“On the Internet, nobody knows you’re a dog” was the caption for one of the most famous New Yorker cartoons (drawn by Peter Steiner in 1993). More than 20 years later, assurance of user identity remains a challenge, and user impersonations are more frequent. Now, Web Real-Time Communications (WebRTC) is adding Web users to the already fragmented landscape of communication services.
WebRTC is a disruptive HTML5 technology driven by Internet companies such as Google and Mozilla, as well as by telecom equipment manufacturers such as Cisco and Ericsson. It aims to offer Web developers native browser tools for inserting real-time media exchange into their webpages, including browser-to-browser audio and video communication as well as data exchange (for example, for instant messaging or file transfer). In practical terms, this means users need no longer download, install, and manually configure an application or use some proprietary plug-in in the browser to communicate. The browser makers integrate all needed functions: codecs, management of exchanged streams, APIs, and so on. WebRTC leaves the signaling plan to service developers, who are free to implement a standard (such as the Session Initiation Protocol or the Extensible Messaging and Presence Protocol) or proprietary call-establishment protocol. WebRTC’s rise has generated several questions, including how users will verify the identity of other participants in a WebRTC communication and how to establish trust in users’ identities.
A Web user’s identity is basically an immutable link between a profile (such as a name, email address, and phone number), authorization rules, and credentials (for example, login/password) in a Web service. Although users trust their Web services, global trust and interoperability between providers doesn’t exist. Nevertheless, widespread single-sign-on (SSO) systems (such as Facebook Connect) let Web services retrieve user identity information from a dedicated provider. Here, user authentication is delegated from one Web service, known as the relying party (RP), to a third-party service, known as the identity provider (IdP). To date, the Web uses only a few SSO protocols to any extent, mainly OAuth2.0 and OpenID Connect. A more recent approach promoted by Mozilla and that hasn’t yet seen wide adoption is BrowserID.
User identities in WebRTC services can be involved in two different activities: User login (by which the Web service authorizes the user to log in) and user verification of the other users’ identity within a call (or any data transfer). Although user login is a matter for each CP, the RTCWeb working group is addressing methods to enable verifying user identities. In particular, the main question is how to provide Bob with Alice’s identity and vice versa so both of them can reliably decide to accept or reject the call; this is commonly known as identity provision.
The RTCWeb WG proposes decoupling identity provision from CPs via a third-party IdP so trust between users is only built on an external entity. Having a new player in the WebRTC model (the IdP) means new issues arise — that is, how to retrieve, deliver, and verify each participant’s identity.
To address these issues, the RTCWeb WG proposes a model that completely excludes the CP from the retrieval and verification of user identities: Alice’s browser obtains the user identity assertion from the IdP and attaches it to the call request. The CP merely forwards the identity. This model relies on a generic communication protocol implemented on the user’s browser that lets the browser retrieve user identity assertions from the IdP and verify them.
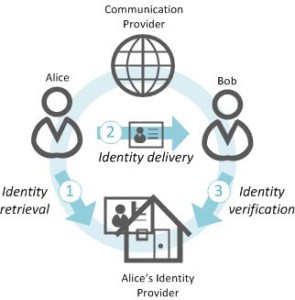
Although the WebRTC identity model claims to be protocol-independent, its architecture perfectly matches the SSO protocol BrowserID. This is due to the fact that BrowserID totally decouples the RP and IdP. The user’s browser becomes the central player that interacts with the RP and IdP separately. Moreover, the WebRTC identity model was conceived to work “without trusting the signaling site”. But what does this trust, or rather lack of it, mean? To the RTCWeb WG, it means that the CP isn’t going to participate at all in retrieving and verifying user identities (as shown in the figure above). Nevertheless, because it’s in charge of the signaling path, the CP can know the user’s identity (including any personal information in it) without the user’s consent. Furthermore, it isn’t clear that this non-trust model will be able to meet requirements of all use cases. Moreover, the user should have the last word about whether to trust the CP, and this will depend on each service case. To provide a broader view on identity provision, we describe two alternative models: partial (A) and full trust (B)
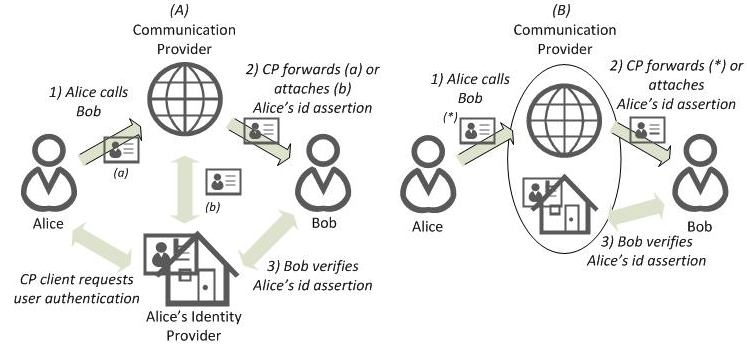
In the partial trust model, the CP might be involved in obtaining the user’s identity from the IdP. This model can be implemented by SSO protocols such as OAuth2.0 or OIDC. This model enables the CP to control the identity-provisioning process. A CP can choose to work only with a few preferred IdPs, for example, to only rely on trustworthy IdPs, or. In corporate communications, the choice of IdP will surely be subject to security policies, which the CP can enforce.
The full trust model is the most familiar to Web users — that is, placing full trust in the CP. In this case, users authenticate to the CP and trust it to deliver their identities to other users. This model is somewhat similar to legacy communication services, in which service providers manage both signaling and identity, and will thus be perfectly adapted for CPs providing in and out PSTN calls with asserted identities.
In conclusion, we prompt thus the community to promote a wider vision of identity in the WebRTC standardization that meets the needs of real Web applications — the requirements of identity for communication are different from those for SSO.
More info:
- This article is based on a recent paper published in IEEE Internet Computing, November-December 2014 issue: User Identity for WebRTC Services: A Matter of Trust
- An introduction to WebRTC and its issues for Telco services can be found in the following paper: WebRTC, the day after: What’s next for conversational services?