


“Being able to isolate a speaker’s voice is crucial for many applications, whether it involves a query interface or is used in telecommunications.”
Voice Is Alive and Well
Speaking is one of the fastest modes of communication, averaging 200 words per minute. This fact makes it the preferred means of conveying information in human interactions. The recent pandemic has overhauled the way we communicate by making telecommuting and videoconferencing accessible to many. Voice interactions are gradually becoming dependent on the telecommunications capabilities of our smartphones, computers, connected objects, etc.
Long confined to social interaction, speech is now being used by most digital devices in our daily lives. The growing success of voice assistants, introduced in France in 2012, has made voice a solid alternative to traditional human-machine interfaces. Whether in our cars, appliances or automatic answering machines, these voice systems are now everywhere in our society.
Ultimately, whether used as a tool for interaction or for interpersonal communication, voice plays a crucial role in many applications, meaning the microphones in our connected devices have never been so busy. However, voice must be handled with precision, because, as a means of communicating, speech is intuitive to users. They therefore have high expectations and user experience can drastically decrease when misunderstandings arise. Unfortunately, sound is an organic type of data that is particularly prone to interference, possessing characteristics that vary between different environments.
How can we ensure a consistent user experience when using voice interfaces? How can we minimize this interference and boost the performance of voice interaction systems? This article goes on to detail the results obtained by means of doctoral research aimed at improving the types of interactions mentioned above. The approach selected for this research was the audiovisual separation of voice sources, which was addressed in a publication at the Interspeech 2021[1] conference.
Isolation Reigns Supreme
Voice source separation is the isolation of one or more voices among a set of acoustic signals. A vast number of studies are now focusing on this process, which promises numerous applications.

Figure 1: Illustration showing the principle of voice source separation.
The first approach—one used in particular by connected speakers—involves a system with several microphones distributed around a disk or sphere. Configuring the microphones like this enables spatial filtering of the sound, meaning it isolates any signals coming from the same direction. This approach, however, is costly and lacks versatility due to the complexity of the recording system.
More recent research focuses on the use of deep neural networks for processing acoustic signals recorded by a single microphone. This approach attempts to mimic the human brain’s ability to focus on a specific auditory source, a phenomenon called the “cocktail party effect.”
However, simply using a single audio channel in the separation process may create difficulties. Voice sources are typically separated over time frames spanning tens to hundreds of milliseconds. During this process, it is difficult to associate isolated voices with the right people through iterations — a phenomenon known as the permutation problem[2].
A solution to the permutation problem is to use visual information in addition to acoustic information in order to reliably determine which voice belongs to which person. This approach is more limited because it requires video, but it is suitable for many applications such as videoconferencing or interactions with social robots, for example. In addition, it offers three significant advantages. First, a link can be exploited between the oral dynamics of a speaker and the sound produced by said speaker’s mouth. Second, visual information is unaffected by noise interference, making it a reliable alternative in suboptimal acoustic environments. Finally, since the visual and acoustic information is partly redundant, the simultaneous use of the two sources helps to resolve the permutation problem.
Better Hearing Through Seeing
Like sound, an image is a piece of data with a wealth of information but complex to process. The problem therefore hinges on what data to extract and how to extract it. In this research, innovation has come from the use of speakers’ facial dynamics. This choice is inspired by the way the human brain processes data from optic nerves. Neuroscientific research has shown that there are two distinct pathways in our brain, the ventral and the dorsal, which are responsible for the static and dynamic analysis of images, respectively[3].
Facial dynamics are estimated using an optical flow algorithm[4] that can calculate the speed and direction of movement of the points of interest on a face as shown in Figure 2. Optical flow algorithms are increasingly popular for recognizing facial expression[5] or detecting an active speaker[6] — two applications closely related to the separation of voice sources because they rely heavily on analyzing motion discontinuities.

Figure 2: Illustration showing the points of interest on a face being detected and predicting optical flow.
At the end of the learning process, the neural network is able to exploit the correlation between the sound speakers produce and the movement of their facial muscles in order to effectively isolate the voice of each speaker in an environment. For each speaker, it reconstructs a new audio signal without interference.
This learning process is carried out using synthetic data constructed from two datasets: AVSpeech[7] and AudioSet[8]. The first is a dataset composed of YouTube videos with a single speaker, the second is varying types of audio clips, which are used to add possible non-vocal interference to the synthetic data. Samples can then be constructed with a known number of speakers and specific kinds of ambient noise, allowing the system to be tailored to specific use cases. In order to measure the versatility of separation, the proposed experimental design is aimed at testing different configurations where the number of visible speakers, the number of audible speakers and the presence of ambient noise vary. The audio signal input is always a mono signal sampled at 16 kHz.
Results
The most common metric used to evaluate the effectiveness of a source separation algorithm is the SDR (signal to distortion ratio). The SDR is expressed in decibels (dB) and is used to evaluate the proximity of an isolated signal to the reference signal — a high SDR means that a prediction is close to the reference signal, and vice versa. The metric used here is the SI-SDR (scale invariant signal to distortion ratio). This second metric is very similar to the SDR and is not sensitive to changes in scale, i.e. the amplitude of the predicted signal is not taken into account.
In this study, it is assumed that each visible speaker does not have an obscured face, does not make sudden movements, and is positioned face-on for more than half the length of the sample.
The results are compared with two benchmarks. The first, DPRNN[9], is a network of neurons that exclusively uses audio data in voice source separation. To date, this network offers the best, cutting-edge results in this field. This benchmark is interesting because it evaluates the contribution of visual information to the separation process. The second benchmark, developed by Ephrat et al.[7], is a network of neurons dedicated to the audiovisual separation of voice sources using static images as visual characteristics. This second algorithm is part of the work that introduced the AVSpeech dataset, and, in this sense, it is an ideal benchmark.
Table 1 shows that our approach, labeled as “Orange,” leads to better results in all tested configurations. Obtained from the synthetic dataset, these results show on the one hand that visual information does indeed contribute to more efficient voice separation, and on the other that the use of facial dynamics offers a significant improvement compared to the use of static images.
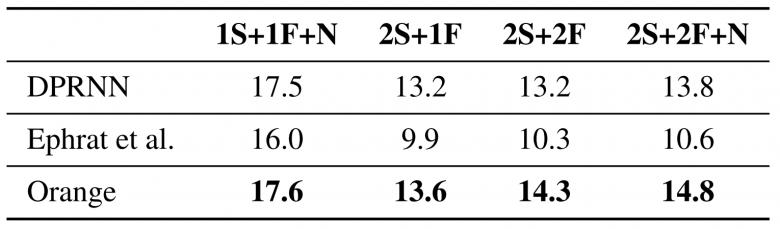
Table 1: Quantitative and comparative analysis of voice source separation effectiveness expressed in SDRi (dB) based on number of speakers (S), number of visible speakers (F) and presence of non-vocal ambient noise (N)
Voice source separation offers many benefits, the first of which is to enable human voices to be better understood in suboptimal sound environments. This makes it a major asset for videoconferencing or news reporting, for example.
Next, source isolation improves the efficiency of sound processing algorithms such as voice recognition, voice identification and noise classification. This type of technology will allow tomorrow’s connected objects to interpret queries without the need for them to be repeated.
Benefits offered by the processing of visual information are significant, but we must question the cost associated with such a solution. Image analysis is a complex and resource-intensive task, meaning real-time applications of this technology are more difficult. The main advantage of audiovisual separation is that it associates a voice with a face, and thus with an individual. If this capability is not required, processing audio alone may be a better compromise.
It should be noted that the study carried out does not account for cases where the faces of the speakers are obscured or viewed in profile. A deeper analysis of these limitations in future studies would be warranted in order to improve the efficiency of separation under real conditions.
Bibliography
[1] Rigal, R., Chodorowski, J., Zerr, B. “Deep Audio-Visual Speech Separation Based on Facial Motion”. Proc. Interspeech 2021, 3540-3544, doi: 10.21437/Interspeech.2021-1560
[2] D. Yu, M. Kolbaek, Z. H. Tan, and J. Jensen, “Permutation invariant training of deep models for speaker-independent multi-talker speech separation,” in ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing – Proceedings, 2017, pp.241–245.
[3] M. A. Goodale and A. Milner, “Separate visual pathways for perception and action,” Trends in Neurosciences, vol. 15, no. 1, pp.20–25, 1992.
[4] C. Bailer, B. Taetz, and D. Stricker, “Flow fields: Dense correspondence fields for highly accurate large displacement optical flow estimation,” CoRR, vol. abs/1508.05151, 2015.
[5] C. Huang and K. Koishida, “Improved active speaker detection based on optical flow,” in IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, vol. 2020-June, 2020, pp. 4084–4090.
[6] B. Allaert, I. M. Bilasco, and C. Djeraba, “Consistent optical flow maps for full and micro facial expression recognition,” VISIGRAPP 2017 – Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, vol. 5, pp. 235–242, 2017.
[7] A. Ephrat, I. Mosseri, O. Lang, T. Dekel, K. Wilson, A. Hassidim, W. T. Freeman, and M. Rubinstein, “Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation,” ACM Transactions on Graphics, vol. 37, no. 4, apr 2018.
[8] J. F. Gemmeke, D. P. W. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 776–780.
[9] Y. Luo, Z. Chen, and T. Yoshioka, “Dual-Path RNN: Efficient Long Sequence Modeling for Time-Domain Single-Channel Speech Separation,” ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing – Proceedings, vol. 2020-May, pp. 46–50, 2020.







