


In many real-life situations, decisions need to be made early, that is, problems need to be solved before they are completely understood. To give just one everyday example, if the weather starts to look uncertain, you might cancel the family picnic and go to a restaurant instead. But when do you make that decision? A decision taken too early is inherently uncertain, while a decision taken too late poses organizational problems.
Early decisions are also required in many use cases within the Orange Group, with the aim of taking actions as soon as possible:
- Before a customer definitively decides to go to the competition;
- Before a customer’s bank account is completely emptied due to fraud;
- Before a network equipment failure occurs and causes major disruption.

In many everyday examples, the timing of decisions is informed by the decision-maker’s “mental picture” of likely future situations.
So, When to Decide?
In such situations, the longer you take to make a decision, the clearer its probable outcome (e.g. whether or not a piece of network equipment is actually in critical condition) but the higher its associated costs — earlier decisions generally allow for better preparation. The goal is therefore to make a decision at a time that seems like a good compromise between earliness and quality.
Strictly speaking, delaying decisions tends to make them more reliable because there is an information gain over time — our understanding of the problem at hand becomes progressively more rounded and more accurate. To determine the best time to make a decision, you must therefore estimate this information gain and balance it against the cost of delaying the decision.
This dilemma of the earliness of a decision versus its quality has been a particular focus of study in the field of “early classification of time series” (ECTS) [1, 6, 7]. However, ECTS has limitations, which we will outline below, that restrict its scope of application. Thus, a more general problem, called , has recently been introduced [2] with a view to optimizing the decision times of machine learning models [5] in a wide range of settings where data is collected over time.
Why Is Early Classification of Time Series Limited?
The goal with this problem is to predict, as early as possible, the classification of a time series observed progressively over time. Although ECTS covers many applications, it does not extend to all cases where a machine learning model is applied to data collected over time, where the compromise between the earliness and quality of decisions must be optimized. Indeed, ECTS, as defined in the literature, is limited to the following situations:
- A classification problem (e.g. an anomaly vs. normal behavior);
- An available training set that contains complete and properly labeled time series (e.g. days of operation of a device);
- A decision deadline that is fixed and known in advance (e.g. end of day);
- Unique decisions for each time series;
- Decisions that, once made, can never be reconsidered;
- Fixed decision costs, which do not depend on the triggering time and the decisions made.
From ECTS to ML-EDM
The positioning article [2] aims, on the one hand, to overcome the limitations of ECTS and to define a more general problem called ML-EDM and, on the other, to develop this new field of research by presenting the scientific community with ten challenges.
Extensions of ECTS involve extending its early decision-making approaches to: any type of data set that evolves over time (e.g. texts, graphs, sequences); any type of learning task (e.g. regression, forecasting, unsupervised learning); and online processing of continuously observed data received in the form of data streams.
Beyond these natural extensions, a completely new learning problem has been formalized. Indeed, unlike ECTS, the ML-EDM problem involves “multiple early decisions to be located in time” [2]. There are therefore two challenges, since it is necessary to predict both what is going to happen next and the associated time period. In addition, decisions can be revoked if new data invalidates them, i.e., the prediction of what will happen next and/or the associated time period can be changed.
ML-EDM is therefore a much broader problem than ECTS, one which opens up many uses cases, including continuous system monitoring.
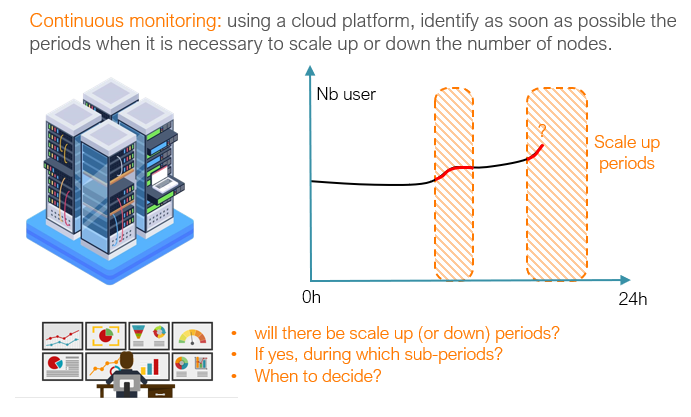
Example Use of ML-EDM for Continuous Monitoring
Non-Myopia: A Crucial Feature
In many everyday examples, the timing of decisions is informed by the decision-maker’s “mental picture” of likely future situations. For example, a pedestrian looking to cross an intersection estimates what the situation on the road will be in a few seconds:
- Scenario 1: There are only a few small, slow-moving vehicles on the road (e.g. a bicycle and a scooter) and, therefore, the risk associated with crossing the intersection now is low.
- Scenario 2: The pedestrian can’t currently see many vehicles but they can hear the loud noise of a motorbike accelerating, which causes them to be vigilant and will therefore delay their decision.
“Non-myopic” ML-EDM approaches [1] can anticipate this kind of unobserved information, in a given context. This is technically possible because these approaches are trained using “complete” example data sets where the outcome of these situations is known. By analogy, an adult, who has experienced many similar situations in the past, will be better at deciding when to walk across an intersection than a young teenager, who has little experience of this.
In practice, having non-myopia as a feature is crucial to obtaining better performances; in [1], this was proven to be the case for ECTS. However, developing non-myopic approaches in the more general context of ML-EDM is a considerable challenge and presents a promising avenue for research [2].
Conclusion
The article introducing the ML-EDM problem [2] was written in collaboration with several universities, namely, AgroParisTech, Télécom Paris, University of Porto, University of Waikato and Université Bretagne Sud. If you’re interested in learning more, a series of videos introducing the key concepts and challenges of ML-EDM is available on [3]. There is also a dedicated subreddit [4] for discussions on the subject. We encourage you to sign up! Tutorials and a Python library will be made available later this year.
Read more :
[1] Achenchabe, Y., Bondu, A., Cornuéjols, A., & Dachraoui, A. (2021). Early Classification of Time Series. Machine Learning, 110(6), 1481–1504.
[2] Bondu, A., Achenchabe, Y., Bifet, A., Clérot, F., Cornuéjols, A., Gama, J., Hébrail, G., Lemaire, V., Marteau, P. F. Open Challenges for Machine Learning Based Early Decision-Making Research. ACM SIGKDD Explorations Newsletter, 24(2), 12–31, 2022.
[3] https://www.youtube.com/channel/UCEUK7Q1gARRck1FB4Qo_3aQ
[4] https://www.reddit.com/r/EarlyMachineLearning/
[5] Mitchell, Tom (1997). Machine Learning. New York: McGraw Hill. ISBN 0-07-042807-7
[6] U. Mori, A. Mendiburu, S. Dasgupta, and J. A. Lozano. Early Classification of Time Series by Simultaneously Optimizing the Accuracy and Earliness. IEEE Transactions on Neural Networks and Learning Systems, 2017.
[7] A. Gupta, H. P. Gupta, B. Biswas, and T. Dutta. Approaches and Applications of Early Classification of Time Series: A Review. IEEE Transactions on Artificial Intelligence, 2020.







