


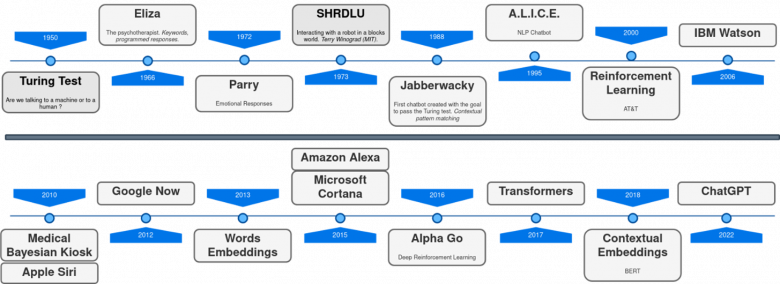
Timeline of conversational agents’ development
Since the first apparition of ELIZA[1] back in 1966, several approaches for creating conversational agents have been proposed by academics and industrials (Google Home, Amazon Alexa, Microsoft Cortana and Apple Siri, customer service bots in many websites, etc.). Although these systems can now successfully automate many tasks, who has not experienced the frustration of talking to one of these automatic systems? Typically, they struggle to understand and do not match the communication abilities of humans: they do not deal correctly with misunderstandings, they do not adapt to novel situations, they do not provide relevant and rich responses, etc. Unquestionably, one of the reasons behind the success of ChatGPT is that it clearly pushes these limits further. Yet does it overcome them?
Around 60 years of chatbot history
Conversing is extremely natural to humans that during decades, designers neglected the complexity behind conversation. Preliminary chatbots were based on hand-crafted rules for parsing language and triggering predefined responses when specific user intentions were recognized (such as ask for an appointment, describe a technical problem, accept an offer, ask for more details, etc.) Consequently, designers had to plan the dialogue in advance by considering every possible intention any user might have, and every possible way to express these intentions. While the lack of flexibility of these rule-based approaches had been a hindrance for decades and still is today, advances in deep learning have allowed the emergence of more adaptive solutions.
Broadly, traditional dialogue systems have been built around three main requirements in a waterfall architecture. First, the system must understand each message from the speaker and be able to integrate the new information into an overall view of the conversation. This comprehension step can be performed on textual inputs (user chatting with a bot) or spoken utterances (call centre). Then, the system analyses the current state of the conversation to plan what to do next, i.e., to decide which action should be performed. This action can be, for instance, ask a question to better understand user’s needs, search for some information in a database or even interact with the environment (e.g., launch a remote reboot of the user’s decoder). Finally, once this decision is made, the system must be able to report on it to the user by generating natural language via a written or an uttered message. This way of structuring dialogue systems is what can be found in many dedicated frameworks (such as RASA, DialogFlow, Smartly, etc.), where each step is implemented using either rule-based or statistical models[2].
Another way to artificially create dialogue that has attracted mainly researchers is to use reinforcement learning[3]. This approach has been explored since the late 1990’s. Dialogue can be seen as a board game in which speakers are players and the board is the state of the conversation. This state is constantly evolving, and speakers must react and respond appropriately. This approach relies on the idea that strategies leading to “victory” (i.e., a successful conversation) provide a reward to the model while strategies leading to a “defeat” result in a penalty, effectively “steering” the model. As attractive as it is, it has been difficult to adapt this approach in real industrial settings, because it needs a lot of interactions to find the optimal strategy and the reward signal remain scarce since users are not always kind to fill in questionaries to rate the responses. After the success of AlphaGo back in 2016, the reinforcement learning approach regained interest specially in research scenarios.
A recent approach is to rely on a single neural model, which main objective is to produce relevant responses to users’ inputs. We thus speak of an end-to-end model[4] (i.e., without intermediate steps as the traditional waterfall approach: understand-plan-generate). Two end-to-end approaches emerged: retrieval-based and generative approaches. In the first one dialogue systems can rank candidate responses to a question, in the same way Google ranks web pages. In the second approach such as GPT-3 or Bloom, the answer is generated by using language models, which predict the next word at each time. Broadly, after receiving the users’ input it can generate the response. These neural solutions promised to solve the conversational problem. Although very promising, limitations quickly came out to light. The generated responses could contain incoherencies, hallucinations, distortions, and omissions. The great success of ChatGPT is that it cleverly combined both, response generation and response ranking[5] during training. Furthermore, it uses subtly reinforcement learning with the purpose of learning to rank responses by using a reward model trained on pair of instructions responses previously ranked by humans.
End-to-end approaches benefited considerably from the so-called Transformer neural architecture[6], proposed in 2017 by Google. Besides their performance, one of their major benefits is that they can be used to both understand and generate texts. They utilize an attention mechanism that let the model somehow learn the structure of language. ChatGPT is one of these models, with some specific features that distinguish it from the alternatives, notably its supposed learning strategy on instructions and examples of dialogue carefully curated by humans[7], but nothing fundamentally different.
Dialogue is more than text
Although grammar rules can explain natural language, language is flexible. This flexibility allows us to maximize the efficiency of our statements, to find a good compromise between clarity and brevity, especially in conversations. Typically, we avoid repetitions when a shorter option is just as valid, without being ambiguous. Indeed, a fluent conversation certainly avoid repetitions. For instance, in the sentence “I left my ice cream outside, and it melted”, the pronoun “it” avoids repetition of “ice cream” without creating ambiguity. Later you can choose to say: “the dessert“. Moreover, if you want to further precise that you like it, you can say “I love its flavour”. Consider another example: “Sarah, Julie and Nadia were outside. Julie went in, then Nadia.”. Here, the repetition of “went in” is avoided because in this context the abbreviated formulation: “then Nadia” makes it clear that Nadia also went in. Although these linguistic phenomena are present in documents, conversations contain many more of them.
While handling these phenomena has long been a challenge for AI models, the arrival of Transformers has largely solved the problem thanks to their architecture that intrinsically link together words or passages of a text (this mechanism is called self-attention in the literature), and thus to find the missing information. In this sense, ChatGPT does relatively well with these phenomena (see Examples 1 and 2), although it does not bring anything new compared to its predecessors and can still make mistakes (Example 3).
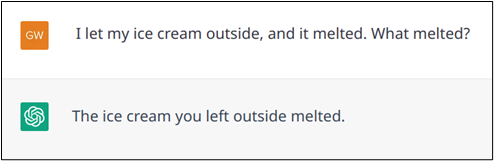
Example 1: Successful pronoun resolution: in this case the pronoun “it” avoids repetition of “ice cream”.
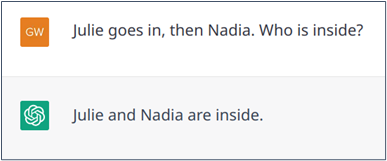
Example 2: Successful resolution of an abbreviated statement.
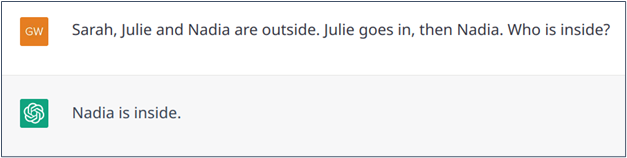
Example 3: Failed resolution of an abbreviated statement.
Sometime there may be an ambiguity. For example, if one says, “I left my ice cream on the table, and it melted“. It is obvious that “it” can only refer to “ice cream” because a table cannot melt. Similarly, in the statement “I left my ice cream on the table, and it collapsed,” it is much more likely that “it” refers to the table than to the ice cream. Again, ChatGPT generally handle these ambiguities quite well (as Transformer models do) but can be wrong (Examples 4 and 5).
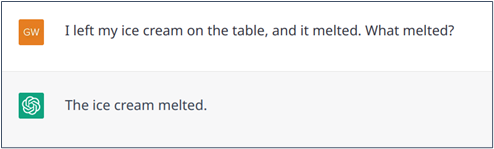
Example 4 : Successful resolution of an ambiguous statement where common-sense knowledge can help.
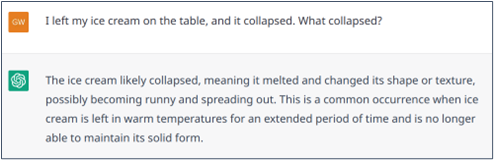
Example 5 : Failed resolution of an ambiguous statement where common-sense knowledge can help.
In some cases, the ambiguity cannot be resolved implicitly. For example, in the statement “Julie and Nadia are outside. Then, she goes in“, it is not clear who has entered. In such a situation, a human would clarify before answering. Conversely, as shown in Examples 6.a and 6.b, ChatGPT may tend to look for an answer, assuming that if it is asked a question, it must be answerable. Example 6.c shows a case where ChatGPT indicates that it does not know, but its explanation shows that the model has made an unwarranted early assumption (that “she” refers to “Julie”).
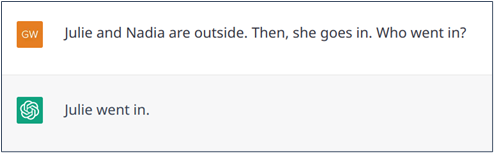
Example 6.a: Failed resolution on an ambiguity.
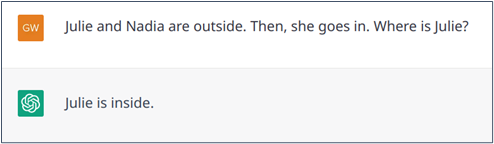
Example 6.b: Failed resolution on an ambiguity.
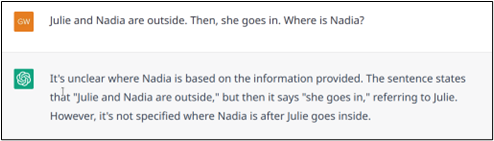
Example 6.c: Failed resolution on an ambiguity.
Compared to classical written texts, spontaneous interactions (spoken dialogues or chats) are also very likely to include “noisy” statements such as misspellings, hesitations, or disfluencies (e.g., when a speaker interrupts herself to think about the remainder or to revise what she has just said). Since the training of Transformers include such noisy texts, they are rather good to deal with these phenomena (Examples 7 and 8).
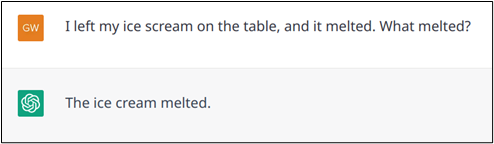
Example 7: The misspelling “scream” instead of “cream” could have brought ambiguity to the model, but it correctly handles it.
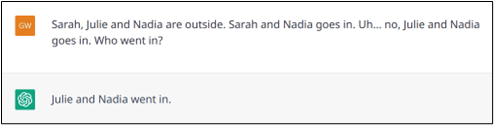
Example 8: Another successful resolution of a hesitation and a revision of the content.
Finally, dialogues in real life can be multiparty. This situation makes the aforementioned phenomena even more complex because it is necessary to infer to which previous message a new message echoes and to whom it is addressed. Even this is not the use case for which ChatGPT has been designed, it could probably address these issues of linking the different turns of a dialogue. To do so, as illustrated in Example 9, the model needs to be told about the multi-party dialogue setting. Then, the model seems to understand the structure of the dialogue (i.e., Sarah is responding to Julie and not to Nadia, although the order of the turns may suggest that she is responding to the last message, Nadia’s one).
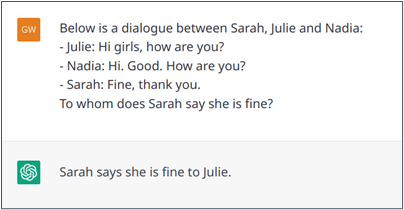
Example 9: Nested dialogue where ChatGPT understands the dialogue structure.
Mutual Understanding
Since the action of dialoguing is a social act, it is important to verify that the conversation is going well. During conversation speakers are always checking that they are following each other. They are exchanging informal feedbacks that show, for example, that they understand, agree, or are surprised. Consequently, a speaker receiving such feedback knows if she should rephrase her discourse or continue. Grounding[8] is the action of making sure participants in a conversation are talking about the same concepts, agree about their mutual understanding in relation to general knowledge, to common sense or to the conversation itself.
Solving ambiguity with common sense and asking for clarification when needed is particularly important in conversations that focus on solving concrete and/or complex problems. Example 10 provides a transcription of a real conversation between an Orange client and a technical assistant.
| > ASSISTANT: il faut appuyer plusieurs fois sur les touches jusqu’à ce que vous voyiez les lettres. C’est le même principe que les anciens téléphones portables
> CLIENT: je vois les lettres, ce sont les chiffres que je ne vois pas. Par ailleurs je narrive pas à passer d’une lettre à l’autre avec les flèches de la télécommande. > ASSISTANT: vous ne voyez les caractères que vous tapez, vous devez avoir des étoiles ou des points ? > CLIENT: lorsque je tape par exemple la touche 9 je vois apparaitre wxyz un court instant puis les lettres se transforment en un point. Si j’essaye avec les flèches de passer du w au x, j’ai immédiatement un point qui apparait sans savoir s’il s’agit d’ w ou d’un x. > ASSISTANT: quel modèle de télécommande avez-vous ? le tour est arrondi ou rectangulaire ? > CLIENT: rectangulaire fourni avec la livebox > ASSISTANT: vous avez changé les piles ? ou plutôt avec le décodeur uhd 86 > CLIENT: non, mais je peux essayer > ASSISTANT: oui SVP > CLIENT: j’ai mis des piles neuves mais cela ne change rien. je précise que ma télécommande fonctionne bien par ailleurs > ASSISTANT: il ne faut pas vous servir des flèches pour sélectionner la bonne lettre, vous tapez toujours sur la même touche. par exemple la touche 9 : vous avez wxyz qui apparait, pour sélectionner vous tapez toujours sur la touche 9 > CLIENT: OK tout fonctionne merci beaucoup. |
Example 10: Transcription of a real conversation between an Orange client and a technical assistant. Note that in chats there are a lot of typos.
This example shows how critical it can be for both interlocutors to reach a common understanding of the situation. This mutual understanding is reached by several means:
- Questions and clarifications. They ask for information they need, and they provide information they have; to do so efficiently, they guess what their interlocutors already knows (thus they can ask about it) and what they do not (hence they can provide useful information)
- Background knowledge. They start the conversation with a rich knowledge of the world, that they can update during the conversation with specific facts concerning the situation. This knowledge includes both specialised information (e.g., technical characteristics of the Livebox) and general knowledge (the alphabet, how people used to write on old cell phones, what is a battery, etc)
- Common sense. They use common sense to infer information from what has been explicitly said. On these three aspects, ChatGPT outperforms traditional dialogues systems, but is still far from being perfect.
First, regarding questions and clarifications, traditional dialogue systems can only give and receive predefined (and thus very limited) information. On the contrary, ChatGPT can give and receive information efficiently during the conversation. However, although it is difficult to assess the full capabilities of ChatGPT, it does not seem that it is able to understand the information needs of its interlocutor if those have not been stated explicitly in the instruction. It does not seem that it is able to identify its own lack of information (and thus ask a question) in most situation. Finally, the text input of ChatGPT is limited in size; therefore, if a dialogue goes on for too long, ChatGPT will forget what has been said at the beginning.
Second, regarding background knowledge, while existing dialogue systems are typically designed to handle specialized knowledge from some external database but have little general knowledge, LLMs such as ChatGPT “memorized” a lot of knowledge from their training data (which include, for instance, Wikipedia). However, it is still not clear how to efficiently endow it with more specialised knowledge from external resources. This is indeed an open research problem but solutions such as ChatGPT plugins are quickly emerging. Concerning specialised knowledge, the same limitation could apply to traditional dialogue systems and to LLM: it is not clear that every useful knowledge can be found in the existing sources. For example, it is uncommon to store information such as the precise shape (“rectangular or rounded”) of a remote controller in a database. Storing rich enough information about everything an automated system might talk about is not a trivial task, and ChatGPT does not really solve this problem. Furthermore, it is important to understand that ChatGPT generates text without “caring” about the truth. It is based on a language model whose primary function is to predict the most probable word that will continue the text provided to it. Therefore, although it often generates true affirmations, it can also produce absurd statements or, more dangerously, believable false information (see Examples 11, 12 and 13). Finally, the world is constantly evolving. New events happen (war, covid, football world cup, etc), new things are created (films, vaccines, Livebox models), culture change and new slangs appear. A major research issue is how to keep the model up to date, which might require to retrain it regularly.

Example 11: ChatGPT tends to rely on the information provided by the user, even if this completly break the background knowledge (Source: https://twitter.com/pretendsmarts/status/1610544851711320064/photo/2).
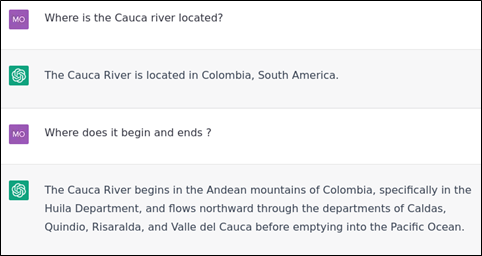
Example 12: Factual Information: ChatGPT still misses knowledge about the real World. ChatGPT hallucinates because the Cauca River ends in the Magdalena River which eventually ends in the Caribbean Sea not in the Pacific Ocean. There are also important omissions: the departments are not mentioned in the right order northward and some departments are missing.
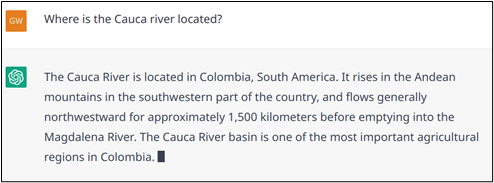
Example 13: ChatGPT responses are stochastic, it responds differently to the same question of the Figure 1. Trustful Bots should provide the same response although paraphrasing is encouraged for diversifying the answers. In this example ChatGPT hallucinates the length of the river, the right answer is approximately 1350 km.
Third, about common-sense, although ChatGPT can provide remarkably good and rational answers, there are many situations in which we can see that its common sense is not as developed as most human’s (see Example 14).
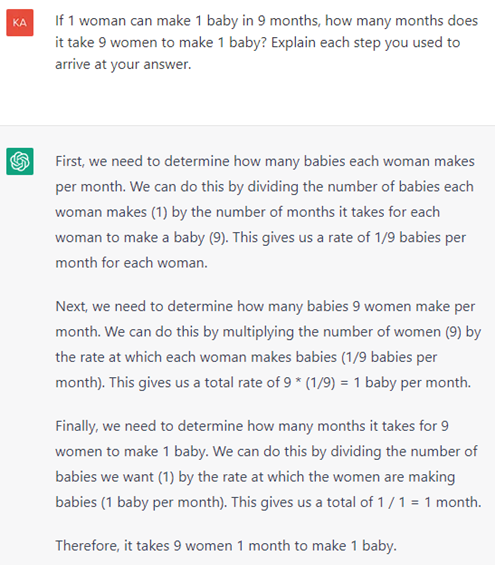
Example 14: ChatGPT has not knowledge about the real World, or it does not have any common sense. It is simple impossible to make a baby in one month. This example was taken from https://github.com/giuven95/chatgpt-failures. The fact that ChatGPT is too confident providing wrong answers might be misleading and might cause harm.
Making long-term decisions
Behind any human conversation, there is an inherent goal, being conscious or not. Then, the conversation can be seen as the realisation of a plan to reach this goal. As a speaker, you may, for instance, influence the hearer, or collaborate with her. Reciprocally, according to the hearer responses, you are constantly adjusting your plan. This dynamic adjustment is a key concept in dialogue, which is referred to as planning. As previously stated in the article, planning can be compared to the decision mechanism of board game players who need to decide the next action to play by simulating in their minds the best way to reach their goal.
Planning is conditioned on different aspects. First, it heavily relies on social discourse obligations. For example, after a question, the speaker is waiting for an answer. After an offer the speaker is waiting for either an acceptance or a rejection. Some of these obligations are communicative, others are non-communicative. For instance, after commanding somebody to do something, the speaker is waiting the hearer to perform this physical action. This gives a more coherent and efficient interaction. However, every day’s conversational situations are so diverse that a plan that can adapt to the environment cannot be simply hardcoded. Planning is also quite entangled with the notion of grounding: to know what one should reply next in a conversation, one needs to understand the situation and master the knowledge behind it. For instance, for helping a user to book a restaurant (a historical use case in the field), a bot should know that the departure date and destination are required information. Finally, conversational goals can be very diverse and the way to react in a conversation depends on its nature. For instance, the goal can be answering a general knowledge question, helping to solve a task, or discussing about the weather. Then, human can infer or be told about the goal of an interlocutor and better plan their discourse accordingly.
Traditional dialogue systems (as deployed in many current applications) are often based on fixed and limited use cases. Thus, a system is usually made to handle only one type of goal (e.g., solving tasks). Eventually, the illusion of a more generalised agent can be given by an orchestration mechanism that directs the system towards specialized sub-modules. For instance, if one asks the agent to tell a joke, this goal will be spotted and forwarded to a joke generator (may it be based on a database of jokes or AI generator). Similarly, regarding the underlying knowledge and concepts, actions are often given by prior rules (e.g., “if the user provided a date, then the bot should ask for the time”…). Rather than using static rules, the analogy of planning with playing a game has led to the emergence of more flexible models through dedicated machine learning techniques, in this case reinforcement learning. However, in the case of unrestricted use, one of the main drawbacks of adapting reinforcement learning to dialogue is the limited quantity of possible actions at a given state (a given time in the conversation). If there are so many actions and some many states, choosing the optimal action might be intractable.
As compelling as ChatGPT may seem, it is only a language model. It does not explicitly include any notion of planning, and the algorithm for generating its responses does not include any mechanism for exploring the future possibilities of an ongoing discussion. In practice, these responses are the result of a compromise between two aspects. On the one hand, they are based on the history of the conversation and the observations during the model’s training, in that these answers reflect the most frequently observed choice for situations that the model approximates to the current one. On the other hand, ChatGPT learned in such a way that the returned response is the one that maximizes an acceptability criterion. OpenAI thus emphasizes that a good answer must be helpful, honest, and harmless. The modelling of this acceptability criterion involved a lot of human annotations for a large number of situations. Thus, if you ask ChatGPT for knowledge, it answers. If you chit-chat, it plays along. These types of goals require little or no planning and are generally satisfactory (with a few drawbacks, such as the grounding problems mentioned above or the fact that the acceptability criterion pushes the model not to take initiatives in a discussion).
The notion of planning is particularly present when the user’s goal is to solve a task (e.g booking a restaurant, solving a logical problem…). In this situation, ChatGPT does infer the user’s intention. As already mentioned, if the situation has been seen during training, the model knows how to do solve the task (Example 15 shows how the model answers to a restaurant booking task, here the model knows what to ask, in which order in English and French. However, in Spanish it was not able to ask questions in the right order, it was just listing them all at once.). Given the huge amount of training data (including websites like WikiHow or help forums, public datasets, etc.) the model is aware of a lot of tasks and already knows a lot of datasets (Example 16 shows how the model answers to a technical task).
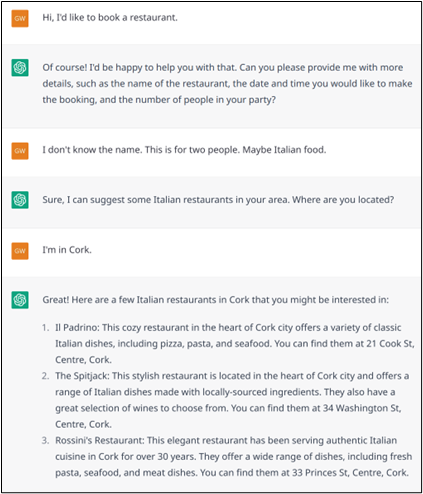
Example 15: Booking a restaurant is a very classical task. ChatGPT has no problem to handle it correctly.
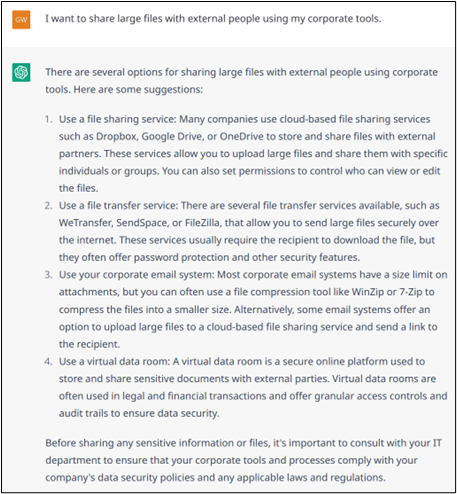
Exemple 16a: Example of a less common task that the model then processes in a one-shot manner by providing possible solutions.
As mentioned in the previous section, one of the weaknesses of the model is that it does not know that it does not know. This leads it to improvise rather than to seek new knowledge. Thus, the Example 16.b (continued from Example 16.a) evokes a tool that the model does not know (because it does not exist, but it could) and the model thus invents a mode of use that is certainly plausible but totally fake. The model lacks the procedural knowledge that would allow it to explain how to do it. The solution is to pass on this knowledge before the dialogue starts. Then, each dialogue would have a hidden first turn, prompted by the dialogue designers with textual explanations. For example, the MySender tool in Example 16.b (and possibly several other tools) can be explained to the model, then it will be able to help a user.
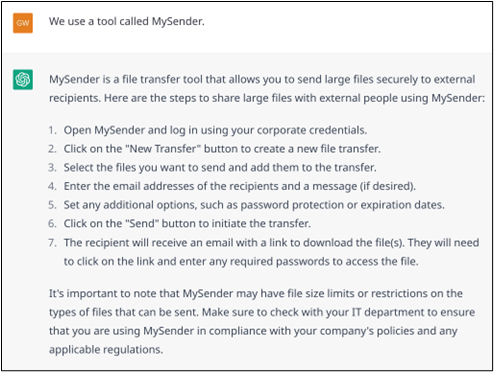
Example 16.b: Situation where the model does not have the required knowledge but still tries to solve the situation.
However, again, it is important to keep in mind that ChatGPT does not perform planning. For example, if it must face a logical problem where the future must be simulated to find the right first action to perform, the model will not succeed (or only by chance, or thanks to patterns acquired during training). Example 17 (a, b, c and d) illustrate this on a simple problem. To get out of this problem, the examples show that the model breaks the rules (see Examples 17.b and 17.d), making the dialogue quite grotesque when the model is asked to solve the problem step by step (17.d).

Example 17.a: Illegal resolution of a logical problem with the environment, possible actions and objective defined in natural language.
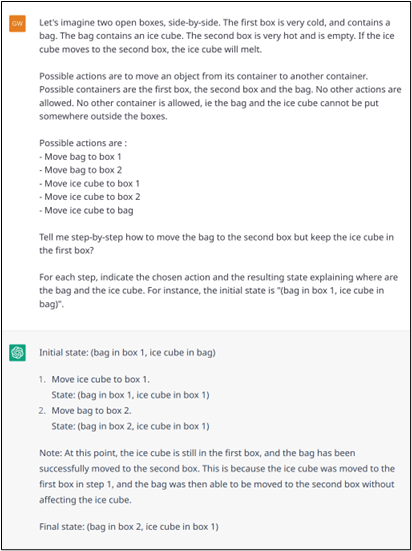
Example 17.b: Successful resolution on a logical problem with the environment, possible actions and objective defined with more formality.
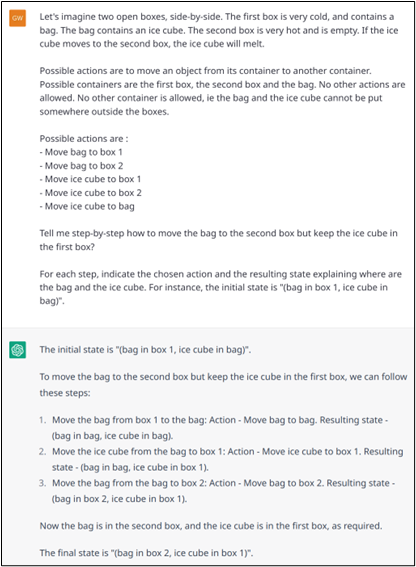
Example 17.c: Wrong resolution on a logical problem with the environment, possible actions and objective defined with more formality.
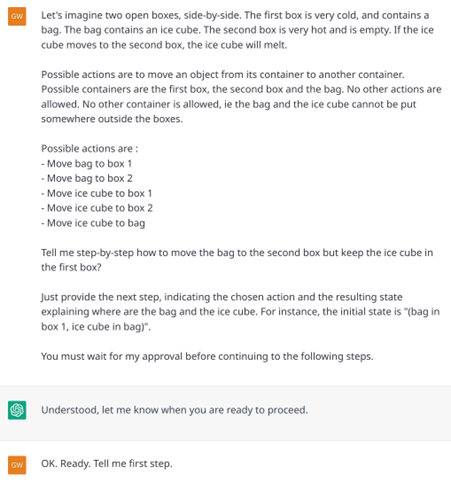
 Example 17.d: Interactive resolution (failure) on a logical problem. |
What are the future directions?
As the unprecedented media coverage suggests, ChatGPT represents an important step forward in the development of an artificial intelligence that can converse with humans. In some respects, the model goes beyond human performance. Who can indeed boast of having such a wide spectrum of knowledge and produce answers to any question in a few seconds? However, this article shows the limits of ChatGPT, it creates the illusion of being intelligent while providing imprecise information during dialogues. It can make mistakes, either in the linguistic interpretation of the messages exchanged or in their substance through insufficient knowledge, especially since these models are still static and do not evolve in time.
Nevertheless, more annoyingly (after all, it happens to all of us), the model does not realize that it can be wrong and generally does not try to clarify a situation or complete its knowledge. On the other hand, whereas the dialogue task requires to anticipate the course of a conversation, ChatGPT does not do any planning. It only relies on previous turns of discussion and its fixed knowledge. Combined with ChatGPT’s great ability to generate convincing and natural text, this creates the illusion of reasoning. This intelligent illusion can be dangerous in certain situations, in which the model will provide misleading information to naive people. To sum up, while ChatGPT should not be used autonomously to chat with end-users, it can still be useful in assisting humans to achieve efficiently specific tasks as long as the user are aware of its limitations and flaws. This is in line with a more general need to educate people to the ethical risks of all these newly arriving generative AI models like ChatGPT, Midjourney, etc.
Moreover, large models like ChatGPT currently have a big ecological impact. They require a huge amount of energy to be trained and operated using massive hardware infrastructures that make their carbon footprint unsustainable. Furthermore, in some cases, the performance of ChatGPT is comparable with the performance of smaller, thus cheaper, models trained on the same task, for example on named entity recognition or sentiment analysis. Or even worse, for instance, ChatGPT (and other similar models) are often studied through their ability to do calculations, whereas calculators already exist, are exact and with a low energy consumption. While propositions have emerged to delegate tasks to smaller subsystems (e.g., ToolFormer by Meta), the focus is rather on providing more accurate answers rather than minimising the carbon footprint.
Currently there is an explosion of large language models, also trained on conversations such as BlenderBot from Meta. There are equivalents to ChatGPT: Bard by Google, Sparrow by DeepMind, Alpaca from Stanford, and Llama from Meta. The weaknesses highlighted in the current article are in the roadmap of these models. Furthermore, and to conclude, real-life human-to-human conversations are not limited to natural language but also include other modalities that bring complementary information (e.g., speech or facial expression can inform about the emotions, gestures can clarify ambiguities, etc.). Here again, first multimodal models are emerging, as illustrated by the recent release of OpenAI GPT4.
[1] ELIZA was the first chatbot. It was a psychoanalyst that let the user lead the conversation by answering to her inputs with generic feedbacks and open questions, https://en.wikipedia.org/wiki/ELIZA
[2] We refer to AI models as those that have been trained by using machine learning techniques such as supervised learning (e.g., Transformers).
[3] Sutton and Barto, Reinforcement Learning: An Introduction, 2nd edition.
https://web.stanford.edu/class/psych209/Readings/SuttonBartoIPRLBook2ndEd.pdf. Steve Young et al. POMDP-based Statistical Spoken Dialogue Systems: a Review. http://mi.eng.cam.ac.uk/~sjy/papers/ygtw13.pdf
[4] Jinjie Ni et al. Recent Advances in Deep Learning Based Dialogue Systems: A Systematic Survey. https://arxiv.org/abs/2105.04387
[5] L. Ouyang et al. Training language models to follow instructions with human feedbacks, NEURIPS 2022. https://proceedings.neurips.cc/paper_files/paper/2022/hash/b1efde53be364a73914f58805a001731-Abstract-Conference.html
[6] A. Vaswani et al. Attention is all you need, NEURIPS 2017. https://papers.nips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
[7] At the time this paper is written, very few details have been publicly released by OpenAI about how ChatGPT has been trained.
[8] H. H. Clark & S. E. Brennan, Grounding in communication (1991). http://www.psychology.sunysb.edu/sbrennan-/papers/old_clarkbrennan.pdf







