


Summary
Thing’in, a research platform initiated by Orange, reaches beyond classic Internet of Things platforms like Live Objects. Unlike these platforms, Thing’in does not store & forward raw data from IoT connected devices, but maintains a thorough structural and semantic description of the environments, such as cities or buildings, into which these objects fit. This description is based on a graph, similar to a social network, whose nodes are, in place of people, objects (not necessarily connected), physical entities and systems of all kinds that make up these environments. Thing’in makes it possible for different and so-far-vertically-integrated IoT applications in these environments to locate and share their data sources on the basis of the information stored in the Thing’in graph, much as a search engine does for the Web. Thing’in is based on a high-level information model (NGSI-LD, now standardized by ETSI), geared to its comprehensive value-added graph store, but supports import and export of open data in standard “linked data” formats.
Full Article
Could gRaph theory replace aRithmetic as one of the “three Rs” to be mastered by schoolchildren? As much as they may hate long division, they should love graphs, which they cruise every day, as do billions of social networks users! From pupils to engineers and scientists, could we go so far as to claim that graphs are poised to become the universal mathematical lingo of our networks & information age, just as calculus used to be in the early modern era🤔? Social graphs have opened up one more alluring new realm of applications for this venerable and bountiful theory, which, incubated in the rarefied confines of pure mathematics, had long since inseminated many diverse fields of science and engineering.
Like social networks, Thing’in, an integrative research platform initiated by Orange, revolves around a graph. The nodes of this graph do not stand for people, but for physical entities of all kinds, and the arcs of the graph capture relationships between each of these entities and their environment, as they make up cyber-physical systems at multiple levels of integration and scales.
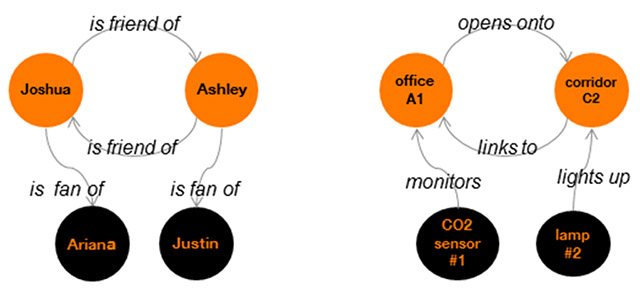
Figure 1 Comparing a social graph to a things’ graph
Social networks have also, among many others, raised to public awareness the notion of “multi-sided platform“. Like numerous forerunners, the Thing’in platform mediates information between multiple categories of users (the “sides” of the platform), feeding information to and from the graph that sits at its core, in a self-multiplying process. Developers of IoT applications are the users obtaining higher-level information from the northbound (upper) side of the platform, while low-level data gets fed to the southbound side of the platform from various data repositories or lower-level IoT platforms that Thing’in is meant to federate, in a way that we will elicit further.
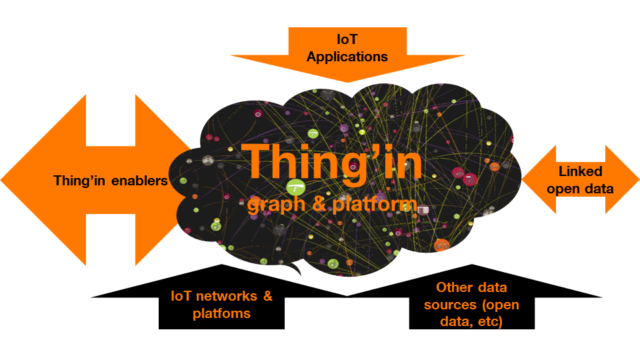
Figure 2 : Thing’in as a multi-sided platform
Beyond POIT (Plain Old Internet of Things)
The Internet of Things and, in its earlier incarnations, M2M, have primarily sought to open up traditional telecom networks to a very narrow range of “things”, in fact only newish devices promoted to the status of “connected devices” by becoming direct network end-points.
In our analogy with social networks, this would correspond a network maintaining profiles, not of people themselves, but exclusively of the smartphones or PCs they use to connect to the network : only the most dyed-in-the-wool gearheads would fancy this! Everyone else does, as a rule, ignore which means of connection are used by the users or nodes of these networks, which can even be events, movies or historical characters not equipped with smartphones!
Building upon a vision expounded in previous publications, Thing’in does also extend much further than those connected devices of the legacy IoT/M2M, to integrate all kinds of things and physical entities that may be monitored or actuated by these devices: these things are the primitive nodes of the graph, with devices serving them only as intermediaries, just as the smartphones of social network users.
What’s this graph about?
System-level structure, first and foremost!
The Thing’in graph is, crucially, not a connectivity graph in the sense of telecom networks. The primitive nodes of the graph make up a structural description of an environment, viewed as a system described by relationships between its components or subsystems. In the building examples shown below, the main nodes of the graph may be the rooms, or supersets of them as floors, and these rooms do in turn contain objects of all kinds such as doors, tables and applicances. The relationships between these objects are represented by arcs of the graph. The types of these arcs, such as “is_contained_in”, “is_subsystem_of” or “is_adjacent_to” define their nature. Devices in the IoT sense (networked sensors and actuators) are of course also represented in the graph, as shown in figure 3 and the associated demo on the Thing’in platform. They can be associated (via relationships) with entities to which they bring a presence on the network, in a way similar to how a smartphone brings connectivity to a member of a social network. In the first example below, a connected temperature sensor and a connected lamp are respectively sensors and actuators associated with an office room. These relationships do also make it possible to distinguish between two types of system composition : top-down system composition, associates e.g. walls or doors to a room as its inherent susbsystems, whereas bottom-down composition refers to objects like chairs or tables that are contingently contained in the room, as shown in figure 4 below.
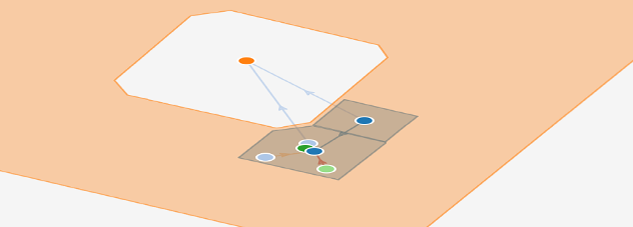
Figure 3 Building subgraph example with connected devices
(with link to actual implementation on the Thing’in platform)
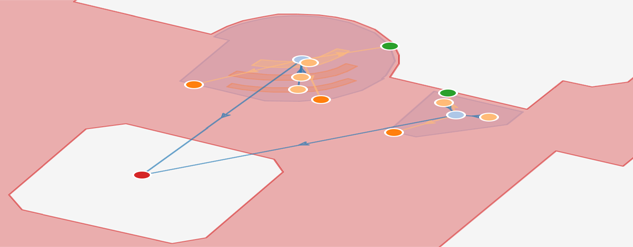
Figure 4 Building subgraph example with non-connected objects
(with link to actual implementation on the Thing’in platform)
These diagrams provide two examples of the graph mapped onto a building florplan, represented in perspective, with the nodes corresponding to two rooms in their environment, and the associated entities. Click the images to access a direct visualization of the corresponding graph from the platform Thing’in: hovering over the nodes and the arcs shows their identity and a right click makes it possible to obtain all the detailed information stored in the database.
Semantics, the icing on the (multi-tiered) system cake!
In the Thing’in graph, we can say that structure, in the sense of a description of multi-level and multi-scale system composition, precedes semantics.
The Thing’in graph is not only a knowledge base, in the sense of e.g. the vaunted Google “Knowledge Graph“. It is also quite distinct in its principle from graphs based on the RDF meta-model, which boil down all kinds of data to logical predicates viewed as “atoms of knowledge”. An RDF graph has only one type of arc,
corresponding to a predicate in the sense of first-order logic
By contrast, Thing’in is based on a more expressive meta-model,
better suited to the representation of multi-structured multi-level information
that is not easily reducible to first-order logical predicates. This meta-model, called “property graphs“, is the common denominator between most graph databases. Property graphs make a cogent distinction between relationships linking the primary nodes of the graph, and properties that can be associated with these nodes as key-value pairs, but also to its relations, or recursively to properties themselves (which from a theoretical standpoint, corresponds to second-order logic). Contrary to relationships, the targets of properties can only be numbers or character strings (literals in the customary sense of RDF, and programming), they cannot be entities identified as primary nodes of the graph. Properties may serve to describe both instantaneous states of the corresponding entity (e.g. the average temperature, luminosity, or occupation of a room) and permanent characteristics (e.g. the
area or the destination of a room).
Semantics in the Thing’in graph is construed as referential semantics, whereby the nodes of the graph stand for some physical entity that exists out there in the real world, and this referent physical thing is itself mapped to an ontology that categorizes this thing within its own domain (e.g. furniture, electrical appliances, etc.). The mapping between the Thing’in graph nodes (instances/individuals) and ontology classes is always implicitly by way of the referent, but this indirection could be overlooked for the graph node (representation or avatar of the physical thing) to be considered as an intantiation of the corresponding ontological class in the same way as an OOP language class gets instantiated into an object, or a type into a variable. There is, however, a huge difference between the “open-world” modeling approach supported by graphs and the more rigid “closed-world” modeling of relational databases or OOP : the property graph model does not require all potential attributes (properties or relationships) of a class instance to be set in stone in the corresponding class definition. A major consequence is that existing generic classes need not and should not be customized or subdivided at will to create all kinds of newish variations to fit specific applications, environments, or commercial makes. Classes have to be drawn, as much as possible, from well-publicized and widely shared ontologies or vocabularies, even if they are perceived as overly generic, because multiple typing or the addition of adequate relationships or properties obviates the need to create ad hoc types or classes. To take a simple and typical example, let us suppose we need to characterize an IoT-style connected light bulb for which the color temperature can be adjusted from a smartphone app. We should not and need not create a new fancy class defining a “Color-temperature-actuated-light-bulb” for this! We have every right to categorize our smart light bulb as an instance of a generic legacy light bulb class, because its main function is still to convert electrical energy to light! To characterize this instance completely, we only need to add a “has_subsystem” relationship from our light bulb to an instance of a generic networked actuator class, which in turn will have a “controls” relationship to the color_temperature” property of the lightbulb and another “is_controlled_by” relationship from a proper instance of smarpthone app.
Semantic modeling is, understood this way, intended to support automatic configuration and interoperation in open environments. Contrary again to traditional database schemata or OO class models, a semantic model is not a skeleton or a prop upon which upon which to flesh out a complete description of the environment being modeled : the graph structure is self-standing, even if devoid of any semantic referencing! Semantic modeling should thus not be understood as an upfront one-shot a priori process, but as the a posteriori result of an incremental and iterative processin which the graph structure generates its own semantics. This is actually something for which the web graph and social networks graphs have been used since quite a long time!. Social network users do not explicitly assign themselves to known categories for e.g. political leanings or musical tastes, yet knowing the structure of their graph neighborhood (i.e. the persons they link to and events they like) allows social network operators to accurately surmise this information, and to use it lucratively, as we know …In a way that is less worrysome for individual privacy, the Thing’in graph could, in our previous smart bulb example, make it possible automatically assign it to the “connected device” class on acount of its relationships alone. In the example from figure 4, we can automatically differentiate a node corresponding to a meeting room from a node corresponding to an office room on account of links with the chair and table nodes they contain, even if the corresponding semantic categories
of these rooms had not been provided upfront when they were instantiated in the database.
What’s this graph for?
Thing’in will play a complementary role to that of Internet of Things platforms like FIWARE or DataVenue. These platforms act as transit points where data coming from IoT sensor networks are concentrated, stored, and (for some platforms like FIWARE) consolidated and abstracted away before being forwarded to the applications that use them. Thing’in is not meant to store this kind of raw data, but
only structural and semantic information characterizing the configuration
of the environment from which these data are derived. This means Thing’in would preferably be used for the initial configuration or on-the-fly reconfiguration of an application, to establish bindings to relevant data sources from the information stored in the Thing’in graph, which allows to zero in on these sources from high-level queries assuming no prior “out-of-band” knowledge of the environment being queried.
Thing’in may also import and export data to and from its own graph as linked datadatasets, taking charge of the required back and forth conversion between the property graph and RDF models for this. Even if Thing’in is already positioned as a federative data mediation platform, it can be seen, in this perspective, as part of the linked data cloud, abiding by this ultimate veneer of interoperablity.
More info
Portal of the Thing’in platform
Introduction to multi-sided platforms, by Andrew McAfee & Erik Brynjolfsson :





