- Cyber-Physical Universe
- Data
- Decisions and knowledge
- Software infrastructure
- Sustainable digital society


MSPs are cohesive sets of hardware/software components or services that allow parties from different categories (“market sides”) to engage in information-mediated transactions through the platform. MSPs typically generate economies of scale as network effects starting from the demand end of value chains, rather than from supply, as used to be the case in the pre-network economy.
These platforms are the hubs of the networked economy, the leading disrupters that engineer the creative destruction of incumbent intermediaries and other ponderous gatekeepers to the antecedent stovepipes of economic value chains. Their business and pricing models have been widely studied together with the incentives that can attract affiliates to the different sides of the platform, making it possible to jumpstart network effects. Yet, for all their proclaimed revolutionary intents, many MSPs are still closed data vaults managed by an exclusive for-profit operator. Non-profit platform operators are the exception rather than the rule (with the Wikimedia foundation as a leading example). The truly radical proposition is, however, that of fully decentralized platforms which, when they do exist, can achieve a magnitude of network effects unmatchable by any centralized operation. The Web is still the most successful example of such a fully bottom-up platform. It still manages to serve as an entry point to all other platforms and a minimal connector between them : as closed as the new platforms may wish to be, they still have to open up a little bit just to be on the web.
The original Web was intended for human users. The “Web of Data”, heralded by the blooming archipelago of Linked Data, is an even more sweeping proposition, intended to federate not only documents consumed by human readers, but all pieces of stored data consumed by programs. It has the potential to federate existing platforms to achieve network effects on their behalf. Does this portend the ultimate disruption of disrupters? Could the web of data and programmable resources subsume existing MSPs into a meta-platform of its own, just as these have smothered their less competitive brethren in the course of their expansion? MSPs that are already in billion-users territory have nothing to fear on this front…We focus here on the example of a new, highly fragmented domain for which there are no dominating or federating MSPs, only myriads of narrow and low-level data collection platforms: the Internet of Things, even when promoted to the level of a Web of Things, is in pressing need of being de-compartmentalized, and Linked Data may be a winning proposition for doing just this, federating data islands into the “Semantic Web of Things”.
From the web of documents to the web of things and the programmable web
Successful as it may be as a two-sided (hypertext documents/human users) platform, the reach of the original web can still be extended by orders of magnitude on both sides, leveraging the universality of its protocols. On the lower side, it may address as its ultimate scope not only text documents, but things from the real-world. This one idea may have different incarnations in practice. It these things are networked devices, they may provide a web-level interface of their function through the network : typically an actuator will provide an interface for remote action and a sensor will provide an interface for remote data gathering. For things that are not networked devices, the nodes of the Web of Things graph can be informational descriptions/models/proxies or just pieces of data about these things. In a less obvious way, any physical thing may have its own web-based identification (as a “non-informational-resource”) that redirects to a functional sensing interface through sensors that sense it, or to a data interface through a proxy that maintains information about it. The web of things graph gets, in this latter view, extended to include as its nodes the physical things themselves, not only their informational “shadows”.
On the user side, a crucial extension consists in using the web protocols as an interface to programs as consumers of data, in addition to direct human end-users, leading to the idea of the programmable web. This extension is very obviously associated with the previous one, as most of the data about things is not of direct interest to human users, or has at at least to be filtered, processed and analysed before it can be of real use to them.
The semantic web, a brilliant idea that never took off?
Public awareness of the semantic web is often traced back to the pioneering 2001 eponymous article by Tim Berners-Lee in Scientific American, which has since then become one of the most cited publications (~20 000 citations to date…) in the entire Information Technology literature. This popularity is misleading, because the actual use of the semantic web by practitioners (developers & webmasters) has not followed the universal recognition that it is, indeed, a supremely beautiful idea…
The semantic web can, at the very minimum, be seen as the superimposition, upon the original web of documents, of an overlay semantic graph, whose nodes define, by their mutual relationships, the concepts, classes and categories from which instances and subclasses represented in documents are derived. This is intended to make the meaning of natural language documents or identifiers used in such documents explicit and machine-understandable rather than implicit and exclusively human-understandable. The actual deployment of the semantic web in all its glory would, in principle, mandate an exhaustive a priori annotation of all terms used in web documents by reference to formally defined, ontologies. This not only a daunting task, it is totally unrealistic for legacy documents and web sites. These ontologies themselves define relevant terms formally by specifying relationships to more general and complementary terms. They make up a multi-level directed acyclic graph encompassing a hierarchy from domain-specific to transversal and upper ontologies. This ethereal semantic graph, chimerical as it may seem in its overreaching breadth and depth, is supposed to build the keystone of the semantic web architecture. 15 years into the making, this overarching semantic superstructure of the web is still but a ragtag juxtaposition of piecemeal and highly heterogeneous ontologies, superb in some domains and sorely lacking in others. In the current situation, search engines have learnt to compensate for the lacks of semantics embedded in their primary sources of content by letting these semantics emerge from the structure of links and percolate through it. Powerful as it may be, this “knowledge graph” is enclosed in the data vaults of search engine operators, nowhere near the open and universal platform that the semantic web could have become. Search engines are still geared to the web as a document/human-user platform and they do not (yet) address the needs of the web as a things/programs platform, where less data-intensive approaches may still have a role to play.
Linked Data : grassroots semantics
The “Linked Data” program, set off, once again, by no less an authority than Sir Tim himself, has emerged as a more pragmatic approach from the nonfulfillment of the top-down & ontology-driven approach to the semantic web. Linked Data is, in a sense, a return to the original idea and the essence of the web itself as a graph, whereby the most useful information resides within the links and their structure, more than in the nodes themselves. More importantly, whereas the semantic web was initially conceived as a mere overlay on the web of documents, linked data is geared to the web of data, the web of things and the programmable web from the ground up. With linked data, the nodes are not just documents, they can be any snippets of data, wherever they come from and to whomever they are destined. The links to these individual pieces of data may actually be latent : what matters is the possibility to become a receptacle of incoming links by the systematic use of HTTP identifiers as names for things, acknowledging the pivotal role of web protocols for this.
RDF (Resource Description Framework) can be used for describing these things as the subject of properties that link them to objects, where both links and objects do themselves reference further URIs, but it is not mandatory to use a full-fledged hierarchy of ontologies for this. An enlightening analogy is that linked data make for a “folksonomy” or “social tagging” type of description, similar to what people have become used to do by tagging pictures on popular photo sharing sites or social networks. Contrary to rigid taxonomies, these tags do not use categories drawn from a predefined hierarchy, yet when they are numerous enough, a stable classification may nonetheless emerge from their distribution. Another feature of such bottom-up classifications is that conflicting classifications or identifications may be reconciled after the fact without the need to roll back the previous stages of classification that may have led to the conflict. Assuming an entity gets two different identities form two different infrastructures, it is not necessary to rename them (which would itself create broken links and cascading inconsistencies…) to avoid conflict : just adding an additional RDF link with the “owl:sameAs” predicate does the trick.
Linked Data defines principles for publishing structured data so that it can be interlinked for potential query and knowledge discovery. Foundational linked data principles are :
-Use URIs as names for things
-Use HTTP URIs so that people can look up those names
-When someone looks up a URI, provide useful information, using the standards (RDF for data description, SPARQL for data query)
-Include links to other URIs, so that they can discover more things

Semantics for the REST of us
REST (Representational State Transfer) is the ex-post-defined software architectural style of the Web, a consistent set of principles applied to components, connectors, and data elements within a distributed hypermedia system. These constraints include URI-based resource identification, uniform interface, self-describing messages, hyperlinks providing available application state transitions (HATEOAS) and stateless interactions. REST is currently the defining style of Web of Things APIs, even though many self-declared REST interfaces do not adhere to the full set of REST constraints .
REST interfaces typically operate over HTTP and are constrained to a limited repertoire of generic HTTP verbs ( GET, PUT, POST, DELETE) in lieu of the specific method calls of non-REST APIs. They center on the notion of resource to associate entities of any description with a URI, making it possible to capture and expose relationships to other resources. Behind this least well-observed principle of REST APIs, REST resources descriptions must expose links to all related and relevant resources, so that clients of the APIs are able to discover related resources starting from one entry point in a “follow your nose” kind of way. A program may thus surf the programmable web of REST interfaces just as a curious human user might surf the web of documents, by clicking through hyperlinks. This is meant to ensure the crucial decoupling of applications with the underlying platform, whereby both can best evolve and play their respective roles independently of one another, yet collaboratively. The platform does not require applications to integrate, as traditional APIs would have done, the knowledge of a comprehensive declarative interface description (a kind of “user manual”) which may change over time and require the reprogramming of these applications.
The coming together of REST and Linked Data principles is a crucial alignment that portends the future of open platforms. An elegant, concise and pragmatic standard has appeared right in time to support these powerful and transformative ideas.
The Linked Data lingua franca
JSON-LD (JSON for Linked Data), a 2014 W3C recommendation , is poised to become the universal bridging language for Linked Data. It extends the widely used and well-liked JSON (JavaScript Object Notation) format to add proper semantics and links to existing JSON API payloads. JSON-LD is totally compatible with plain JSON, and developers only need, at the very minimum, to add two additional keywords (@context and @id) in order to use the core capabilities of JSON-LD. “@context” is used to map short-hand names to URIs so as to add semantics to terms used throughout a JSON-LD document; @id is the node identifier which uniquely identifies objects that are being described in the JSON-LD document with URIs (or blank node identifiers).
An example : bridging two Internet of Things platforms
(detailed in the annex linked to this post)
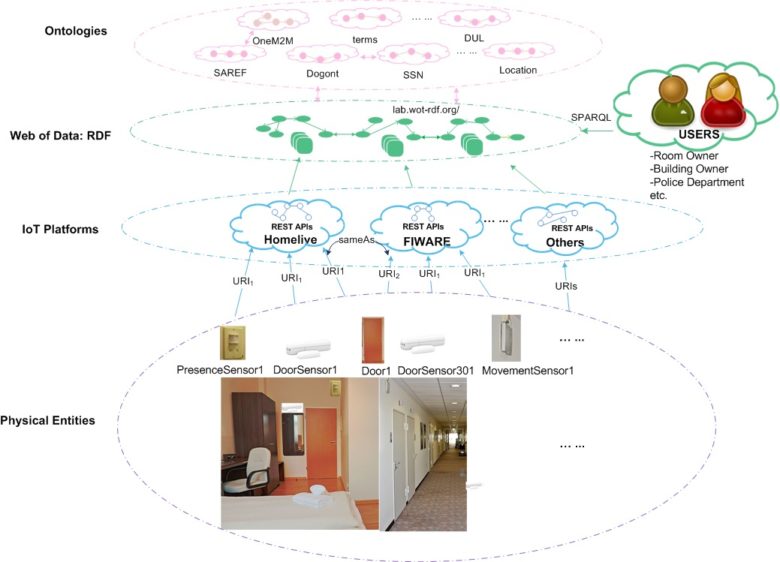
The diagram below summarizes the idea of federating platforms with JSON-LD. Separate IoT platforms are merely assumed to expose REST APIs with JSON payloads for resources descriptions, and through a process of resource discovery, information extraction and semantic annotation, the JSON descriptions of platform resources may be transformed into semantically-rich RDF graphs with semantics tags. Semantic tags are defined by ontologies to provide cross domain interoperability with IoT platforms. Implicit knowledge is then deduced by information inference and the same physical entities described by different IoT platforms may be reconciled. Data from different platforms thus get interlinked through shared semantics and these IoT platforms get federated at the semantic level, as a kind of “meta-platform”.
Conclusion
The extraction of semantically annotated Linked Data to bridge existing IoT infrastructures, as presented here, falls short of the requirements of a full-fledged platform and should not be assessed as such. It is a veneer of interoperability, pragmatically thin in depth but determinedly wide in reach. Its intent is for existing platforms to open up through their existing APIs and share part of their data. It should be seen as an incentive for these platforms to adopt data representations and interfaces that comply with linked data principles, so that they can partake in this new meta-platform that will let network effects come into play at its own level while keeping the benefits of decentralized operation.
En savoir plus :
“Platform Revolution: How Networked Markets Are Transforming the Economy–And How to Make Them Work for You”, Sangeet Paul Choudary, Marshall W. Van Alstyne, Geoffrey G. Parker, W. W. Norton & Company, March 2016
“Matchmakers: The New Economics of Multisided Platforms”, David S. Evans & Richard Schmalensee, Harvard Business Review press, May 2016