting specificities of this representation are that resulting vectors capture the latent semantic relationships between words: similar words will be closed in the embedding space, and vector compositions remain meaningful (e.g. Oscars Awards – USA + France = César Awards), allowing analogical reasoning (e.g.: Wes Anderson is to “The French Dispatch” what Riad Sattouf is to “Les Beaux Gosses”) [Figure 6].
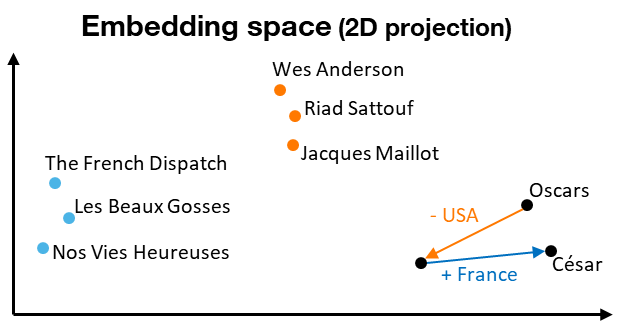
Figure 6: Embeddings Properties
Embeddings are widely used in natural language processing, given rise to many implementations not restricted to unstructured text. In particular, it is now possible to apply embeddings to knowledge graph like Wikidata for instance, which is precisely what DAGOBAH uses (based on a pre-trained model from Open KE). The intuition behind this approach is that entities in the same column should be closed in the embedding space as they share semantic characteristics, and thus could form coherent clusters.
After an enrichment of a raw embedding (with different aliases values associated to each entity), a lookup is done to select candidates from the knowledge graph that could match a given entity in the table. These candidates are clustered in the vector space, reducing the annotation problem to clusters ranking to find the most relevant one for a given column and extract the target type and correct entities [Figure 7]. A confidence score associated to each candidate is also used to resolve the remaining ambiguities if needed.
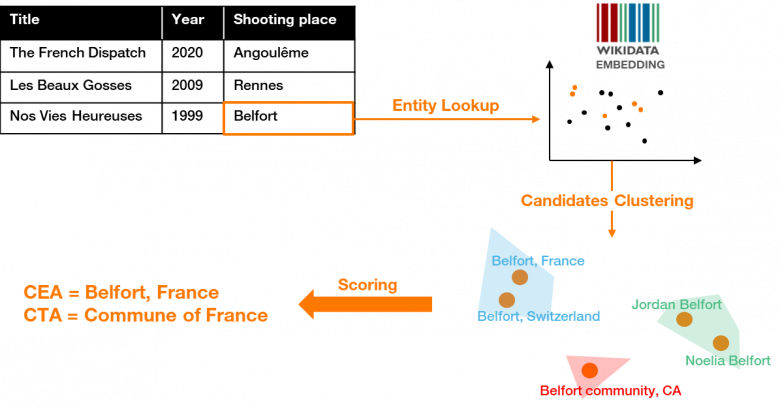
Figure 7: Semantic Annotation through Embeddings
The embedding approach outperforms the baseline and proves to be highly proficient to determine the type of a column which is the core of more reliable annotations. In addition, the results are particularly interesting in cases where string mentions in the original table are incomplete or highly ambiguous (e.g. homonyms).
Semantic annotation as a key asset for new services
Now you have discovered DAGOBAH under the hood, you probably ask yourself: “nice engine… but how far can I go with it to enhance my services?” Let’s take a concrete example: the last movie from Wes Anderson (The French Dispatch) exists in the public knowledge graph you used to query. Unfortunately, this knowledge graph is not up-to-date, and some information is missing, such as the filming locations (this is precisely the case in Wikidata). On the other hand, you have another source providing some raw movie data in tabular format but you never dived into it. If you want to enrich the original knowledge base with these data, you can make some joins if there is at least one common attribute to use as a key, but to do so, you need to know the data model. Moreover, the mapping might lead to complex ambiguities and time-consuming development which will be tailored with this specific data source (thus, not generalizable). Finally, you will not leverage the power of semantic relationships you already have in the knowledge graph.
This is exactly where DAGOBAH will be useful, by transforming tabular data into semantic knowledge in the light of the existing knowledge graph that will be painlessly and coherently enriched. As a result, the users will now be able to query your enhanced service in natural language without having a disappointed blank answer [Figure 8].
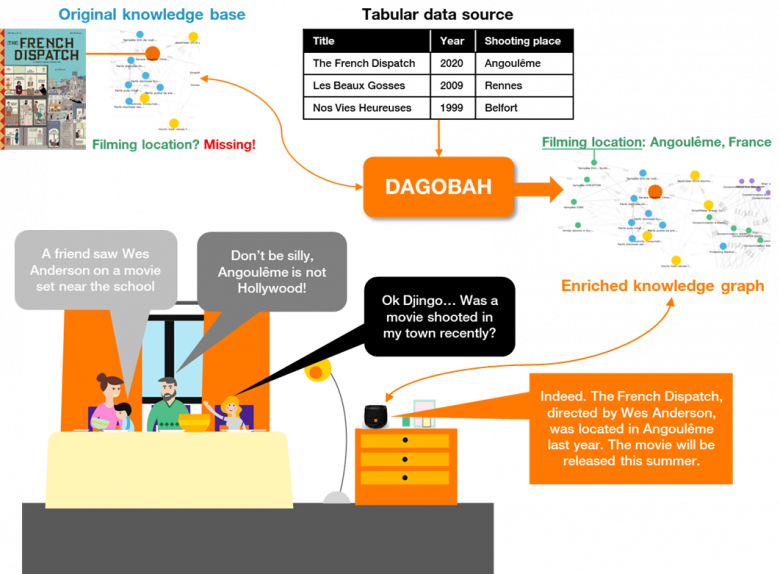
Figure 8: Enhanced Service thanks to Knowledge Graph Enrichment
Conclusion
As described in this article, the end-to-end annotation processing leads to knowledge enrichment since unmatched entities from the original table can be reliably added with the correct type and relationship: the hidden knowledge is transformed into meaningful triples. The resulting knowledge graph is directly usable by users with no needed expertise. Moreover, it produces metadata that can be used for dataset referencing, search and recommendation processes like Dataforum.
Nonetheless, some challenges remain as tabular data within companies’ data lakes are often sticked to specific business knowledge hardly intelligible by the neophyte and not referenced in public knowledge bases. In the best case, links may be found between some business data and encyclopedic knowledge (e.g. movie service consumption). If not, a knowledge seed has to be produced with domain experts to start the annotation process. In every case, extracting knowledge from data table is a key asset to enhance knowledge access and to imagine more valuable services!
DAGOBAH is a collaborative research project developed by Orange Labs teams from Belfort (Yoan Chabot, Jixiong Liu) and Rennes (Thomas Labbé) in association with Prof. Raphaël Troncy from EURECOM Data Science Department, Sophia Antipolis. These activities are integrated into two research programs in the “Decision and Knowledge” domain led by Henri Sanson: “Distributed Intelligence Platform” (Thierry Nagellen) that aims to analyse and describe massive structured and semi-structured data and “Natural Language Processing and Application” (Frédéric Herlédan) that focuses on ontological knowledge extraction from data.
[1] Einstein, Albert. Ideas And Opinions (p. 271). Crown Publishing Group.
[2] Yoan Chabot, Thomas Labbe, Jixiong Liu, Raphaël Troncy: DAGOBAH: An End-to-End Context-Free Tabular Data Semantic Annotation System. ISWC 2019 Semantic Web Challenge, Auckland, New Zealand (ISWC is the premier international forum, for the Semantic Web, Linked Data and Knowledge Graph Community)
 Yoan Chabot
Yoan Chabot