


“Savoir isoler la voix d’un locuteur est crucial pour de nombreuses applications, qu’elle soit une interface de requêtes ou utilisée dans un contexte de télécommunication.”
Le vocal reprend des couleurs
Atteignant en moyenne 200 mots par minute, la parole est l’un des modes de communication le plus rapide. Cette caractéristique en fait le moyen de transmission d’informations privilégié lors des interactions humaines. La récente crise sanitaire a bouleversé nos habitudes de communications en démocratisant le télétravail et les visioconférences. Les interactions vocales deviennent progressivement dépendantes des capacités de télécommunications de nos smartphones, ordinateurs, objets connectés…
Longtemps réservée aux échanges sociaux, la parole est aujourd’hui exploitée par la plupart des appareils numériques de notre quotidien. Le succès grandissant des assistants vocaux, introduits en France en 2012, a imposé la voix comme alternative solide aux interfaces homme-machine traditionnelles. Qu’ils soient dans les voitures, l’électroménager, les répondeurs automatiques, ces systèmes vocaux sont désormais omniprésents dans notre société.
Finalement, qu’elle soit utilisée en tant qu’outil d’interaction ou pour des communications interpersonnelles, la voix est cruciale pour de nombreuses applications, les microphones de nos appareils connectés n’ont jamais été autant sollicités. La voix se doit cependant d’être traitée avec précision car dans un contexte où ce mode de communication est intuitif pour l’utilisateur, les attentes de ce dernier sont importantes et l’expérience utilisateur peut drastiquement diminuer en cas d’incompréhension. Malheureusement, le son est une donnée organique particulièrement sujette aux interférences et avec des caractéristiques variant d’un environnement à l’autre.
Comment assurer une expérience utilisateur constante lors des sollicitations des interfaces vocales ? Comment limiter ces interférences et augmenter les performances des systèmes d’interaction vocale ? La suite de cet article détaille les résultats obtenus dans le cadre d’un travail de recherche de doctorat visant à améliorer les types d’interactions citées précédemment. L’approche adoptée dans ces travaux est celle de la séparation audio-visuelle de sources vocales, elle a fait l’objet d’une publication à la conférence Interspeech 2021[1].
Isoler pour régner
La séparation de sources vocales consiste à isoler une ou plusieurs voix parmi un ensemble de signaux acoustiques. Ce procédé fait aujourd’hui l’objet de nombreuses recherches tant ses applications sont nombreuses.

Figure 1: Illustration du principe de séparation de sources vocales.
Une première approche, adoptée notamment par les enceintes connectées, consiste à utiliser un système doté de plusieurs microphones répartis sur la périphérie d’un disque ou d’une sphère. Une telle configuration permet d’effectuer un filtrage spatial du son, c’est-à-dire isoler tous les signaux venant d’une même direction. Cette approche est cependant onéreuse et peu polyvalente du fait de la complexité du système d’enregistrement.
Des travaux de recherche plus récents se concentrent sur l’utilisation de réseaux de neurones profonds pour le traitement de signaux acoustiques enregistrés par un unique microphone. Cette approche tente d’imiter la capacité du cerveau humain à se focaliser sur une source sonore spécifique, un phénomène appelé le “cocktail party effect”.
Toutefois, se contenter d’un unique canal audio pour la séparation peut introduire des difficultés. La séparation de sources vocales est généralement appliquée sur des fenêtres de temps de l’ordre de quelques dizaines à quelques centaines de millisecondes. Dans ce contexte, il est difficile d’associer les voix isolées aux bonnes personnes au fil des itérations ; ce phénomène est connu sous le nom de problème des permutations[2].
Une solution au problème des permutations est d’utiliser une information visuelle en complément de l’information acoustique afin de déterminer avec constance quelle voix appartient à quelle personne. Cette approche est plus restrictive car elle nécessite une vidéo mais elle est appropriée pour de nombreuses applications comme la visioconférence ou les interactions avec des robots sociaux par exemple. Elle possède en outre trois atouts importants. Premièrement, il existe un lien exploitable entre la dynamique buccale d’un locuteur et le son produit par sa bouche. Ensuite, l’information visuelle n’est pas affectée par les interférences sonores, ce qui en fait une alternative fiable dans des environnements acoustiques peu favorables. Enfin, les informations visuelles et acoustiques étant partiellement redondantes, l’utilisation simultanée des deux sources aide à résoudre le problème des permutations.
Regarder pour mieux entendre
Tout comme le son, l’image est une donnée riche en informations mais difficile à exploiter. Il s’agit donc de déterminer quelles données extraire et comment les extraire. Dans le cadre de ces travaux, l’innovation provient de l’utilisation de la dynamique faciale des locuteurs. Ce choix est inspiré par la manière dont le cerveau humain traite les données issues des nerfs optiques. En effet, des recherches en neurosciences ont montré qu’il existe deux voies distinctes dans notre cerveau, la voie ventrale et la voie dorsale, qui sont responsables de l’analyse statique et dynamique des images respectivement[3].
La dynamique faciale est estimée à l’aide d’un algorithme de flux optique[4] capable de calculer la vitesse et la direction de déplacement des points d’intérêt du visage comme illustré sur la figure 2. Les algorithmes de flux optique sont de plus en plus prisés pour la reconnaissance d’expressions faciales[5] ou la détection du locuteur actif[6], deux applications proches de la séparation de sources vocales car se reposant fortement sur l’analyse des discontinuités de mouvement.

Figure 2: Illustration de la détection des points d’intérêts du visage et de la prédiction du flux optique.
A l’issue de l’apprentissage, le réseau de neurones est capable d’exploiter la corrélation entre le son produit par un locuteur et le mouvement des muscles de son visage afin d’isoler efficacement la voix de tous les locuteurs d’un environnement. Il reconstruit, pour chaque locuteur, un nouveau signal audio dépourvu d’interférences.
Cet apprentissage est effectué à l’aide de données synthétiques construites à partir de deux corpus de données : AVSpeech[7] et AudioSet[8]. Le premier est un corpus composé de vidéos YouTube avec un unique locuteur, le second est composé d’extraits audio de différentes natures, il est utilisé pour ajouter d’éventuelles interférences non vocales dans les données synthétiques. Il est ainsi possible de construire des échantillons avec un nombre connu de locuteurs et des bruits ambiants de natures spécifiques, permettant une spécialisation du système à des cas d’utilisations particuliers. Afin de mesurer la polyvalence de la séparation, le dispositif expérimental proposé vise à tester différentes configurations où le nombre de locuteurs visibles, le nombre de locuteurs audibles et la présence de bruit ambiant varient. Le signal audio d’entrée est systématiquement un signal mono échantillonné à 16 kHz.
Résultats
La métrique la plus couramment utilisée pour évaluer la performance d’un algorithme de séparation de sources est le taux de distorsion du signal (signal to distortion ratio ou SDR). Le SDR s’exprime en décibel (dB) et permet d’évaluer la proximité d’un signal isolé au signal de référence, un SDR élevé correspond à une prédiction proche du signal de référence et inversement. La métrique utilisée ici est le SI-SDR (scale invariant signal to distortion ratio). Très similaire au SDR, cette seconde métrique n’est pas sensible aux changements d’échelle, c’est-à-dire que l’amplitude du signal prédit n’est pas prise en compte.
Dans le cadre de cette étude, on suppose que chaque locuteur visible a un visage non occulté, qu’il n’effectue pas de mouvements brusques et qu’il est positionné de face sur plus de la moitié de l’échantillon.
Les résultats obtenus sont comparés avec deux références. La première, DPRNN[9], est un réseau de neurones utilisant uniquement les données audio pour effectuer la séparation de sources vocales. C’est, à ce jour, le réseau présentant les meilleurs résultats de l’état de l’art. Cette référence est intéressante car elle permet d’évaluer l’apport de l’information visuelle dans le processus de séparation. La seconde référence, développée par Ephrat et al.[7], est un réseau de neurones dédié à la séparation audio-visuelle de sources vocales utilisant les images statiques comme caractéristiques visuelles. Ce second algorithme s’inscrit dans les travaux ayant introduit le corpus AVSpeech, il est en ce sens une référence idéale.
Le tableau 1 montre que notre approche, notée “Orange”, conduit à des meilleurs résultats dans toutes les configurations testées. Ces résultats, obtenus à partir du corpus de données synthétiques, montrent d’une part que l’information visuelle permet effectivement une séparation plus efficace des voix, et d’autre part que l’utilisation de la dynamique faciale offre un gain significatif par rapport à l’utilisation d’images statiques.
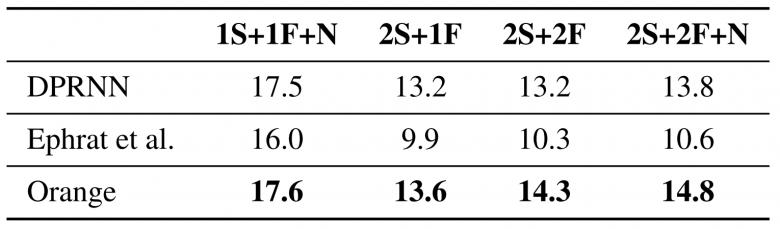
Tableau 1: Analyse quantitative et comparatif des performances de séparation de sources vocales exprimées en SDRi (dB) en fonction du nombre de locuteurs (S), du nombre de locuteurs visibles (F) et de la présence de bruit ambiant non-vocal (N)
La séparation de sources vocales présente de nombreux intérêts, le premier d’entre eux étant d’accroître la compréhension des voix humaines lorsque l’environnement sonore est peu favorable. Cette caractéristique en fait un atout majeur pour les visioconférences ou les reportages journalistiques par exemple.
Ensuite, l’isolation des sources permet d’améliorer l’efficacité d’algorithmes de traitement du son comme la reconnaissance vocale, l’identification vocale ou encore la classification de bruits. Une telle technologie permettra aux objets connectés de demain d’interpréter des requêtes sans qu’il soit nécessaire de les répéter.
Bien que le gain apporté par le traitement de l’information visuelle soit conséquent, il est nécessaire de se questionner sur le coût associé à une telle solution. L’analyse d’image est une tâche complexe nécessitant des ressources importantes, rendant ainsi une application en temps réel plus difficile. L’atout principal de la séparation audio-visuelle est qu’elle permet d’associer une voix à un visage, et donc à un individu. Si une telle capacité n’est pas requise, le traitement de l’audio seul peut représenter un meilleur compromis.
Il est à noter que l’étude réalisée ne prend pas en considération les cas où les visages des locuteurs sont occultés ou de profil. Un approfondissement de ces limites dans de futurs travaux paraît pertinent afin d’améliorer l’efficacité de la séparation en conditions réelles.
Bibliographie
[1] Rigal, R., Chodorowski, J., Zerr, B. “Deep Audio-Visual Speech Separation Based on Facial Motion”. Proc. Interspeech 2021, 3540-3544, doi: 10.21437/Interspeech.2021-1560
[2] D. Yu, M. Kolbaek, Z. H. Tan, and J. Jensen, “Permutation invariant training of deep models for speaker-independent multi-talker speech separation,” in ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing – Proceedings, 2017, pp.241–245.
[3] M. A. Goodale and A. Milner, “Separate visual pathways for perception and action,” Trends in Neurosciences, vol. 15, no. 1, pp.20–25, 1992.
[4] C. Bailer, B. Taetz, and D. Stricker, “Flow fields: Dense correspondence fields for highly accurate large displacement optical flow estimation,” CoRR, vol. abs/1508.05151, 2015.
[5] C. Huang and K. Koishida, “Improved active speaker detection based on optical flow,” in IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, vol. 2020-June, 2020, pp. 4084–4090.
[6] B. Allaert, I. M. Bilasco, and C. Djeraba, “Consistent optical flow maps for full and micro facial expression recognition,” VISIGRAPP 2017 – Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, vol. 5, pp. 235–242, 2017.
[7] A. Ephrat, I. Mosseri, O. Lang, T. Dekel, K. Wilson, A. Hassidim, W. T. Freeman, and M. Rubinstein, “Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation,” ACM Transactions on Graphics, vol. 37, no. 4, apr 2018.
[8] J. F. Gemmeke, D. P. W. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio set: An ontology and human-labeled dataset for audio events,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 776–780.
[9] Y. Luo, Z. Chen, and T. Yoshioka, “Dual-Path RNN: Efficient Long Sequence Modeling for Time-Domain Single-Channel Speech Separation,” ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing – Proceedings, vol. 2020-May, pp. 46–50, 2020.







