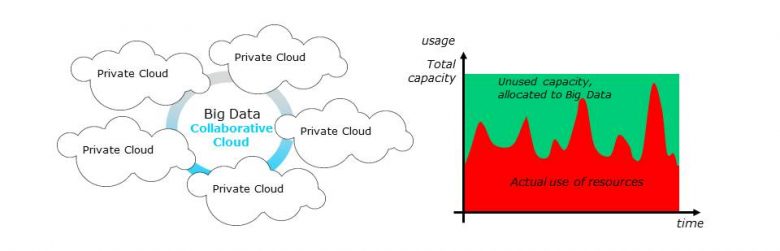
While the public cloud has grown very strongly over the past decade, private datacenters still account for almost 70% of IT server investments and twice the amount of resources. These are scaled according to their peak load and the infrastructures are partly redundant to withstand hardware failures. As a result, 50 to 80% of private datacenter capacities are unused at any given time. This is neither optimal from an economic point of view, nor really environmentally acceptable when we know that the electronics industry is one of the leading polluters on Earth.
At the same time, there is an exponential need for computing resources to run Big Data processes. But investing in dedicated resources is very expensive and the alternative based on market-leading public clouds (Google, Amazon, Microsoft) does not guarantee strict data privacy, especially given US regulations (Cloud Act).
The Airbnb of private datacenters
Our technical solution, which is being developed as part of a project of the Institute for Technological Research b<>com, of which Orange is a founder member, falls within this context. It offers a distributed Big Data runtime platform based on the dormant IT resources of multiple private datacenters.
As part of the current project, we have chosen to focus on intra-company use, considering the datacenters of the same company and internal Big Data processes. However, the software architecture is designed to subsequently move to a multi-enterprise collaborative cloud.
A cultural, technical and operational challenge
The solution must meet various requirements, on which our research and development work focuses. The first challenge is cultural: private clouds have not been designed to be open. We need to convince operators that this is possible without risk, even though we are considering an intra-company model. We are integrating monitoring and security mechanisms to guarantee resource providers that their internal services will not be impacted. The second challenge is technical and consists of ensuring good quality of service when resources are unstable, distributed and disparate. To do this, the project incorporates upstream work on consumption prediction mechanisms and placement algorithms based on learning and monitoring at the level of each server in the infrastructure. The goal is to provide consumers with a quality at least equivalent to what can be found in the public cloud, with the added benefit of data privacy. This work has resulted in several scientific publications, within the framework of the b<>com project carried out by the Institute for Technological Research. Finally, the third challenge is operational: the solution must be easy to install and use, as are other cloud products and services, in addition to being cost-effective and competitive and thus attractive as a public cloud-computing offering.
3 to 4 times less expensive
To validate the competitive aspect, we conducted an economic study of a Big Data use case, considering a need equivalent to 12 servers and 11 TB of storage. At this stage, only a cost model is incorporated and we are not including the potential margin of resource providers and the solution carrier. These results show that the cost of running on such a platform could be 3 to 4 times lower than on a private cloud or on an entry-level public cloud offering. This allows for attractive pricing for consumers, while allowing revenue to be generated for resource providers and the carrier.
As part of the current project, we have decided to focus our work on the Big Data use case and in particular, on the Apache Spark framework. On the one hand, this is because Big Data frameworks already natively integrate distributed infrastructure support and resilience mechanisms, and on the other because we believe that this is where the greatest need for computing resources lies.
At this point, we have developed the basic services to automatically deploy a collaborative cloud solution in a distributed environment and ensure logical isolation between the different applications. Now our goal is to consolidate and then integrate the work on smart placement and prediction, considering the Big Data use case.
We are in the process of integrating the b<>com datacenter solution and plan to extend these tests to Orange infrastructures in Q2 2020, before experimenting with external partners in the second half of 2020.
By using this technical solution, companies and public authorities could both leverage their existing infrastructures and have a competitive, sovereign alternative to the public cloud for their Big Data needs. It would also be an opportunity for them to position themselves as drivers of a new, collaborative and environmentally conscious economy.
Contact: ivan.meriau@orange.com