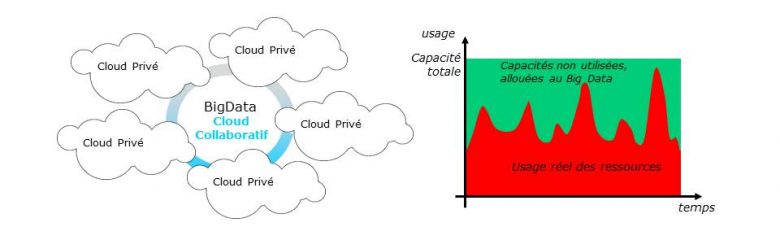
Le cloud public a connu un très fort développement depuis une dizaine d’années, mais les datacenters privés représentent encore près de 70% des investissements en serveurs informatiques et un volume de ressources deux fois plus important. Ceux-ci sont dimensionnés en fonction de leur pic de charge et les infrastructures sont en partie redondantes pour résister à des défaillances matérielles. Il en résulte donc que 50 à 80% des capacités des datacenters privés sont inutilisées à un moment donné. Cela n’est ni optimal d’un point de vue économique, ni vraiment acceptable d’un point de vue écologique lorsque l’on sait que l’industrie électronique est un des premiers pollueurs sur Terre.
Parallèlement, il existe un besoin exponentiel de ressources de calcul pour exécuter des traitements Big Data. Mais investir dans des ressources dédiées est très couteux et l’alternative reposant sur les clouds public leaders du marché (Google, Amazon, Microsoft) ne permet pas de garantir une stricte confidentialité des données, compte tenu, en particulier, de la règlementation américaine (Cloud Act).
L’Airbnb des datacenters privés
Notre solution technique, en cours de développement dans le cadre d’un projet de l’Institut de Recherche technologique b<>com, dont Orange est membre fondateur, s’inscrit dans ce contexte. Elle consiste à proposer une plateforme d’exécution Big Data distribuée s’appuyant sur les ressources informatiques dormantes de multiples datacenters privés.
Dans le cadre du projet actuel, nous avons fait le choix de nous concentrer sur un usage intra-entreprise, en considérant les datacenters d’une même entreprise et des traitements Big Data internes. L’architecture logicielle est néanmoins conçue pour évoluer vers un cloud collaboratif multi-entreprise dans un second temps.
Un défi culturel, technique et opérationnel
La solution doit répondre à différentes exigences, sur lesquelles se concentrent nos travaux de recherche et développement. Le premier défi est culturel : les clouds privés n’ont pas été pensés pour être ouverts. Il nous faut convaincre les exploitants que cela est possible sans risque, quand bien même nous considérerions un modèle intra-entreprise. Nous intégrons des mécanismes de monitoring et de sécurité pour garantir aux fournisseurs de ressources que leurs services internes ne seront pas impactés. Le second défi est technique, et consiste à assurer une bonne qualité de service alors que les ressources sont instables, distribuées et hétérogènes. Pour cela, le projet intègre des travaux amonts sur des mécanismes de prédiction de consommation et sur des algorithmes de placement reposant l’un comme l’autre sur un apprentissage et un monitoring au niveau de chaque serveur de l’infrastructure. L’objectif est d’offrir aux consommateurs une qualité au moins équivalente à ce que l’on peut trouver sur le cloud public, avec la confidentialité des données en plus. Ces travaux ont donné lieu à plusieurs publications scientifiques, dans le cadre d’une thèse portée par l’IRT b<>com .Enfin, le troisième défi est opérationnel : la solution doit être facile à installer et à utiliser, comme le sont les autres produits et services cloud, et elle doit être performante et compétitive d’un point de vue économique, pour être attractive vis-à-vis des offres de cloud-computing public.
Un coût 3 à 4 fois moins important
Pour valider cet intérêt compétitif, nous avons mené une étude économique sur un cas d’usage de type Big Data, en considérant un besoin équivalent à 12 serveurs et 11 To de stockage. Celle-ci n’intègre à ce stade qu’un modèle de coût et nous n’intégrons pas la marge éventuelle des fournisseurs de ressources et de l’opérateur de la solution. Ces résultats montrent que le coût d’exécution sur une telle plateforme pourrait être 3 à 4 fois moins important que sur un cloud privé ou sur une offre de cloud public d’entrée de gamme. Ceci permet d’envisager une tarification attractive pour les consommateurs, tout en permettant de générer des revenus pour les fournisseurs de ressources et pour l’opérateur.
Dans le cadre du projet actuel, nous avons décidé de concentrer nos travaux sur le cas d’usage Big Data et en particulier sur l’applicatif Apache Spark. D’une part parce que les framework Big Data intègrent déjà nativement le support d’infrastructures distribuées et des mécanismes de résilience, et d’autre part parce que nous pensons que c’est dans ce domaine qu’il y a les besoins les plus importants en ressources de calcul.
A ce stade, nous avons développé les services de bases permettant de déployer de manière automatique une solution de cloud collaboratif sur un environnement distribué, et de garantir l’isolation logique entre les différentes applications. Désormais notre objectif consiste à consolider puis intégrer les travaux sur la prédiction et le placement intelligent, en considérant le cas d’usage Big Data.
Nous sommes en phase d’intégration de la solution sur le datacenter de b<>com et prévoyons d’étendre ces tests courant Q2 2020 sur des infrastructures d’Orange, avant d’expérimenter la solution avec des partenaires externes courant S2 2020.
En utilisant cette solution technique, les entreprises ou administration publiques pourraient à la fois rentabiliser leurs infrastructures existantes, et disposer d’une alternative au cloud public, compétitive et souveraine pour leurs besoins dans le domaine du Big Data. Cela serait également l’occasion pour elles de se positionner en tant que moteurs d’une nouvelle économie, collaborative et soucieuse de l’environnement.
Contact: ivan.meriau@orange.com