


Recent advances on connected objects and artificial intelligence introduce new opportunities to revolutionize daily-living at home. Indeed, these advances allow for finer and finer understanding of ambient context of occupants at home. Using this understanding of context, the home can adapt its behavior in a complex fashion to the routines and needs of its occupants.
Orange, through its research platform Home’in [3], proposes that the home should be sensitive to the ambient context of its occupants, while respecting strong constraints of privacy and local processing of data. These constraints bring forth new research problems related to automatic ambient context recognition, such as human activity, for which Home’in integrates new solutions based on local machine learning.
In order to ensure the quality and robustness of these new solutions, it is necessary to experiment on datasets that are representative of varied ambient home contexts. To avoid the difficulties of recording such datasets in real home environments, Orange proposes to use a home simulator, which can emulate numerous heterogeneous home contexts, in a sped up fashion and with no constraints of real-world sensor installations.
The Home of Tomorrow: New Research Questions for Novel Services
Through its research platform called Home’in, Orange aims at designing new home systems that are not just reactive but also sensitive [4]: that is, a home capable of integrating and reasoning on ambient context, in order to propose personalized and adapted assistance to its occupants. This assistance can materialize through the automation of a particular task, but also through the anticipation of a future need, through advising to occupants, or even through inaction. In short, the home of tomorrow must propose new assisting services, in a reactive and proactive way, which implies a sensitive home, wary of its occupants.
For the home to be sensitive, it is essential that it can analyze the needs, the wishes, or the habits of its occupants. These elements are part of what we call the context of the home. Activity of occupants, detailed further down in this article, is one essential component of this context. Other dimensions such as personality or mood are also part of this context, but are not discussed in this article (see [5] for more details).
In order to observe, directly or indirectly, the different aspects of this context, the home requires diverse sources of data. Motion detection, electrical consumption, ambient sound, or television usage are some examples of such data sources. Exploiting these personal data is a necessity in order to provide new useful services that rely on artificial intelligence technologies.
Privacy and trust in the home are therefore central questions associated to the design of future home systems. It is rightly expected that the use of these personal data is well controlled, reasonable, in adequacy with the protection of private life, and respecting of legislation (such as the General Data Protection Regulation GDPR). The sensitive home must provide firm guarantees on these questions.
For these reasons, the Home’in research platform, which represents Orange’s vision for the home of tomorrow, explores strategies of completely local processing of home data. Digital traces of occupant lives are thus controlled within the home itself, instead of being deported and exposed in distant servers. However, this choice induces new research constraints. For example, computing resources must be local, and thus significantly more limited than with distant servers: it is therefore necessary to image new processing techniques that require little computing power, while maintaining accurate identification of ambient context elements.
Understanding Ambient Context at Home Using Machine Learning
It appears difficult to find explicit relationships linking observed data collected in the home with its ambient context. Indeed, how could current activities of a family be deduced from a few digital data points of electrical consumption or door openings, given the complexity and variability of human routines? Moreover, the existing correlations between observations and ambient context will necessarily be very different from one home to the next: the habits, emotions, or even preferences are different between neighbors, and so is their installation of connected objects.
Given the multitude of sources of variability, manually designing generic rules that allow the inference of precise ambient context from sensor observation appears to be impossible. Yet it is evident that these observations provide information about ambient context at home: these measures are triggered precisely due to occupant interactions at home. To discover these hidden relationships between observations and ambient context, a possible solution resides in machine learning techniques.
Machine learning has been at the forefront of artificial intelligence research topics for the last few years, most notably on topics where relationships between observations and decisions are too complex to be modeled using formal descriptions. A typical example of such a problem is computer vision: starting from a list of pixels, it is difficult to find the right set of explicit rules describing whether these pixels represent a human face or not (even though this problem is “instinctually” solved by a human). Using supervised machine learning, this difficulty can be circumvented via a statistical strategy: one trains a classifier for this decision task by giving it many example images of human faces and non-faces, along with the correct answer for each example (a label); the classifier will alter autonomously its own parameters so as to correct its errors, if it were to give an incorrect decision. For a new unknown image, the classifier should take the correct decision, assuming it was trained sufficiently well, on sufficiently representative data. Therefore, instead of requiring a complex understanding of face recognition mechanisms, one can deport the main difficulty of the problem to the task of collecting many labeled images, which proves to be much simpler and much less costly nowadays.
In much the same way, it is possible to transpose these kinds of approaches in order to deduce ambient context information at home.
Recognizing the Activity of Occupants Using a Place-Based Approach
In particular, supervised machine learning can be used to recognize activities of occupants: “cooking”, “watching TV”, “sleeping”, etc. Contrary to other classical problems where machine learning is used, such as computer vision, new constraints appear in the context of homes, as modeled in the Home’in platform: manipulated data are personal or even sensitive; routines of occupants are specific to each home; data sources available and the overall topology of the house are different from one home to the next. These different constraints imply new research problems for the application of machine learning in the context of activity recognition at home:
- Personal data should not be uploaded to a remote server. Local approaches must thus be used, with restrictions on computing power.
- Training examples are specific to each home, both in terms of data sources and of routines of activities. Approaches which require few training examples must thus be used.
Because of these constraints, an approach based on the division of homes into places (see Figure 1) is proposed in Home’in: instead of dealing with the entire home at once, it is divided into a list of distinct places, each with its own activity recognition classifier. For example, in a place such as the kitchen, the classifier assigned to this place is specialized in the recognition of activities which can occur specifically in the kitchen, relying only on data sources that monitor the kitchen. A final step of fusion is used to group the recognitions performed in each place, taking into account the number of occupants, or potential recognition errors, in order to reach a global consensus on activity in the home [1, 2].
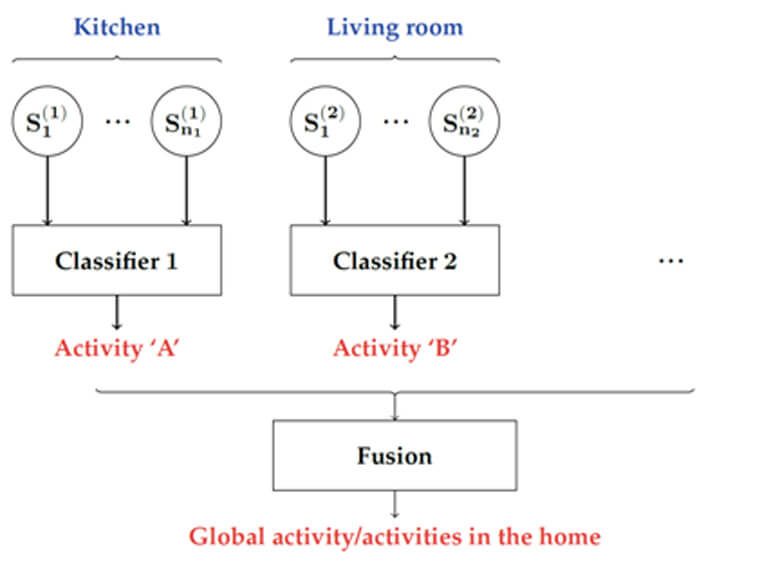
Figure 1: Place-based activity recognition model.
This model is well suited to the previously mentioned scientific problems: the division of activity recognition between different places allows a reduction in the complexity of modeling the relationships between observations and activities in each place. As such, classifiers require less training data and less computing power, allowing local and personalized deployment of activity recognition approaches at home.
However, be it for activity but also for other ambient context elements, there subsist certain drawbacks. Although a place-based activity recognition model lessens the number of required training examples, it does not completely eliminate this need. In other words, the home requires explicit examples of different situations, before understanding its ambient context. Moreover, as long as this training phase is not over, one cannot benefit from services that require such an understanding of ambient context. Finally, during the conception of such techniques, it is difficult to estimate whether these algorithms, such as place-based activity recognition, exhibit accurate understanding of ambient context for all possible home configurations.
For Orange, one possible avenue of research to tackle these difficulties is as surprising as it is promising: simulating homes.
Simulation: a Way to Generate Home Data
In order to properly design and evaluate the performances of context recognition modules, the different algorithms employed must be evaluated and validated on a large number of datasets, collected in varied and heterogeneous home environments. Room configuration, occupant behaviors, and connected object installations are example of such variability in homes, which can have great impact on the performances of context understanding techniques, and which must thus be experimentally verified. To collect these validation datasets, the first solution that comes to mind consists in instrumenting multiple real homes with diverse room configurations and family situations, for potentially long durations. However, such instrumentations and family involvements are prohibitively tedious and costly.
These difficulties highlight the problem of acquiring high-quality datasets in the smart home research domain (a problem also encountered in other machine learning domains). Consequently, it is necessary to find an alternative solution for the collection of home data. Home simulation is a surprising candidate for this problem. The idea consists in the development of a virtual home environment, in which occupants, activities, sensors, etc., are managed by a simulator. This simulator must be able to offer vast configuration possibilities, for room placements, sensor installations, and occupant activities. Moreover, it must manage, in a simulated yet realistic fashion, the behavior of virtual occupants, allowing the generation of many interactions between sensors and activities. With such a simulator, it would thus be possible to generate a high number of heterogeneous datasets, which contain varied ambient contexts in homes with diverse topologies.
Orange’s Home Simulator
Orange aims to propose a home simulation tool that can be directly integrated to the Home’in research platform. In this simulator, an autonomous virtual agent, representing the occupant, can move around and act in accordance with common activities of daily living. The virtual home in which this agent acts is instrumented with simulated sensors, that trigger in much the same way real sensors would in a physical instrumented home.

Figure 2: Virtual model of an avatar (top right, in blue) in its 3D virtual environment
More precisely, the simulation tools rely on a virtual environment deployed using the Unity3D game engine. These tools allow, among other things, the quick creation of virtual environments with different home configurations. Beyond their geometries (structure, furniture, etc.), virtual environments also expose semantic information, which allow autonomous virtual agents to understand and interact: how to sit on chair, drink a glass of water, etc. The virtual agent in this simulator can thus move freely in the home while performing sequences of actions. Simulation tools also allow for the instrumentation of environments with virtual sensors that replicate real sensor behaviors. These sensors trigger and notify the system whenever a related change occurs in its monitored neighborhood. For example, when the autonomous agent opens a door, on which a virtual door opening sensor is affixed, a notification is sent by this sensor to inform that the door was just opened. These notifications are then stored in a relational MySQL database, which allows the construction of datasets.
Sequences of actions of the virtual agent are not determined randomly: they are determined by the decisions of a planner, which can be considered as the artificial intelligence (AI) of the virtual agent, and that interacts with the 3D visualization tool. This AI has the role of scheduling the sequences of actions of the occupant, with respect to predefined goals to reach. The planner relies on a standardized AI language: PDDL/STRIPS [6]. This language is used to both define all possible actions that the virtual agent can perform, and the initial conditions of its environment and its goal. The virtual agent must thus from a starting point, defined by initial conditions, reach a goal defined in the planner. PDDL is the script that will determine the sequence of actions that need to be performed in order to reach the goal from the given starting point. From the perspective of dataset generation, actions of virtual agents can be simulated for long time periods in a sped up fashion, in order to obtain lengthy datasets of simulated sensor events in reasonable times. It is however important to mention that simulation of actions of virtual agents is focused on specific scenarios of short lengths. During 2020, further research will be conducted to allow the simulator to establish automatically long duration pseudo-random scenarios.
Notifications sent by sensors are always related to a known action, since it was imposed on the virtual agent by the planner. This relationship between virtual sensor events and ambient context imposed by the planner is essential, so as to obtain labeled datasets which can be used for training and validation purposes, as described in previous sections. The variability of generated data, invaluable for these machine learning approaches, is the result of the variability in generated behaviors, virtual environments, and virtual sensor instrumentations. Comparing data from simulation and from real homes remains, however, is an important step in order to assess the representativeness of simulated data for real-case applications.
Conclusion
Taking into account strong constraints of privacy and local processing of data induces new research problems related to the understanding of ambient context at home with artificial intelligence techniques. The local approach for activity recognition proposed in this article illustrates how these difficulties can be tackled for one dimension of ambient context.
The introduction of new approaches of automatic context understanding based on machine learning requires that we verify their performances for diverse homes. For this purpose, Orange proposes the use of a home simulator as a mean to virtually experiment the home of the future, avoiding the technical and economic difficulties of real-life experimentation.
The combination of new activity recognition approaches with a home simulator is the first step towards an ambitious goal: an autonomous and sensitive home, respectful of privacy. Despite promising advances, this goal is still far from reach, stimulating the pursuit of numerous research subjects at Orange.
[1] J. Cumin, G. Lefebvre, F. Ramparany, J. L. Crowley. Human activity recognition using place-based decision fusion in smart homes. In international and interdisciplinary conference on modeling and using context, 2017.
[2] J. Cumin. Recognizing and predicting activities in smart homes. Thèse en informatique de l’Université Grenoble Alpes, 2018.
[3] Home in the Future: the home of tomorrow will be sensitive. Orange Research Blog, 2019.
[4] The sensitive home is built and rebuilt with the Home’in platform. Orange Research Blog, 2017.
[5] Our personality and our mood revealed by our digital footprints. Orange Research Blog, 2019.
[6] Writing Planning Domains and Problems in PDDL
[7] Jérémy Lacoche, Morgan Le Chenechal, E Villain, A Foulonneau. Model and Tools for Integrating IoT into Mixed Reality Environments: Towards a Virtual-Real Seamless Continuum. ICAT-EGVE 2019 – International Conference on Artificial Reality and Telexistence and Eurographics Symposium on Virtual Environments, Sep 2019, Tokyo, Japan







