


Pour les chercheurs en traitement automatique du langage (TAL), ce modèle est certes nouveau mais son principe est déjà bien connu. Le Monde s'appuyait plus récemment sur les témoignages d’experts en TAL pour nuancer l’engouement : “GPT-3, l’intelligence artificielle qui a appris presque toute seule à presque tout faire” [4].
Tentons ici de démystifier ce qui se cache derrière GPT-3, cette 3e génération de “Generative Pre-Training”, dernier maillon de l’évolution des modèles de langage à l’architecture de Transformers.
“GPT-3 a-t-il permis de découvrir l’IA généraliste ? L’avancée spectaculaire qui lui est associée ne vient pas tellement de ses capacités à générer des textes, mais plutôt de réaliser des tâches après avoir été exposé à un très petit nombre d’exemples”
Une nouvelle génération de modèles de langage
En moins d’une décennie, la recherche en traitement automatique du langage (TAL) a été bouleversée par l’apparition d’une suite de modèles de langages appris de manière non-supervisée sur de très gros corpus. Ces modèles, entraînés pour prédire les mots de la langue, se sont révélés capables de “capter” les caractéristiques linguistiques générales d’une langue. Les représentations mathématiques des mots que l’on pouvait obtenir en ouvrant le couvercle de ces modèles se sont avérées très pertinentes. Ils sont ainsi devenus le pont entre les mots de la langue et les représentations mathématiques sous forme de vecteurs qui servent de point d’entrée aux réseaux de neurones chargés de résoudre les tâches du TAL.
A l’origine, en 2013, les plongements de mots (ou “word embeddings” comme Word2Vec, Glove ou Fasttext) étaient capables de capter des représentations de mots sous la forme de vecteurs appris en prenant en compte le contexte des mots voisins dans de grands volumes de textes. Deux mots apparaissant dans des contextes similaires se retrouvaient “plongés” dans un espace à N dimensions, vers des points proches dans cet espace. Cette approche a permis des avancées significatives dans le domaine du TAL, mais présente également des limites. A partir de 2018 est apparue une nouvelle façon de générer ces vecteurs de mots. Plutôt que de sélectionner le vecteur d’un mot dans un “dictionnaire” statique de vecteurs appris préalablement une fois pour toutes, un modèle est chargé de générer dynamiquement la représentation vectorielle d’un mot. Un mot se voit ainsi projeté vers un vecteur non plus uniquement en fonction d’un a priori, mais également en fonction du contexte dans lequel il apparaît au moment où il doit être projeté. Les modèles permettant de réaliser efficacement ces projections contextuelles (BERT [6], ELMo et dérivés, GPT et ses successeurs) s’appuient sur une architecture à la fois simple et puissante appelée Transformer.
Sortie en décembre 2017, le Transformer [5] est la dernière grande révolution technologique dans le domaine du traitement automatique du langage.
Un Transformer est composé d’un encodeur et d’un décodeur :
- l’encodeur est responsable d’encoder l’entrée pour une prise en compte maximale du contexte en entrée ;
- le décodeur génère la prédiction de manière auto régressive : les prédictions sont réalisées pas à pas et le résultat d’une prédiction sert d’entrée pour la prédiction suivante.
La clé du succès de cette approche est l’utilisation, à tous les niveaux de ce réseau de neurones, d’un mécanisme d’attention permettant une prise en compte efficace du contexte. Si les approches précédentes (“Recurrent Neural Network” ou “Convolutional Neural Network”) pouvaient modéliser des dépendances contextuelles, elles étaient toujours contraintes par un référencement des mots par leurs positions. L’attention vise pour sa part à un référencement par le contenu. Au lieu de chercher des relations avec d’autres mots du contexte à des positions données, l’attention permet de chercher des relations indifféremment avec tous les mots du contexte, et grâce à une implémentation très efficace, permet de s’appuyer sur les mots les plus similaires pour améliorer la prédiction, quelle que soit leur position dans le contexte.
Les sorties de ces modèles se sont enchaînées avec un rythme de plus en plus rapide. Chaque nouveau modèle était entrainé sur des corpus de plus en plus gros (Wikipédia, puis Common Crawl), sa taille devenait de plus en plus grande (nombre de paramètres) et la puissance de calcul nécessaire pour son entrainement de plus en plus importante. Bien évidemment, chaque nouveau modèle pouvait ainsi “capter” plus de caractéristiques linguistiques générales d’une langue que son précédent. Des modèles multilingues appris sur des données de différentes langues sont même apparus, ouvrant la voie à de nouvelles applications. En théorie, chaque nouveau modèle devait ainsi être plus pertinent pour les apprentissages applicatifs qu’en faisaient ensuite les chercheurs dans leurs propres modèles. Dans la réalité, les choses sont un peu plus nuancées.
De BERT à GPT-3 : une avancée technologique
Selon François Yvon, chercheur au LIMSI/CNRS : “Techniquement, c’est compliqué. Conceptuellement, c’est simple. Je suis plus impressionné par la technologie que par la science derrière GPT-3” [4]. En effet, le modèle GPT-3, dernier en date de la famille des modèles de type “Generative-Pre Training” produit par OpenAI [16], s’appuie sur les architectures précédentes mais est entrainé avec beaucoup plus de données.
OpenAI s’inscrit globalement dans une croyance forte en une intelligence artificielle généralisée. Cette croyance postule l’émergence des capacités cognitives si le réseau dépasse une taille critique, et que l’ensemble des tâches de raisonnement peut être traitée à travers le symbolisme du langage, en faisant manipuler au réseau la description textuelle de la tâche.
Pour la communauté scientifique, le modèle GPT-3 a tellement de paramètres que se pose maintenant la question de savoir s’il serait possible d’implémenter une machine de Turing avec un tel modèle de langage. Si tel était le cas, ce modèle aurait la capacité de résoudre toutes les tâches que l’on peut confier à un ordinateur. Mais, à ce jour, il n’existe pas de réponse théorique à cette question. Pour GPT-3, il n’y a pas non plus de réponse empirique ou pratique. Il est cependant certain que ce modèle marque un tournant et que la question sera reposée pour les modèles suivants.
Car les efforts pour créer des modèles plus puissants vont continuer.
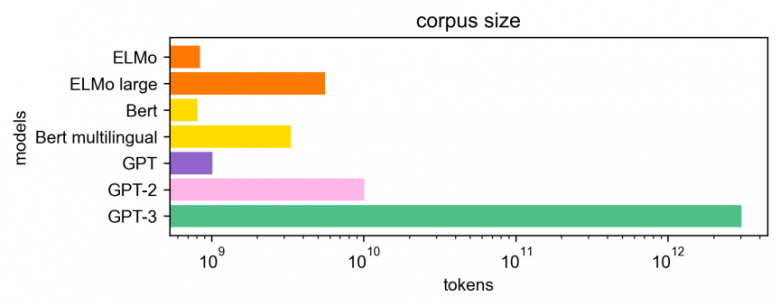
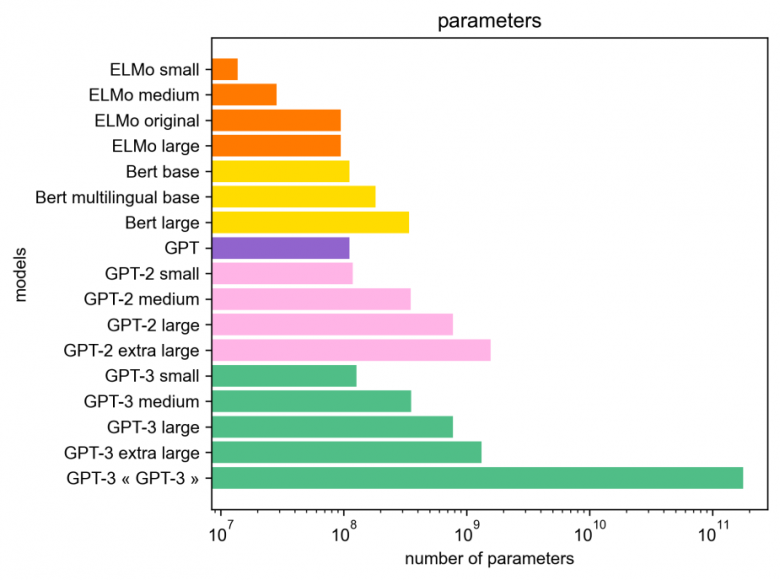
L’avancée marquante des modèles comme GPT-3 est qu’ils autorisent des approches dites “zéro-shot”, “few-shots”, “one-shot”, ne nécessitant pas ou peu de données annotées spécifiquement pour chaque tâche [7]. C’est un avantage certain sur les modèles entrainés par apprentissage supervisé, qui nécessitent des données d’entrainement annotées. En ce sens, on peut s’attendre à des avancées sensibles sur les tâches pour lesquelles ce modèle est bien adapté, comme par exemple en génération. Il faudrait aussi le tester sur des tâches proches, comme celles du dialogue ou des tâches plus éloignées comme l’extraction de relations. On pourra aussi s’intéresser à la capacité du modèle GPT-3 à être entrainé ou adapté à d’autres langues que l’anglais ou à plusieurs langues à la fois (multi-langues). Vu le volume des données en anglais qui a été nécessaire pour entrainer le modèle d’origine, cette question reste ouverte pour les autres langues moins bien dotées, y compris le français.
Benoit Favre, chercheur au laboratoire LIS de l’université Aix-Marseille avec qui Orange collabore régulièrement, partage ici son avis.
“GPT-3 a-t-il permis de découvrir l’IA généraliste ? L’avancée spectaculaire qui lui est associée ne vient pas tellement de ses capacités à générer des textes, mais plutôt de réaliser des tâches après avoir été exposé à un très petit nombre d’exemples (“few-shots learning”), sans que le réseau de neurones sous-jacent n’ait été supervisé explicitement à cette fin. Le lien entre une supervision de type ‘prédire le mot suivant’ et l’émergence de telles capacités reste une question ouverte fondamentale pour la communauté. On ne sait pas, par exemple, si ces capacités proviennent de la supervision du modèle de langage, ou de l’architecture des ‘Transformers’. On ne sait pas non plus si le modèle mémorise les données qu’il reçoit en apprentissage et ne représente qu’une mécanique élaborée pour rappeler ces dernières. Il a été démontré que GPT-3 peut réaliser quelques tâches linguistiques, peut générer des programmes, ou encore jouer aux échecs, mais il ne sait pas faire des opérations arithmétiques simples (et est probablement un piètre joueur d’échecs). Ces observations posent la question de la généralité du phénomène et de la nature des tâches qui peuvent être dérivées du modèle. De plus, comme ça avait été le cas lors de la ‘découverte’ des régularités linguistiques dans les espaces d’‘embeddings’ de mots, la communauté s’intéresse surtout à des exemples choisis qui ne sont pas très représentatifs des capacités globales du modèle. D’un point de vue traitement du langage naturel, GPT-3 étend des approches relativement conventionnelles avec des modèles plus grands entraînés sur plus de données. Il n’est pas clair aujourd’hui comment aller au-delà de la distribution de ces données tirées du web, comment exploiter le modèle en dehors de l’anglais, une langue surreprésentée, et comment adresser la diversité des langues. Un autre problème lié à la représentativité distributionnelle est celui des biais, en particulier sociétaux, que les modèles de langage ne font que reproduire. Toutes ces questions étaient déjà présentes avant GPT-3 et restent d’actualité. Quant à l’intelligence qui serait associée à GPT-3, la communauté est divisée sur la nature textuelle des données qui ont servi à l’entraîner. Ce qui est sûr, c’est que GPT-3 repose la question de la nature de l’intelligence, et ouvre la voie à de nouvelles pistes de recherche au-delà du TAL, par exemple en sciences cognitives sur l’émergence des capacités du cerveau humain.”
Mais des enjeux sociétaux
Les modèles comme ELMo, BERT, GPT-2 avaient ouvert l’horizon des possibles et, par leur libre disponibilité, avaient stimulé voir accéléré la recherche mondiale. Le nombre des publications scientifiques citant ces modèles en témoigne. Mais les chercheurs ne peuvent pas disposer de GPT-3. OpenAI le propose en mode “as a service”, et développe une API pour l’adapter aux besoins applicatifs (“finetuning”). De plus, Microsoft s’est récemment réservé les productions d’OpenAI en achetant une licence d’exploitation exclusive.
On pourrait rêver de construire un modèle libre équivalent. Mais seuls quelques acteurs auraient les moyens de le faire. Vu la taille du modèle (175 milliards de paramètres, soit 1000 fois plus que les gros réseaux utilisés en image), il faut disposer d’une énorme capacité de calcul pour l’apprendre. En plus du coût financier à supporter (plusieurs dizaines de millions d’euros), cet apprentissage aurait un coût énergétique difficile à assumer [9] [10] [11].
A ceci s’ajoute le coût de l’utilisation de ces modèles. GPT-3 pèse 240 Go, il ne peut donc pas être déployé en production sans un cluster de serveurs GPU qui sont bien connus pour leur coût financier et énergétique.
La tendance actuelle est plutôt de limiter la taille des modèles, de faciliter le déploiement et de réduire l’empreinte énergétique. Pour cela, il est par exemple possible d’apprendre des modèles “distillés” qui sont des modèles simplifiés, appris en étant guidé par un gros modèle original. La méthode a déjà été appliquée avec succès sur GPT-2 et BERT par exemple [8]. Le coût de cette distillation reste néanmoins très important, et il nécessite d’avoir déjà entraîné le modèle original. Par contre, on peut obtenir des résultats assez encourageants, parfois meilleurs que le modèle de départ !
L’opacité des données d’apprentissage de GPT-3 soulève aussi des questions éthiques. Les corpus d’apprentissage ne sont pas librement accessibles et seuls les auteurs du modèle peuvent vérifier s’ils n’ont pas collecté des textes exempts de biais. Par ailleurs, il semble difficile d’atteindre de telles tailles de corpus sans utiliser une quelconque technique d’augmentation de données qui consiste à utiliser des textes qui contiennent une partie générée artificiellement et ainsi non issue de la production humaine.
Les Transformers pour le TAL à Orange
Chez Orange, certaines équipes travaillent au quotidien avec des modèles de type Transformer. Elles utilisent ces modèles pour traiter la plupart des problèmes du langage et du dialogue naturel, ceci en recherche, mais également depuis peu en production, pour l’analyse des opinions dans les remontées des clients [17].
Ces Transformers ont permis des améliorations significatives pour l’extraction d’information dans les remontées des clients, et ce dans plusieurs langues. La capacité multilingue des modèles BERT permet désormais d’envisager de déployer un modèle unique pour analyser les données issues de tous les pays où Orange a des clients. Parallèlement, ces modèles sont utilisés pour la compréhension du langage (“Natural Language Understanding”) et lors de benchmarks des services d’interaction déployés au sein du Groupe.
Les tâches de classification et d’extraction d’information (analyse de sentiment, détection de données personnelles, détection et identification d’entités nommées, analyse en dépendances syntaxiques, analyse sémantique, résolution des coréférences) appliquées aux données d’Orange ont toutes connu un saut qualitatif avec l’utilisation de ces modèles de langage contextuels. La compréhension de la lecture (“Machine Reading Question Answering”), qui consiste à interroger des documents par des questions, s’appuie également sur les Transformers. Les différents composants des systèmes de dialogue font également appel à ces dernières générations de modèles. Enfin, des Transformers encodeur-décodeur tels que GPT2 sont utilisés pour la génération du langage naturel afin d’aider les systèmes de questions-réponses à générer des réponses aux questions en domaine ouvert.
En conclusion
La sortie du modèle GPT-3 a marqué les esprits des journalistes qui ont relayé leurs espoirs, leurs doutes, leurs craintes auprès du grand-public. Elle a aussi touché la communauté scientifique. Cet article cherche à replacer cette sortie dans son contexte afin de poser des questions rationnelles sur ce modèle. Il répond aussi à certaines d’entre elles. Pour apporter des réponses à toutes ces questions, il faudra attendre que l’accès à GPT-3 soit libre d’accès. Néanmoins, les auteur(e)s espèrent vous avoir apporté un éclairage original sur ce sujet aussi passionnant que tous les sujets sur lesquels ils et elles œuvrent au quotidien pour une IA responsable et humaine.
En savoir plus
[1] Podcast le nouveau monde de FranceInfo, 11/09/2020, https://www.francetvinfo.fr/replay-radio/nouveau-monde/nouveau-monde-gpt-3-cette-intelligence-artificielle-qui-ecrit-des-articles-presque-toute-seule_4087053.html
[2] Le Figaro, 21/08/2020, https://www.lefigaro.fr/secteur/high-tech/gpt-3-une-intelligence-artificielle-capable-de-rivaliser-avec-ernest-hemingway-20200821
[3] MIT Technology Review, 14/08/2020, https://www.technologyreview.com/2020/08/14/1006780/ai-gpt-3-fake-blog-reached-top-of-hacker-news/
[4] Le Monde, 03/11/2020, https://www.lemonde.fr/sciences/article/2020/11/03/gpt-3-l-intelligence-artificielle-qui-a-appris-presque-toute-seule-a-presque-tout-faire_6058322_1650684.html
[5] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems.
[6] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[7] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Agarwal, S. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
[8] Distillation https://github.com/huggingface/transformers/tree/master/examples/distillation
[9] Libération, blog Hémisphère gauche, 06/08/2020, http://hemisphere-gauche.blogs.liberation.fr/2020/08/06/lintelligence-artificielle-generale-comme-propriete-privee/
[10] Conférence Sustainable NLP: https://sites.google.com/view/sustainlp2020
[11] Strubell, E., Ganesh, A., & McCallum, A. (2019). Energy and policy considerations for deep learning in NLP. arXiv preprint arXiv:1906.02243.
[12] Kevin Lacker’s blog, 06/07/2020, https://lacker.io/ai/2020/07/06/giving-gpt-3-a-turing-test.html
[13] Qasim Munye, 02/07/2020, https://twitter.com/QasimMunye/status/1278750809094750211
[14] Amanda Askell (compte Twitter), 17/07/2020, https://twitter.com/AmandaAskell/status/1283900372281511937
[15] MIT Technology Review, 22/08/2020, https://www.technologyreview.com/2020/08/22/1007539/gpt3-openai-language-generator-artificial-intelligence-ai-opinion/
[16] OpenAI est une entreprise fondée en décembre 2015 par des géants de la tech Elon Musk et Sam Altman, avec le support de Tesla, Amazon Web Services, Ycombinator, Peter Thiel, LinkedIn, avec un budget d’un milliard de dollars.
Elle se donne pour mission de faire de la recherche en intelligence artificielle généralisée (AGI) pour le «bien commun». Au départ association, elle s’est transformée en association à profit limité. Microsoft a investi assez massivement, et a récemment signée une licence d’exclusivité sur l’exploitation des modèles GPT-3.
En interne :
[17] https://hellofuture.orange.com/fr/progres-de-lanalyse-semantique-de-la-voix-des-clients/
[18] https://hellofuture.orange.com/fr/lintelligence-artificielle-expliquee-aux-humains/
[19] https://hellofuture.orange.com/fr/semantique-le-graal-de-lintelligence-artificielle/







