


Les avancées récentes en matière d’objets connectés et d’intelligence artificielle induisent des opportunités de révolutionner la vie à la maison. En effet, ces avancées permettent une compréhension de plus en plus fine du contexte de vie des occupants dans la maison. Par cette connaissance du contexte de vie, le comportement de la maison peut s’adapter de manière complexe aux habitudes et aux besoins de ses occupants.
Orange, à travers la plateforme de recherche Home’in [3], propose de rendre la maison sensible au contexte de vie de ses occupants, tout en respectant des contraintes fortes de vie privée et de traitement local des données. Ces contraintes amènent de nouveaux problèmes de recherche autour de la reconnaissance automatique d’éléments du contexte de vie, comme l’activité humaine pour laquelle Home’in intègre des solutions nouvelles reposant sur l’apprentissage automatique local.
Pour s’assurer d’un bon fonctionnement de toutes ces nouvelles solutions, il est nécessaire de disposer de jeux de données représentatifs de contextes de vie à la maison variés. Pour pallier à la complexité de capture de ces jeux de données dans des maisons réelles, Orange propose un simulateur de foyer permettant d’émuler de nombreux contextes de vie hétérogènes, de manière accélérée et sans contraintes d’installations dans des véritables maisons.
La maison de demain : de nouveaux services qui impliquent de nouveaux problèmes de recherche
À travers la plateforme Home’in, Orange propose d’évoluer de la maison réactive vers la maison sensible [4] : c’est-à-dire une maison capable d’intégrer et de raisonner sur le contexte de vie ambiant, pour proposer une assistance personnalisée et adaptée à ses occupants. Cette assistance peut se concrétiser par l’automatisation d’une tâche, mais aussi par l’anticipation d’un besoin futur, par la communication d’information et de conseils à ses occupants, ou encore par l’inaction, si le contexte et les besoins des occupants s’y prêtent. En somme, la maison de demain devra être capable de proposer des services d’assistance de manière réactive et proactive, ce qui implique une maison sensible particulièrement aux occupants qui l’habitent.
Pour atteindre cette sensibilité, il est essentiel que la maison puisse analyser les besoins, les envies, ou encore les habitudes de vie des occupants. On regroupe ces différents éléments sous le terme de contexte de vie. L’activité des occupants, développée plus en détails dans la suite de cet article, en est un des éléments essentiels. D’autres dimensions comme la personnalité et de l’humeur à la maison peuvent être prises en compte, mais ne sont pas traitées dans cet article (voir [5] pour plus de détails).
Il est nécessaire que la maison dispose de sources de données diversifiées lui permettant d’observer directement ou indirectement les différentes incarnations de ce contexte de vie. Des détections de mouvement, des mesures de consommation électrique, le son ambiant, ou encore l’usage de la télévision sont autant d’éléments qui peuvent renseigner sur le contexte de vie. L’exploitation de ces données personnelles est indispensable pour pouvoir proposer de nouveaux services utiles reposant sur des technologies d’intelligence artificielle.
Les questions du respect de la vie privée et de la confiance associée à la maison sensible deviennent dès lors centrales. Il est légitimement attendu que l’usage de ces données personnelles soit raisonnable, protecteur de la vie privée des occupants, et contrôlé, dans le respect de la législation (comme le Règlement Général pour la Protection des Données, RGPD) mais aussi tout simplement du bon sens. La maison sensible doit apporter des gages solides pour qu’elle ait vocation à prévenir toute exploitation abusive des données personnelles.
C’est pourquoi la plateforme de recherche Home’in, qui incarne la maison de demain pour Orange, explore un traitement entièrement local des données. Les traces numériques des occupants restent ainsi maitrisées au sein du foyer, plutôt que d’être déportées et exposées dans des serveurs distants. Ce choix implique cependant de nouvelles contraintes de recherche. Par exemple, les ressources de traitement des données doivent être locales, et donc sensiblement plus limitées que si des serveurs distants étaient utilisés : il faut donc imaginer de nouvelles techniques de traitement qui nécessitent peu de puissance de calcul, mais qui permettent toujours d’identifier correctement les éléments du contexte de vie des occupants.
L’apprentissage automatique pour comprendre le contexte de vie des habitants dans la maison
Instinctivement, il est difficile de trouver des relations explicites qui lient les observations numériques collectées dans la maison avec le contexte de vie : comment pourrait-on déduire les activités courantes d’une famille à partir de quelques informations numériques de consommation électrique ou d’ouvertures de portes, étant donnée la complexité des habitudes de chacun et la grande variabilité des comportements humains ? Par ailleurs, les liens corrélant observations et contexte de vie seront nécessairement très différents d’un foyer à l’autre : les habitudes, les émotions, ou encore les préférences sont différentes entre voisins, de même que les objets connectés.
De par toutes ces sources de variabilité, construire manuellement des règles génériques permettant de déduire un contexte de vie précis à partir d’observations est illusoire. Pourtant, il est évident que les observations captées par la maison informent sur le contexte de vie des occupants : les mesures se déclenchent justement en raison des interactions humaines dans la maison. Pour découvrir les liens cachés entre observations et contexte de vie, une solution vers laquelle se tourner se trouve être l’apprentissage automatique.
En effet, les techniques d’apprentissage automatique (“machine learning” en anglais) ont depuis maintenant de nombreuses années le vent en poupe, notamment pour s’attaquer à des problèmes pour lesquels la modélisation des liens entre observations et décisions est trop complexe pour être décrite de manière formelle. Un exemple typique d’un tel problème est l’analyse d’image : en partant d’une liste de pixels, il est difficile de trouver de bonnes règles explicites qui permettent de déduire si ces pixels représentent ou non le visage (ou l’absence de visage) d’une personne (alors que ce problème est résolu “instinctivement” pour un humain). Avec l’apprentissage automatique supervisé, on contourne cette complexité en utilisant une stratégie statistique : on entraine un classifieur à faire cette distinction en lui donnant de nombreux exemples de photos de visages et de non-visages, accompagnés de la réponse à donner pour chaque exemple (un label) ; le classifieur modifie lui-même ses paramètres pour corriger son erreur, s’il ne donne pas la bonne réponse pour un exemple d’image donné. Pour une nouvelle image inconnue, on espère alors que le classifieur a été entrainé suffisamment bien, et sur des données suffisamment représentatives, pour qu’il prenne la bonne décision. Ainsi, au lieu de nécessiter une compréhension complexe des mécanismes de reconnaissance de visages, on peut déplacer la difficulté à la collecte d’un grand nombre d’images exemples labellisées, ce qui est bien moins coûteux et complexe de nos jours.
De la même manière, il est possible de transposer ce type d’approches pour déduire des informations de contexte de vie à la maison.
Reconnaitre les activités des occupants par une approche “lieux de vie”
En particulier, l’apprentissage automatique supervisé peut être employé pour reconnaitre les activités des occupants : “faire la cuisine”, “regarder la télévision”, “dormer”, etc. Contrairement à d’autres problèmes classiques de l’apprentissage automatique comme l’analyse d’image, de nouvelles contraintes s’imposent dans le cadre de la maison incarnée par la plateforme de recherche Home’in : les données manipulées sont personnelles voire sensibles ; les habitudes d’activités des personnes sont spécifiques à chaque foyer ; les sources de données disponibles et la topologie de la maison en elle-même diffèrent d’un foyer à l’autre. Ces différentes contraintes impliquent de nouveaux problèmes de recherche pour l’utilisation de l’apprentissage automatique dans le cadre de la reconnaissance d’activités à la maison :
- Il n’est pas souhaitable de faire remonter les données personnelles dans le réseau. Il faut donc employer des approches locales, peu coûteuses en ressources de calcul.
- Les exemples d’apprentissage, à la fois en termes de sources de données et d’activités à reconnaitre, sont spécifiques à chaque foyer. Il faut donc employer des approches nécessitant peu d’exemples d’apprentissage.
C’est pour répondre à ces contraintes qu’une approche basée sur la division de la maison en lieux de vie (voir Figure 1) est proposée dans Home’in: plutôt que de considérer la maison dans son ensemble, celle-ci est divisée en une liste de lieux distincts, qui possèdent chacun leur propre classifieur de reconnaissance d’activités. Par exemple, dans un lieu comme la cuisine, le classifieur associé à ce lieu est spécialisé dans la reconnaissance des activités pouvant se dérouler spécifiquement dans la cuisine, et ce en se basant uniquement sur des sources de données relatives à la cuisine. Une étape finale de fusion permet alors de regrouper les différentes activités reconnues dans chaque lieu (en prenant en compte par exemple le nombre d’occupants, ou les potentielles erreurs de reconnaissance), pour aboutir à une vue globale des activités réalisées à la maison [1, 2].
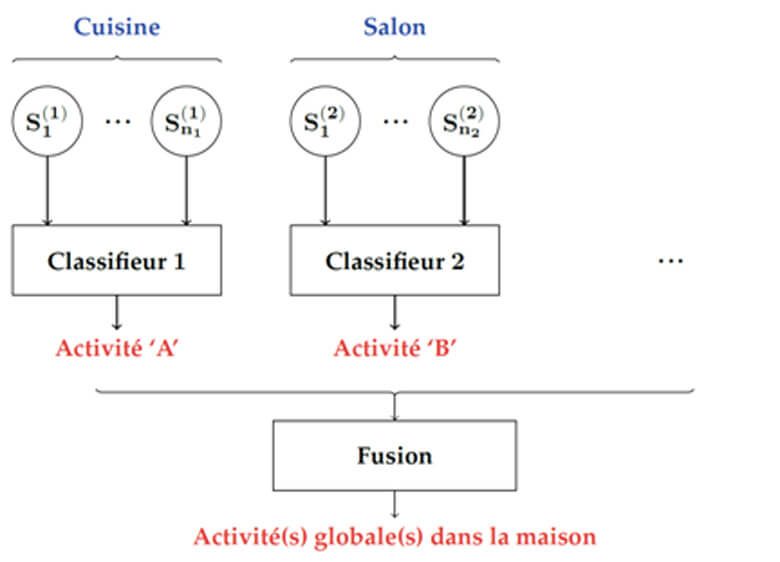
Figure 1 : Modèle de reconnaissance d’activités basé sur les lieux de vie.
Ce modèle répond bien aux problèmes scientifiques identifiés précédemment : la division de la tâche de reconnaissance d’activités à travers différents lieux de vie permet en effet de réduire la complexité de modélisation des liens entre observations et activités dans chaque lieu. Ainsi, les classifieurs nécessitent moins de données d’entrainement et moins de ressources de calculs, ce qui permet un déploiement local et personnalisé d’approches de reconnaissance d’activités à la maison.
Toutefois, que ce soit pour l’activité mais aussi pour d’autres informations de contexte de vie à la maison, certains inconvénients subsistent. Même si un modèle de reconnaissance d’activités par lieux de vie permet de réduire le nombre d’exemples d’apprentissage nécessaire, il reste obligatoire d’en obtenir un certain nombre. Autrement dit, pour que la maison puisse comprendre le contexte de vie, il faut dans un premier temps lui donner explicitement des exemples de différentes situations dans la maison. De plus, tant que cette phase d’apprentissage n’est pas terminée, on ne pourra pas profiter des services nécessitant une compréhension du contexte de vie. Par ailleurs, dans une phase d’élaboration, il est difficile d’estimer si les outils de compréhension du contexte de vie, comme la reconnaissance d’activités par lieux de vie, fonctionnent bien dans toutes les configurations possibles de foyer.
Pour Orange, l’une des pistes pour aborder ces difficultés est aussi surprenante que prometteuse : la simulation de foyer.
La simulation : une piste pour générer des données de foyer
Pour concevoir et démontrer l’efficacité des différents modules de reconnaissance du contexte de vie, les algorithmes devront être élaborés, éprouvés et validés sur la base d’un grand nombre de jeux de données tous issus d’environnements de maisons instrumentées, variés et hétérogènes. Cette variabilité porte sur la configuration des pièces, sur le comportement des occupants ou encore sur les installations d’objets connectés. Autant de critères qui peuvent grandement influer sur les performances de compréhension du contexte de vie et qui imposent donc des vérifications expérimentales. Pour collecter ces jeux de données de validation, la première solution venant à l’esprit consiste à instrumenter plusieurs domiciles avec des configurations de pièces et de situations familiales diverses, potentiellement sur de longues périodes. Or l’expérience montre qu’équiper des pièces et impliquer toute une famille à ces fins nécessite un investissement long, fastidieux et coûteux.
Cela explique également pourquoi les jeux de données de bonne qualité soient difficiles à acquérir dans le domaine de la maison connectée (c’est un problème que l’on retrouve également dans d’autres domaines impliquant de l’apprentissage supervisé). Dès lors, une solution alternative pour acquérir de tels jeux de données est nécessaire. Une piste étonnante repose sur la simulation de foyer. L’idée consiste à développer un environnement virtuel, où tous les éléments de la maison, les personnes, les activités, les capteurs, etc., sont gérés par un simulateur. Ce simulateur doit pouvoir proposer un grand nombre de configurations que ce soit au niveau de la disposition des pièces, du placement de capteurs et des activités proposées. De même, il doit gérer de manière simulée mais réaliste le comportement des occupants de la maison, permettant de générer un grand nombre d’interactions liant observations de capteurs et activités d’occupants. De cette manière, il sera donc possible de générer un grand nombre de jeux de données hétérogènes, contenant des contextes de vies variés dans des maisons aux topologies protéiformes.
Le simulateur de foyer d’Orange
Au sein d’Orange, l’objectif est de proposer un outil de simulation qui puisse s’intégrer directement à la plateforme de recherche Home’in. Dans ce simulateur, un agent virtuel autonome, représentant l’occupant, évolue dans une maison virtuelle et réalise des enchainements d’actions propres aux activités courantes de la vie quotidienne. La maison virtuelle est équipée par des capteurs simulés, qui se déclenchent et remontent des mesures de la même manière que le feraient de véritables capteurs dans une maison instrumentée réelle.

Figure 2 : Modélisation d’un agent (en haut à droite, en bleu) dans son environnement virtuel 3D
Plus précisément, les outils du simulateur s’appuient sur un environnement virtuel déployé à l’aide du moteur de jeu Unity3D. Ils permettent, entre autres, de créer rapidement des environnements virtuels avec différentes configurations de domicile. Cet environnement virtuel est qualifié d’informé puisqu’en plus de sa géométrie (structure, meubles, etc.) il expose également des informations sémantiques. Ces informations vont permettre à un agent virtuel autonome, représentant l’occupant, de comprendre et d’interagir avec l’environnement virtuel : s’asseoir sur une chaise, boire un verre d’eau, se laver les mains, etc… L’agent virtuel autonome intégré à ce simulateur pourra ainsi se déplacer librement dans le domicile tout en réalisant des enchainements d’actions. Ces outils permettent d’équiper ces environnements virtuels de capteurs virtuels reproduisant le comportement de capteurs réels. Ces capteurs réagissent en envoyant une notification à chaque variation de son environnement proche. Ainsi, par exemple, lorsque l’agent virtuel autonome ouvre une porte où est positionné un capteur, une notification est envoyée par ce même capteur qui informe ainsi de l’ouverture de la porte. Ces notifications sont ensuite stockées dans une base de données relationnelle MySQL, permettant notamment la construction de jeu de données.
Les séquences d’action de l’agent virtuel ne se déroulent pas au hasard : elles sont soumises à la décision d’un planificateur d’action, interagissant avec l’application de visualisation 3D, qui peut être considérée comme l’intelligence artificielle (IA) de l’agent virtuel. Cette IA a pour rôle d’ordonnancer les séquences d’actions de l’occupant en fonction d’un objectif à atteindre préalablement défini. Le planificateur repose sur un langage standardisé du domaine de l’IA, à savoir PDDL/STRIPS [6]. Ce langage permet de définir d’une part toutes les actions possibles réalisables par l’agent virtuel, et d’autre part les conditions initiales de son environnement ainsi que l’objectif à atteindre. L’agent virtuel devra donc à partir d’un point de départ, défini par les conditions initiales, atteindre le point d’arrivée défini par l’objectif final. C’est le script PDDL qui déterminera la séquence d’actions à réaliser pour passer du point de départ au point d’arrivée. Dans l’optique de générer une quantité importante de données, le simulateur permet la réalisation automatique d’actions de l’agent virtuel sur une longue période qui se fera à vitesse accélérée afin d’obtenir un jeu de données (issu des notifications de capteur) conséquent dans un temps réel raisonnable. Il est toutefois important de signaler que la simulation des actions de l’agent virtuel se focalise sur des scénarios définis et de courtes durées. Durant l’année 2020, des travaux de recherche pour établir des scénarios automatisés longues durées et pseudo aléatoires seront entrepris dans l’optique de rendre le simulateur de foyer autonome.
Les notifications issues de capteurs sont toujours associées à une action connue, puisque c’est le planificateur qui l’impose à l’agent virtuel. Cette association entre données issues des capteurs virtuels et des informations de contexte imposées par le planificateur est indispensable pour obtenir des jeux de données utilisables à des fins d’entrainement et de validation d’approches de compréhension du contexte de vie, telles que décrites dans les précédentes sections. La variabilité des données générées, indispensable à ces méthodes d’apprentissage, sera la résultante à la fois des différents comportements générés, des différents environnements virtuels de simulations et des différentes configurations de positionnement des capteurs. Une comparaison entre les jeux de données simulés et les jeux de données réels, pour s’assurer de leur représentativité, s’imposera néanmoins.
Conclusion
La prise en compte de contraintes fortes de vie privée et de traitement local des données induit de nouvelles problématiques de recherche autour des techniques d’intelligence artificielle pour comprendre le contexte de vie à la maison. L’approche locale de reconnaissance d’activités proposée dans cet article illustre comment ces difficultés peuvent être surmontées pour l’une des dimensions du contexte de vie.
L’introduction de nouvelles approches de compréhension automatique du contexte basée sur l’apprentissage automatique nécessite de nouveaux moyens d’en vérifier les performances pour des foyers variés. Pour ce faire, Orange propose l’utilisation d’un simulateur de foyer comme terrain d’expérimentation virtuel de la maison du futur, évitant les écueils techniques et économiques des expérimentations dans de réels foyers.
La combinaison d’une nouvelle approche de reconnaissance d’activités et d’un simulateur de foyer sont les premiers pas d’un objectif ambitieux : aboutir à une maison autonome et sensible, dans le respect de la vie privée. Malgré ces avancées prometteuses, cet objectif est encore loin d’être acquis, encourageant la poursuite de nombreux sujets de recherche au sein d’Orange.
[1] J. Cumin, G. Lefebvre, F. Ramparany, J. L. Crowley. Human activity recognition using place-based decision fusion in smart homes. In international and interdisciplinary conference on modeling and using context, 2017.
[2] J. Cumin. Recognizing and predicting activities in smart homes. Thèse en informatique de l’Université Grenoble Alpes, 2018.
[3] Home in the future : la maison de demain sera sensible. Blog de la recherche d’Orange, 2019.
[4] Avec la plateforme Home’in, la maison sensible s’édifie à plusieurs. Blog de la recherche d’Orange, 2017.
[5] Notre personnalité et notre humeur révélées par nos traces numériques. Blog de la recherche d’Orange, 2019.
[6] Writing Planning Domains and Problems in PDDL
[7] Jérémy Lacoche, Morgan Le Chenechal, E Villain, A Foulonneau. Model and Tools for Integrating IoT into Mixed Reality Environments: Towards a Virtual-Real Seamless Continuum. ICAT-EGVE 2019 – International Conference on Artificial Reality and Telexistence and Eurographics Symposium on Virtual Environments, Sep 2019, Tokyo, Japan







