


Summary
Orange is developing and assessing the acceptability of solutions, which will make it possible to determine a user’s personality and mood from their digital footprint. This intimate knowledge could enable Orange to highly fine-tune its services, offering its customers a more sensitive experience that is truly personalised. However, these works do pose many ethical questions: a user’s personality and emotional state being so intimate, obtaining their consent as required by GDPR (General Data Protection Regulation) will not suffice. For each service offered, it will be necessary to question the need to gather this information or not. Solutions enabling the determination of an individual’s personality, but also their mood, have already been integrated into the Home’in the Future platform that is supporting the work on the “sensitive home”.
Full Article
“The appearance of computers during the years 1940-1950, seems to make the dream of artificial intelligence possible,”1 writes Frédéric Fürst, lecturer at Université de Picardie Jules Verne (Modelling, Information and Systems Laboratory). Originally, the idea was to create machines that think in an unemotional way; this also seemed to be an advantage for enabling a rationality that humans do not always demonstrate in their decision-making processes. However, it became apparent that human-machine interaction required a certain consideration of emotion in order to improve the communication between user and machine. The main motivation is the ability to simulate empathy, to adapt the machine’s behaviour to give answers or propose appropriate solutions, taking into account the user’s emotions. According to Yann Le Cun, researcher in artificial intelligence and computer vision, “it is clear that intelligent, autonomous, machines will have emotions […]. There is no doubt: emotion is an essential part of intelligence2.
In the context of its Research Domain “Personal digital life”3, Orange is developing and evaluating the acceptability of solutions for determining the personality and mood of a user from their digital footprint. This intimate knowledge could enable Orange to fine-tune its services in order to provide its customers with a more sensitive, truly personalised, experience. This work raises a number of ethical questions: as the personality and emotional state of a user are private matters, obtaining their informed consent as required by the GDPR (General Data Protection Regulation) will not be enough. Each department will have to reflect upon whether or not this information should be collected, and to evaluate the benefit for the user and for society. Beyond that, we need to consider the risks, limitations and potential distortions.
Determining an individual’s personality
The Big Five model (also known as the OCEAN model), empirically proposed by American psychologist Lewis R. Goldberg4 in 1981, and later developed by Paul T. Costa and Robert R. McCrae from 1987-1992, provides a description of an individual’s personality. In this model, personality is evaluated according to the following five core dimensions:
- Openness to experience, which describes tolerance to what is new and unknown (for example, an individual’s willingness to try new things or to put themselves in a position of vulnerability, their ability to think in an original way);
- Conscientiousness, which concerns intolerance of chaos and disorder. The more organised an individual is, and the less they accept a lack of order, the higher their level of conscientiousness;
- Extraversion, which describes an individual’s tolerance to numerous stimuli. The less an individual tolerates stimuli, the more introverted they are. The more stressed they are by crowds, the more introverted they are;
- Agreeableness, which is reflected in the desire for cooperation and social harmony. For example, the more an individual is focused on the needs and feelings of others, the higher their level of agreeableness;
- Neuroticism, which describes an individual’s intolerance of stress. The less tolerant of stress an individual is, the higher their level of neuroticism.
Figure 1: The five core personality traits of the Big Five model.
Orange proposes a solution that can evaluate an individual’s core personality dimensions using the Big Five model. Each of these dimensions is evaluated separately, on a scale between -5 and +5. For example, openness will be rated between -5 and +5, depending on the person’s tolerance to what is new and unknown.
This solution uses certain digital traces generated by an individual (with the individual’s consent) such as traces generated on a mobile phone (call log, SMS messages, list of installed apps, etc.) and traces generated on social networks (messages and photos published, etc.).
Several algorithms that exploit these data sources have been integrated:
- An algorithm proposed by MIT5, which uses data from call logs and SMS messages. This algorithm is based on several indicators relating to basic use of the phone (e.g. number of calls, number of SMS messages), active user behaviour (e.g. number of calls made, response time to an SMS), frequency (e.g. average time between two calls or two SMS messages), diversity (e.g. number of contacts, entropy of contacts) – this algorithm has been tested by MIT on 69 users;
- An algorithm proposed by ETH Zurich6 using the list of apps installed on a mobile and those most used by the user. The model proposed (machine learning) uses application classification (social networks, games, music, finance, etc.) – this algorithm has been tested by ETH Zurich on 2,043 users;
- An algorithm developed by the University of Pennsylvania and the University of Cambridge7 in the field of language analysis, proposing a correlation between comments published on social networks (Facebook) and the personality traits of their authors – this algorithm has been tested on several million Facebook comments posted by 69,792 users.
Other algorithms, exploiting other digital traces (e.g. photos published on social networks) could enhance this process.
This multiplicity of data sources allows a better understanding of an individual’s personality, with each of these sources able to provide particular insight into the personality traits of the individual that produced them. For example, certain data may have been generated in the context of personal use, while others will have been created in the context of professional use. Furthermore, for a given individual, each of these data sources is developed to a greater or lesser extent. For example, for a teenager making and receiving few voice calls, the call log is a relatively poor data source, which is therefore not usable. However, if the same teenager is very active on certain social networks (many comments and photos published), these networks will be a particularly interesting source of data to be exploited. A personality profile is generated from each of the data sources used and an overall personality profile is then created.
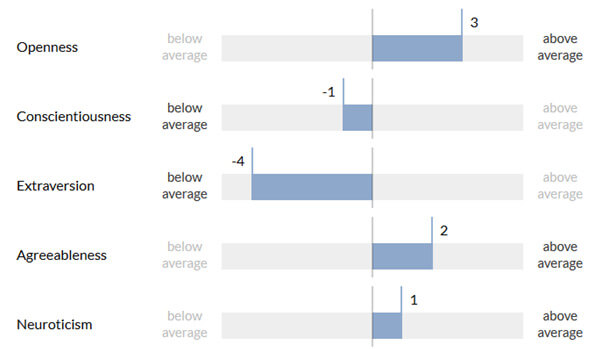
Figure 2: An individual’s five core personality traits, evaluated by exploiting their digital traces.
An experiment targeting 1,000 users (voluntary employees from Orange Poland) is in progress. On the one hand, each participant responds to an online questionnaire allowing them to define their personality according to the Big Five model (the questionnaire having been validated). On the other hand, an application installed on the mobile phone of each participant collects the personal data required to feed the various algorithms used by the proposed solution and attempts to determine their personality.
This experiment enables comparison of the results obtained using different data sources and the various available algorithms (for example, identifying which data sources and which algorithms are most relevant when determining each of the five personality traits).
Determining an individual’s mood
Feeling analysis is an extremely active research area in automatic language processing. Over recent years there has been an increase in the volume of increasingly informal online exchanges, particularly on social networks. These exchanges contain textual data that carries sentiment; the use of emoticons is a good illustration of this. In our research, feeling analysis is carried out within the context of the so-called ‘smart home’. The feelings of family members could, for example, be detected from short messages that they share with their relatives.
More specifically, a model based on machine learning makes it possible to estimate the polarity of a message (positive, negative or neutral). Despite major advances in the field of feeling analysis, the task remains difficult. Feeling analysis is domain dependent; a person is not going to use the same words to give an opinion about a restaurant (for example: “Very average ambience and bland food”) as they would to criticise a film (for example: “DISTRESSING! Depressing, disappointing and gloomy. The actors gave it their all, but this was mission impossible”). In addition to words, emoticons (widely used on social media) can be used to improve feeling analysis. As such, the selection of learning data is crucial when forming a model. In the learning phase, based on examples of representative text, a model has learned to categorise text as positive, negative or neutral. Short texts from social media platforms such as Twitter and text from comments on Orange products have been used for this learning.
The first step in the machine learning of a text classifier involves transforming the text into a numerical representation, usually a vector. A classic bag-of-words text representation model was used. This representation model was enriched by a lexicon of polarised words, with positive or negative polarity attributed to each term. As such, each vector component represents the frequency of the polarised word. The model used also takes smileys and emojis into account. It was performed using Khiops, an Orange Data Mining tool, based on a classification method that applies the naive Bayes hypothesis8
The model used has been tested on 130,000 comments written by Orange application customers. The accuracy of the model is 0.7; this means that 7 out of 10 predictions are correct.
This feeling analysis model is usable via an API, called Sentimeter, which is deployed on DevOps infrastructure to facilitate updating the model.
Integrated solutions on the Home in the Future platform
These solutions for determining an individual’s personality – which is relatively stable over time – and an individual’s mood – which is, on the contrary, highly changeable – are already integrated in the Integrative Research Platform Home in the Future (which supports the work related to the ‘smart home’ project). In the target architecture, data relating to the personality and mood of users is stored and exploited within the home.
These solutions will now be used within the Orange Group for developing service prototypes, arranging new tests (such as solution acceptability tests) and organising experiments (validation with a greater number of users), etc.
Ultimately, these solutions could allow Orange to adapt service behaviour in line with the emotional state of users, in order to provide its customers with a more sensitive and relevant experience. Home voice assistant customisation, interface personalisation, content recommendation… there are many home application fields! For example, imagine a voice assistant capable of automatically adapting to our personality and emotions… Voice assistants currently interact with users in the same way regardless of their personality or mood. It remains to be seen whether it is an “open” user to whom the voice assistant will suggest content far removed from their usual interests or, on the contrary, a less “open” user, in order to avoid the polarisation of ideas denounced by Kiran Garimella9, currently Post-Doc at MIT (Institute for Data, Society and Systems). Going further still, the home assistant could also take on a personality or display emotions, for example by using a more playful voice to interact with the user when he or she is in a good mood, or even adding a touch of humour… By anthropomorphising the interactions, by mimicking our emotional codes, using the voice assistant could perhaps become a more natural, more user-friendly experience. But what about innate attachment, social cooling, possible manipulation? These “sensitive” behaviours must, as we see it, be subject to rigorous ethical questioning; this is the responsibility of Orange and the work on this subject is just beginning.

Thanks to our technologies, a voice assistant could adapt to the personality and mood of its users.
Find out more:
[1] – Aux origines de l’intelligence artificielle [At the origins of artificial intelligence], L. Verbeke (2018)
www.franceculture.fr/numerique/aux-origines-de-lintelligence-artificielle
[2] – La Plus Belle Histoire de l’intelligence [The Most Beautiful History of Intelligence], S. Dehaene, Y. Le Cun, J. Girardon (2018)
[3] – Research area “Personal digital life”: https://hellofuture.orange.com/fr/blog-de-la-recherche/vie-personnelle-numerique/
[4] – An alternative “description of personality”: The Big-Five factor structure. Journal of Personality and Social Psychology, Lewis R. Goldberg (1990)
[5] – Predicting Personality Using Novel Mobile Phone-Based Metrics, Y-E de Montjoye, J. Quoidbach, F. Robic, A. Pentland; MIT, Harvard University, Ecole Normale Supérieure de Lyon (2013)
[6] – Understanding the impact of personality traits on mobile app adoption – Insights from a large-scale field study, R.Xu, R. M. Frey, E. Fleisch, A. Ilic; ETH Zurich (2016)
[7] – The Online Social Self: An Open Vocabulary Approach to Personality, M.L. Kern, J.C Eichstaedt, H.A Schwartz, L. Dziurzynski, L.H. Ungar, D.J Stillwel, M. Kosinski, S.M. Ramones, M.E.P. Seligman; University of Pennsylvania, University of Cambridge (2013)
[8] – Khiops : outil d’apprentissage supervisé automatique pour la fouille de grandes bases de données multi-tables [Khiops: an automated supervised learning tool for searching large multi-table databases], M. Boullé; InActes de EGC 2016 (Extraction et Gestion des Connaissances), Reims (2016)
[9] – Polarization on Social Media, K. Garimella; Aalto University, Finland (2018); https://aaltodoc.aalto.fi/handle/123456789/29708







