


Echange et manipulation des jeux de données en entreprise
La corrélation des données permet de découvrir de nouvelles informations sous-exploitées aujourd’hui et susceptibles de faire évoluer de manière importante les pratiques et les services proposés par les entreprises. Ainsi, l’utilisation, la gestion et le partage de gisements de données sont devenus des aspects primordiaux pour la compétitivité des entreprises.
Ces usages des données, auparavant fermées et protégées dans les silos des entreprises et des organisations, amènent toutefois plusieurs problématiques. Imaginons Paul, météorologiste. Il a réuni dans un document de travail un ensemble de données sur une tempête à venir nommée JUPITER. Il pense que ces informations peuvent intéresser d’autres personnes et être partagée au-delà des limites de son projet, de son équipe et même de son entreprise. Pour s’assurer que son document sera trouvé, il doit en préciser le contenu en étant compréhensible par tous, quelles que soient leurs connaissances.
Un premier constat apparaissant ici est que les données libérées découlent de connaissances métiers qui ne sont pas nécessairement possédées par tous les utilisateurs des jeux de données. Ainsi, cet écart de connaissances entre le producteur et le consommateur ne permet pas à ce dernier de comprendre facilement les données (compréhension insuffisante pour déployer des algorithmes de Machine Learning, par exemple). Un second constat est que l’ouverture d’un nombre important de jeu de données complexifie grandement la recherche de données (une tâche à laquelle s’attaque notamment le nouveau moteur de recherche Google Dataset). A l’instar des moteurs de recherche classiques, des efforts d’indexation doivent ainsi être consentis pour permettre aux utilisateurs d’obtenir rapidement les jeux de données pertinents pour répondre à leurs besoins.
De nombreux cas d’utilisations nécessitent de casser les barrières entre des silos de données (corrélation de données contenues dans différents jeux par exemple). Cette tâche est rendue complexe par de multiples formes d’hétérogénéité des données dues aux langues, aux formats ou encore à l’utilisation de terminologies métiers propres à chaque acteur. Ainsi, une même information peut être représentée de manière différente en fonction du format des fichiers de stockage ou du modèle de représentation utilisé (une table de bases de données possédant un champ “telephoneClient” et une autre table possédant un champ “Ctc_TelCli”).
L’ouverture des données à des tiers constitue une évolution importante des usages. Cependant, les entreprises sont encore réticentes quant à ce partage par crainte des risques potentiels (e.g. l’appropriation d’un jeu de données sans accord préalable). Symétriquement, le consommateur attend des garanties quant à la précision, la complétude, la crédibilité et la traçabilité des données. La traçabilité et la crédibilité sont deux concepts directement liés. La traçabilité des données permet au consommateur de connaitre le processus (étapes de modifications successives effectuées par un ou plusieurs contributeurs) ayant permis de produire le jeu de données. Les données de traçabilité sont utiles pour comprendre l’état actuel du jeu de données, valider son origine et le niveau de confiance de chaque contributeur. Cette capacité à évaluer le jeu de données permet au consommateur de déterminer s’il juge le jeu suffisamment crédible pour le contexte dans lequel il souhaite utiliser ses données.
Un modèle de métadonnées pour les décrire tous
Pour répondre à ces besoins, notre équipe a conçu et développé Dataforum, une plate-forme de recherche fournissant un service d’échange de jeux de données. Cette plate-forme permet à un écosystème d’entreprises de décrire, partager et utiliser leurs données d’une manière simple, rapide et en confiance. En particulier, un modèle de description commun des jeux de données répondant à deux objectifs a été introduit : tout d’abord, permettre la description du contenu du jeu de données pour faciliter son appropriation et sa compréhension par l’utilisateur et limiter le besoin d’intervention d’un expert métier ; ensuite, proposer un modèle de métadonnées suffisamment générique pour pouvoir décrire une grande variété de jeux de données et être complété par des descriptions “métier” (santé, biologie, télécommunications, etc.). Une telle description détaillée et homogène facilite la découverte et la recommandation de jeux de données, permettant ainsi d’imaginer de nouveaux cas d’utilisation potentiellement créateurs de valeur.
Par exemple, l’expression de l’assertion “Paris est situé en France” peut se faire sous la forme d’un triplet d’information <sujet, prédicat, objet> dans lequel “Paris” est le sujet, “est situé” est le prédicat et “France” est l’objet. Cette information est alors stockée dans un graphe de connaissances qui structure l’information et réconcilie les sources hétérogènes de données. Le modèle proposé, nommé, sem4ds (de la sémantique pour les datasets) est implémenté à l’aide des langages sémantiques RDF, RDFS et OWL2. Ces langages définissent de manière formelle les concepts et les propriétés permettant de décrire un jeu de données via des “triplets d’informations” lisibles par les humains comme par les programmes informatiques.
Afin que le modèle sem4ds soit capable de présenter le contenu d’un jeu de données mais aussi de préciser l’usage permis (e.g. utiliser le jeu de données avec ou sans la possibilité de le modifier) et de montrer les différentes actions réalisées sur ce jeu de données (e.g. copie, modification), une agrégation de vocabulaires sémantiques, largement utilisés dans la communauté, a été utilisée (DCAT[1], PROV-O[2] et CCREL[3]). Ce modèle a été étendu pour donner des informations précises sur les opérations réalisées sur les jeux de données à la création, lors de modification et la suppression des jeux de données.
Les métadonnées générales décrivent le jeu de données ainsi que ses distributions (fichiers associés à un jeu de données) pour faciliter sa découverte, sa compréhension et son utilisation. Les métadonnées techniques fournissent des informations pour faciliter l’accès et la manipulation du jeu de données : l’emplacement, la taille, le format du document, etc. Enfin les métadonnées de traçabilité renseignent sur les différentes opérations réalisées sur le jeu de données. Le modèle choisi pour fournir des traces d’usage, PROV-O, repose sur trois concepts principaux : l’entité (Entity, le dataset ou la distribution), l’activité (Activity, pour la création, modification, suppression d’une entité) et l’agent (Agent, l’acteur qui a initié l’activité). Il permet de répondre aux questions : “qui fait quoi ?” “pourquoi ?” et “quand le fait-il ?”. La figure suivante montre l’utilisation du modèle PROV-O pour tracer une activité de modification : un technicien de Météo France a modifié la licence d’un jeu de données : le 7er Octobre 2019 à 9h55.
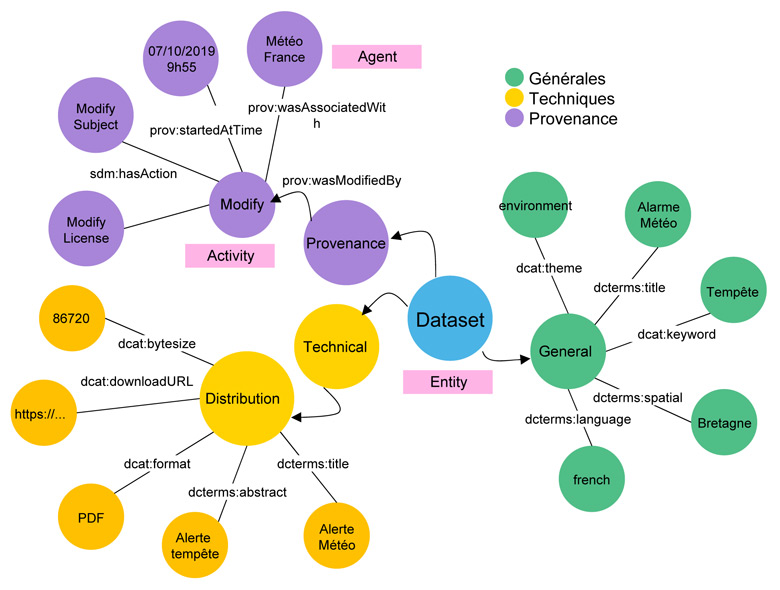
Figure 1 Description détaillée des descripteurs d’un dataset avec les métadonnées techniques, générales et de provenance.
Quel que soit le jeu de données, ce modèle, compréhensible par la machine, permet d’améliorer l’indexation des métadonnées dans une base de connaissances et ainsi faciliter sa découverte grâce à un moteur de recherche spécialisé.
Sémantisation de données, recherche et recommandation
Réaliser une description détaillée d’un jeu de données sous une forme standard à tous les utilisateurs potentiels nécessite une charge de travail accrue pour les producteurs des données afin de documenter correctement les jeux de données. Afin de minimiser leur investissement, Dataforum automatise en partie la description du contenu des jeux de données grâce aux technologies d’apprentissage automatique et de traitement automatique du langage.
Ces outils permettent d’extraire automatiquement certaines métadonnées importantes telles que les thèmes, des mots-clés, la langue, une couverture géographique ou encore le format et la taille des jeux de données. Ces métadonnées sont les concepts du modèle sem4ds. Cette sémantisation est réalisée en deux étapes : tout d’abord sont identifiés le format du document ou jeu de données, et la langue dans laquelle il est rédigé. La seconde étape consiste à extraire les mots clés de la partie textuelle, le thème, la couverture géographique, et des détails sur la structure du jeu de données.
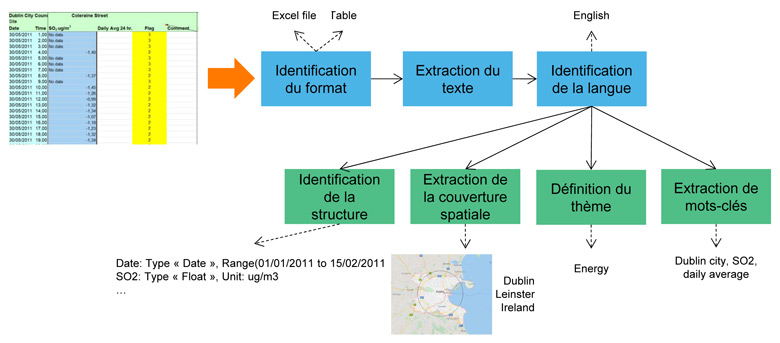
Figure 2 Description automatique d’un jeu de données.
Grâce à l’expressivité du modèle semd4ds, Dataforum propose un moteur de recherche doté de nombreux filtres tels que mots clés, thème, licence, langue, format ou encore, dernière date de modification. Ces filtres correspondent à certaines métadonnées du modèle sémantique sem4ds et permettent de proposer à l’utilisateur une grande variété de critères de recherche et d’améliorer ainsi la pertinence des résultats.
L’ensemble des métadonnées générées lors de la création et des mises à jour d’un jeu de données vient alimenter une base de connaissances. Lorsqu’un utilisateur effectue une recherche, le moteur de recherche va interroger cette base. Pour cela, les critères de recherche sélectionnés par l’utilisateur sont automatiquement traduits en requête SPARQL, un langage d’interrogation de graphes RDF. La requête SPARQL parcourt le graphe global de la base de connaissances à la recherche des jeux de données répondant à la demande de l’utilisateur.
Imaginons que notre utilisateur veuille formuler la requête suivante : “Donne-moi tous les jeux de données en langue anglaise dans le thème de l’environnement et qui contiennent le mot-clé ‘winterstorm’”. La figure ci-dessous fournit une vue partielle de l’interface actuelle du moteur de recherche (partie A). Les jeux de données répondant à la recherche sont alors présentés de façon synthétique et compréhensible grâce aux métadonnées du modèle sem4ds (partie B de la figure ci-dessous).
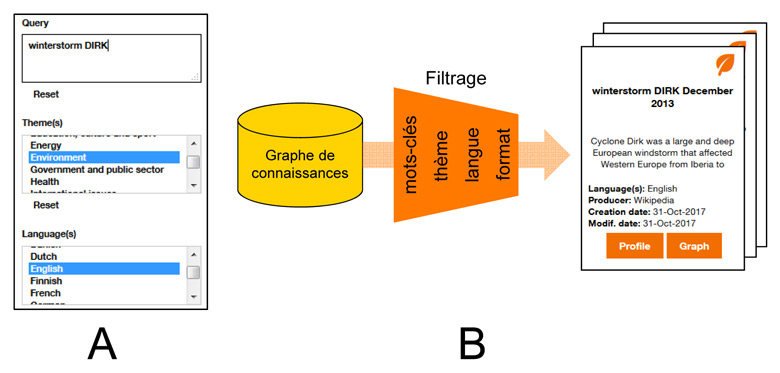
Figure 3 Vue de l’interface du moteur de recherche : les jeux de données répondant à la recherche sont présentés de façon synthétique et compréhensible grâce aux métadonnées du modèle sem4ds.
En complément du moteur de recherche et toujours pour faciliter l’identification des bons jeux de données pour un cas d’usage, Dataforum propose un moteur de recommandation. Soit un utilisateur cherchant des jeux de données sur des tempêtes similaires à JUPITER (celle que Paul, le météorologiste, a partagé sur Dataforum), grâce au moteur de recherche il obtient des documents météo traitant d’une tempête DIRK. Enfin le système de recommandation lui propose un document traitant de DIRK mais sous l’angle de l’économie et non environnemental. L’objectif est ainsi de favoriser la découverte de nouveaux jeux de données en se basant sur ceux que l’utilisateur a utilisés. Les résultats de recommandation sont présentés sous la forme d’un graphe qui regroupe dans un même espace les jeux de données qui ont des thèmes et des mots clés similaires. Cet affichage permet à la fois de donner un aperçu d’un grand ensemble de jeux de données et de consulter les jeux de données suggérés de proche en proche. La similarité des jeux de données est calculée en fonction du contenu de ces derniers et opérée par le moteur Reperio (Orange Labs).
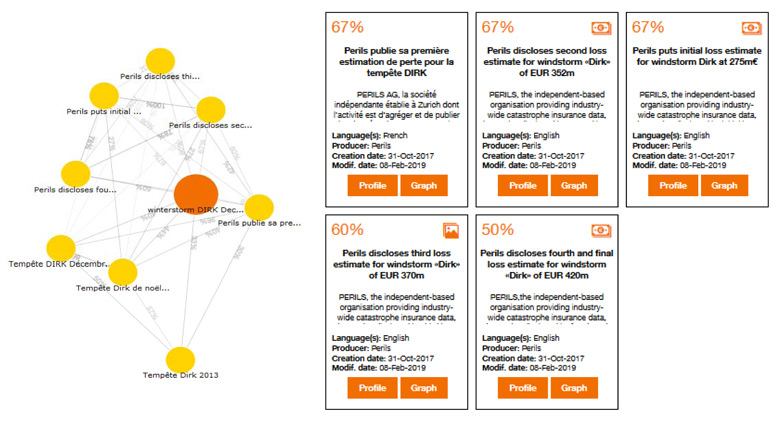
Figure 4 Graphe de similarité (proximité d’un jeu de données avec d’autres jeux de données) à gauche et vue “carte” à droite
Conclusion
Grâce à semd4ds, langage commun de description de jeux de données, les entreprises peuvent partager simplement, rapidement et en toute confiance des jeux de données. Elles peuvent aussi préciser dans le détail ce qu’elles cherchent puisque les métadonnées de jeux de données contenues dans sem4ds constituent les filtres du moteur de recherche. Enfin un système de recommandation est capable de proposer des jeux de données ayant des métadonnées communes avec un jeu de donnée d’origine. Ainsi quelle que soient les différences entre plusieurs organisations, grâce à Dataforum, il existe un moyen unique et optimal de décrire et partager les données.

Dataforum est le fruit d’une innovation intégrative conduite par une équipe de dix personnes, dans les laboratoires d’Orange Labs à Belfort, Lannion et Sophia Antipolis, spécialisés en Web Sémantique, Traitement Automatique de la Langue et Intelligence Artificielle ainsi qu’une équipe de développeurs.
Cette plate-forme développée depuis 2017 a maintenant le niveau de qualité nécessaire pour être utilisée dans un contexte opérationnel. Ses principales fonctions sont actuellement transférées pour fournir une plateforme d’échange de données qui sera utilisée par des services d’Orange pour leurs besoins internes. Des améliorations seront fournies en 2020. En particulier, des travaux de recherche sur la caractérisation automatique de données tabulaires sont en cours. L’objectif est ici d’annoter à l’aide de concepts sémantiques les entités composant un tableau (cellule, ligne, colonne et relations intra et inter-colonnes) afin de permettre l’interrogation sémantique (et non plus syntaxique) du graphe de connaissances. Un autre effort de recherche porte sur l’utilisation du service Dataforum par commande vocale. Un fournisseur aura ainsi la possibilité de décrire le jeu de données qu’il publie manuellement ou oralement. Ceci permettra de compléter d’une manière plus souple la description du jeu de données réalisée par la chaîne de sémantisation. Les utilisateurs pourront, quant à eux, exprimer leurs requêtes oralement offrant ainsi une plus grande facilité d’usage. Un système de reconnaissance vocale traduira les différentes demandes dans un format textuel qui sera alors utilisé soit pour enrichir la base de connaissances soit pour construire une requête avec la syntaxe adaptée. Une dernière amélioration est de fournir une architecture totalement distribuée, en offrant la possibilité à chaque entreprise de préciser avec qui elle veut échanger dans l’écosystème et de pouvoir modifier cette configuration de manière dynamique en fonction de ses objectifs du moment.
[1] Data Catalog Vocabulary (DCAT)
[2] PROV-O: The PROV Ontology
[3] ccREL: The Creative Commons Rights Expression Language
Pour aller plus loin :
- Le sens du sens : les ontologies, ce n’est pas (que) de la philosophie !
- Chabot, P. Grohan, G. Le Calvez, and C. Tarnec, “Dataforum: Faciliter l’échange, la découverte et la valorisation des données à l’aide de technologies sémantiques”, EGC 2019 : Extraction et gestion des connaissances, 2019.
- Halevy et al., “Goods: Organizing Google’s Datasets”, Proceedings of the 2016 International Conference on Management of Data – SIGMOD ’16, 2016, pp. 795–806.
 Yoan Chabot
Yoan Chabot







