


Résumé
Orange développe et évalue l’acceptabilité de solutions permettant de déterminer la personnalité et l’humeur d’un utilisateur à partir de ses traces numériques. Cette connaissance intime pourrait permettre à Orange d’adapter très finement ses services, d’offrir à ses clients une expérience plus sensible, vraiment personnalisée. Mais ces travaux posent de nombreuses questions éthiques : la personnalité et l’état affectif de l’utilisateur touchant à son intimité, recueillir son consentement comme l’impose le RGPD (Règlement général sur la protection des données) ne suffira pas. Il faudra, pour chaque service, s’interroger sur l’intérêt ou non de capter ces informations. Des solutions permettant de déterminer la personnalité d’un individu, mais aussi son humeur, ont d’ores et déjà été intégrées dans la plateforme Home’in the Future, qui soutient les travaux concernant la « maison sensible ».
Article complet
“L’apparition des ordinateurs, dans les années 1940-1950, semble rendre possible le rêve de l’intelligence artificielle”1 écrit Frédéric Fürst, Maître de Conférence à l’Université de Picardie Jules Verne (Laboratoire Modélisation, Information et Système). A l’origine, il s’agissait de créer des machines qui pensent mais dépourvues d’émotions ; cela semblait d’ailleurs un avantage pour permettre une rationalité dont l’homme ne fait pas toujours preuve dans ses processus de décision. Mais il est apparu que l’interaction homme-machine demandait une certaine prise en compte des émotions afin d’améliorer notamment la communication entre l’utilisateur et la machine. La principale motivation est la capacité de simuler l’empathie, d’adapter les comportements de la machine pour donner des réponses ou proposer des solutions appropriées tenant compte des émotions de l’utilisateur. Selon Yann Le Cun, Chercheur en intelligence artificielle et vision artificielle, “il est clair que des machines intelligentes, autonomes, auront des émotions […]. Ça ne fait aucun doute : les émotions sont nécessaires à l’intelligence”2.
Dans le cadre de son Domaine de Recherche “Vie personnelle numérique”3, Orange développe et évalue l’acceptabilité de solutions permettant de déterminer la personnalité et l’humeur d’un utilisateur à partir de ses traces numériques. Cette connaissance intime pourrait permettre à Orange d’adapter très finement ses services, d’offrir à ses clients une expérience plus sensible, vraiment personnalisée. Ces travaux posent de nombreuses questions éthiques : la personnalité et l’état affectif de l’utilisateur touchant à son intimité, recueillir son consentement avisé comme l’impose la RGPD (Règlement Général sur la Protection des Données) ne suffiront pas. Il faudra, pour chaque service, s’interroger sur l’intérêt ou non de capter ces informations, évaluer la plus-value pour l’utilisateur ainsi que pour la société. Au-delà, il faudra réfléchir aux risques, aux limites, aux détournements possibles.
Déterminer la personnalité d’un individu
Le modèle des « Big Five » (aussi appelé modèle « OCEAN »), empiriquement proposé par le psychologue américain Lewis R. Goldberg4 en 1981 puis développés par Paul T. Costa et Robert R. McCrae dans les années 1987-1992, permet de décrire la personnalité d’un individu. Dans ce modèle, la personnalité est évaluée selon les cinq traits centraux suivants :
- L’Ouverture à l’expérience, qui décrit la tolérance à ce qui est nouveau et inconnu (par exemple, la volonté d’un individu d’essayer de nouvelles choses ou de se mettre en situation de vulnérabilité, sa capacité à penser de façon originale) ;
- La Conscienciosité, qui concerne l’intolérance au chaos et au désordre. Plus un individu est organisé et moins il accepte le manque d’ordre, plus sa consciensiosité est forte ;
- L’Extraversion, qui décrit la tolérance d’un individu à de nombreux stimuli. Moins un individu tolère les stimuli, plus il est introverti. Plus la foule le stresse, plus il est introverti ;
- L’Agréabilité, qui transparaît dans le désir de coopération et d’harmonie sociale. Par exemple, plus un individu est focalisé sur les besoins et les sentiments des autres, plus son agréabilité est forte ;
- Le Neuroticisme (ou Névrosisme), qui décrit l’intolérance d’un individu au stress. Moins un individu est tolérant au stress, plus son neuroticisme est fort.
Figure 1 : les cinq traits centraux de personnalité du modèle des « Big Five ».
Orange propose une solution capable d’évaluer les cinq traits de personnalité du modèle des « Big Five » d’un individu. Chacun de ces traits est évalué séparément, sur une échelle comprise entre -5 et +5. Par exemple, l’ouverture sera évaluée entre -5 et +5, selon la tolérance de la personne à ce qui est nouveau et inconnu.
Cette solution exploite certaines traces numériques générées par l’individu (après le consentement de celui-ci) telles que les traces générées sur le téléphone mobile (journal des appels et des messages SMS, liste des applications installées, etc.) et les traces générées sur les réseaux sociaux (messages et photos publiées, etc.).
Plusieurs algorithmes exploitant ces sources de données ont été intégrés :
- Un algorithme proposé par le MIT5 exploitant des données présentes dans le journal des appels et des messages SMS. Cet algorithme repose sur plusieurs indicateurs relatifs aux usages de base du téléphone (ex. nombre d’appels, nombre de SMS), aux comportements actifs de l’utilisateur (ex. nombres d’appels initiés, temps de réponse à un SMS), à la fréquence (ex. temps moyen entre deux appels, entre deux SMS), à la diversité (ex. nombre de contacts, entropie des contacts) – cet algorithme a été testé par le MIT auprès de 69 utilisateurs ;
- Un algorithme proposé par l’ETH Zurich6 utilisant la liste des applications installées sur le mobile et les plus utilisées par l’utilisateur. Le modèle proposé (machine learning) utilise une classification des applications (social, jeu, musique, finance, etc.) – cet algorithme a été testé par l’ETH Zurich auprès de 2.043 utilisateurs ;
- Un algorithme développé par les universités University of Pennsylvania et University of Cambridge7 dans le domaine de l’analyse du langage et proposant une corrélation entre des commentaires publiés sur les réseaux sociaux (Facebook) et les traits de personnalité de leurs auteurs – cet algorithme a été testé sur plusieurs millions de commentaires Facebook provenant de 69.792 utilisateurs.
D’autres algorithmes, exploitant d’autres traces numériques (par exemple des photos publiées sur des réseaux sociaux) pourraient enrichir cette démarche.
Cette multiplicité des sources de données permet de mieux cerner la personnalité d’un individu, chacune de ces sources pouvant apporter un éclairage particulier sur les traits de personnalité de l’individu qui les a produites. Par exemple, certaines données peuvent avoir été générées dans le cadre d’un usage personnel alors que d’autres l’auront été dans le cadre d’un usage professionnel. Par ailleurs, pour un individu donné, chacune de ces sources de données est plus ou moins riche. Par exemple, pour un adolescent émettant et recevant peu d’appels vocaux, le journal des appels est une source de données relativement pauvre, donc peu exploitable ; en revanche si ce même adolescent est très actif sur certains réseaux sociaux (nombreux commentaires et photos publiés), ceux-ci constitueront une source de données particulièrement intéressante à exploiter. Un profil de personnalité est généré à partir de chacune des sources de données exploitées ; un profil de personnalité global est ensuite établi.
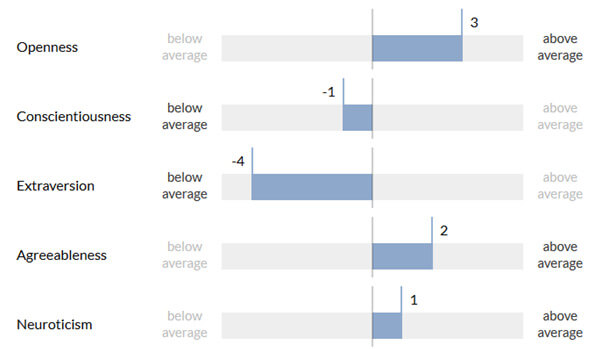
Figure 2 : les cinq traits centraux de personnalité d’un individu, évalués grâce à l’exploitation de certaines de ses traces numériques.
Une expérimentation ciblant 1.000 utilisateurs (salariés volontaires d’Orange Pologne) est en cours. D’une part, chaque participant répond à un questionnaire en ligne permettant de définir sa personnalité selon le modèles des “Big Five” (questionnaire ayant été validé par ailleurs). D’autre part, une application installée sur le téléphone mobile de chaque participant permet de recueillir les données personnelles nécessaires pour alimenter les différents algorithmes de la solution proposée et tenter de déterminer ainsi leur personnalité.
Cette expérimentation permettra notamment de comparer les résultats obtenus selon différentes sources de données et différents algorithmes disponibles (par exemple, identifier quelles sources de données et quels algorithmes sont les plus pertinents pour déterminer chacun des cinq traits de personnalité).
Déterminer l’humeur d’un individu
L’analyse des sentiments est un domaine de recherche extrêmement actif en traitement automatique des langues. En effet, ces dernières années, les échanges, de moins en moins formels, se sont accrus sur internet, notamment sur les réseaux sociaux. Ces échanges contiennent des données textuelles porteuses d’opinions ; l’usage des émoticônes en est l’illustration symptomatique. Dans nos travaux de recherche, nous déclinons l’analyse de sentiments dans le cadre de ce que serait une maison sensible. Les sentiments des personnes de la famille pourraient par exemple être détectés à partir des messages courts qu’elles partagent avec les autres membres de la famille.
Plus précisément, un modèle basé sur l’apprentissage automatique permet d’estimer la polarité d’un message (positive, négative ou neutre). Malgré de grandes avancées dans le domaine de l’analyse de sentiments, la tâche reste difficile. L’analyse de sentiment est dépendante du domaine ; une personne ne va pas utiliser les mêmes mots pour donner une opinion sur un restaurant (par exemple : « Accueil très moyen et nourriture fade ») ou pour critiquer un film (par exemple : “AFFLIGEANT ! Déprimant, désabusé et sombre. Les acteurs tentent de tirer leur épingle du jeu mais c’est mission impossible”). En complément des mots, les émoticônes (massivement utilisés sur les médias sociaux) peuvent être utilisés pour améliorer l’analyse des sentiments. Le choix des données d’apprentissage est alors crucial pour constituer un modèle. Dans la phase d’apprentissage, à partir des exemples de textes représentatifs, un modèle a appris à associer une catégorie (positive, négative ou neutre) à un texte. Des textes courts issus des médias sociaux comme Twitter et des textes issus des commentaires sur des produits Orange ont été utilisés pour cet apprentissage.
La première étape de l’apprentissage automatique d’un classificateur de texte consiste à transformer le texte en une représentation numérique, généralement un vecteur. Une approche classique de représentation des textes en sac-de-mots a été utilisée. Cette représentation a été enrichie grâce à un lexique de mots polarisés avec une polarité positive ou négative attribuée à chaque terme. Ainsi, chaque composante du vecteur représente la fréquence du mot polarisé. Le modèle utilisé prend également en compte les smileys et les emojis. Il a été réalisé avec Khiops, un outil Orange de Data Mining, basé sur une méthode de classification qui exploite l’hypothèse Bayesienne naïve8.
Le modèle utilisé a été testé sur 130.000 commentaires écrits par des clients d’applications Orange. L’accuracy (exactitude) du modèle est de 0,7 ; cela signifie que 7 prédictions sur 10 sont correctes.
Ce modèle d’analyse de sentiment est utilisable via une API, appelée Sentimeter, qui est déployée sur une infrastructure en approche devops afin de faciliter la mise à jour du modèle.
Des solutions intégrées dans la Plateforme Home’in the Future
Ces solutions permettant de déterminer la personnalité d’un individu – qui est relativement stable dans le temps – et l’humeur d’un individu – qui est, au contraire, très changeante – sont d’ores-et-déjà intégrées dans la Plateforme de Recherche intégrative Home’in the Future (qui soutient les travaux concernant “la Maison sensible”). Dans l’architecture cible, les données relatives à la personnalité et à l’humeur des utilisateurs restent stockées et exploitées dans le périmètre de la maison.
Ces solutions vont à présent être utilisées au sein du Groupe Orange pour le développement de prototypes de services, l’organisation de nouveaux tests (tests d’acceptabilité des solutions notamment), l’organisation d’expérimentations (validation auprès d’un plus grand nombre d’utilisateurs), etc.
A terme, ces solutions pourraient permettre à Orange d’adapter le comportement des services en fonction de l’état émotionnel des utilisateurs, d’offrir à ses clients une expérience plus sensible et pertinente. Personnalisation d’un assistant vocal domestique, personnalisation d’interfaces, recommandation de contenus… les champs d’applications à la maison sont nombreux ! Imaginons par exemple un assistant vocal capable de s’adapter automatiquement à notre personnalité et notre émotion… Aujourd’hui, les assistants vocaux interagissent de la même façon avec l’utilisateur, quelle que soient sa personnalité, quelle que soit son humeur. Reste à voir si c’est à un utilisateur “ouvert”, que l’assistant vocal suggérera la découverte de contenus éloignés de ses centres d’intérêts habituels ou, au contraire, à un utilisateur moins “ouvert”, afin d’éviter la polarisation des idées que dénonce Kiran Garimella9, actuellement Post-doc au MIT (Institute for Data, Society and Systems). Pour aller plus loin, l’assistant domestique pourrait lui aussi revêtir une personnalité, afficher des émotions, par exemple en utilisant une voix plus enjouée pour interagir avec l’utilisateur quand celui-ci est de bonne humeur, voire se permettre de faire un trait d’humour… En anthropomorphisant ainsi les interactions, en mimant nos codes émotionnels, l’assistant vocal pourrait ainsi peut-être rendre son usage plus naturel, plus convivial. Mais qu’en est-il de l’attachement inhérent, du refroidissement social occasionné, de la manipulation possible ? Ces comportements “sensibles” devront donc, on le voit, faire l’objet d’un questionnement éthique rigoureux ; il en va de la responsabilité d’Orange et les travaux sur ce sujet ne font que commencer.

Grâce à nos technologies, un assistant vocal pourrait s’adapter à la personnalité et à l’humeur de ses utilisateurs.
En savoir plus :
[1] – Aux origines de l’intelligence artificielle, L. Verbeke (2018)
www.franceculture.fr/numerique/aux-origines-de-lintelligence-artificielle
[2] – La Plus Belle Histoire de l’intelligence, S. Dehaene, Y. Le Cun, J. Girardon (2018)
[3] – Domaine de Recherche « Vie personnelle numérique »: https://hellofuture.orange.com/fr/blog-de-la-recherche/vie-personnelle-numerique/
[4] – An alternative « description of personality »: The Big-Five factor structure. Journal of Personality and Social Psychology, Lewis R. Goldberg (1990)
[5] – Predicting Personality Using Novel Mobile Phone-Based Metrics, Y-E de Montjoye, J. Quoidbach, F. Robic, A. Pentland ; MIT, Harvard University, Ecole Normale Supérieure de Lyon (2013)
[6] – Understanding the impact of personality traits on mobile app adoption – Insights from a large-scale field study, R.Xu, R. M. Frey, E. Fleisch, A. Ilic; ETH Zurich (2016)
[7] – The Online Social Self: An Open Vocabulary Approach to Personality, M.L. Kern, J.C Eichstaedt, H.A Schwartz, L. Dziurzynski, L.H. Ungar, D.J Stillwel, M. Kosinski, S.M. Ramones, M.E.P. Seligman; University of Pennsylvania, University of Cambridge (2013)







