


Bias in AISs (Artificial Intelligence Systems) can lead to incorrect decisions or even discrimination that negatively affects individuals and social groups. For example, a recent study reveals that job descriptions created by generative AI convey far more stereotypes than those written by people. Therefore, job descriptions written by GPT-4o contain more bias than the work of a human. These concerns are becoming critical as become exponentially more popular. LLMs, which are used in various fields ranging from virtual assistance to content generation, are increasingly integrated into large-scale applications such as search engines or office suites. This massive adoption by users and businesses underlines the need to understand and manage bias to ensure fair and accountable systems. According to the Stanford 2024 AI Index Report, the number of scientific papers on fairness and bias has increased by 25% since 2022.
LLM bias can appear within the model’s internal representations as well as in final decisions. Bias in LLMs can be mitigated with or without additional training.
Regulatory issues
At the same time, the European Union regulation on artificial intelligence (AI Act), which came into force on 1 August 2024 and will begin to apply gradually, aims to regulate the development, marketing and use of AISs. The Act classifies AISs according to their risks, ranging from unacceptable risk to minimal risk. By way of example, any AI-based social scoring system is prohibited, an AIS that assists with recruitment or training tasks is classified as high risk and subject to additional requirements, and limited-risk chatbots are subject only to transparency obligations. “Appropriate” measures must be put in place for high-risk systems to detect, prevent and mitigate possible biases in the data sets used to train the models. These obligations are particularly important if the biases in question are likely to affect the health and safety of persons, have a negative impact on fundamental rights or lead to discrimination prohibited under Union law, especially where data outputs influence inputs for future operations. This means that a high-risk AIS, such as a recruitment or training assistance tool, is subject to these strict bias management requirements. In this article, we will take a closer look at managing LLM bias.
What is an LLM?
An LM (Language Model) is a statistical model designed to represent natural language. LLMs are advanced versions of these models, trained on vast data sets and using sophisticated architectures. Their ability to understand and generate text in a coherent and contextually relevant way is revolutionising applications, improving the performance of machine translation, text generation, sentiment analysis and human-machine interaction systems.
What is bias?
A bias can be defined as a deviation from the norm. In the field of AI, four broad families of norms have been identified and thus four types of bias: statistical bias (e.g. taking an average that simplifies the phenomenon in question), methodological bias (e.g. using a device that is not accurate enough to measure the phenomenon in question or using an LLM that has been trained on data sets that are not current), cognitive bias (e.g. making a subjective and irrational decision) and socio-historical bias (e.g. training an LLM on data sets from a single country and then using it in other countries with different worldviews).
LLMs are biased
Bias in AISs arises from the data sets used to train the model, from the architecture choices and from inappropriate usage. In LLMs, the huge scale of the pre-training data sets, the adaptation process (aligning with human values, specialising in a particular language or field etc.), the bias mitigation choice and the nature of the (e.g. what kind of roleplay) can cause harms of allocation (unjust distribution of resources) or of representation (reinforcement of stereotypes). Whereas harms of allocation produce immediate, easy-to-formalise effects, harms of representation produce long-term effects and are more difficult to formalise.
The development pipeline of is built mainly from two blocks: a basic model, developed to encode the language and its rules, and a second model, which is fine-tuned to respond to specific instructions (e.g. open questions/answers). This second model can then be further tailored to the desired task (e.g. customer relations chatbot) and/or aligned with stated values (e.g. adherence to a company’s ethical charter).
The pipeline of a generative LLM is as follows:
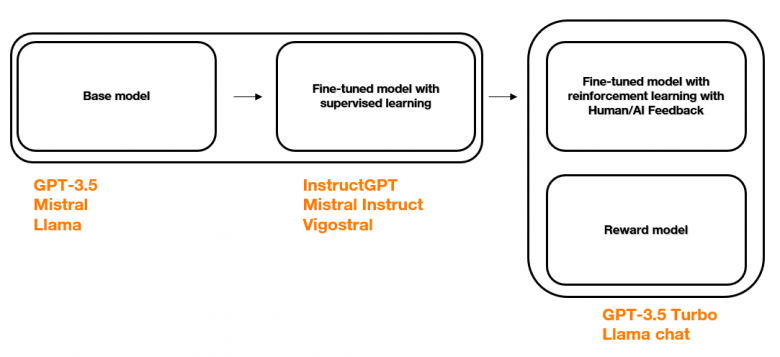
The biases in LLMs can therefore manifest both in the model itself (intrinsic bias, which occurs in the model’s internal representations) and in the final decisions it takes (extrinsic bias, which occurs in final decisions and predictions).
How to evaluate bias in LLMs
Bias in LLMs can be evaluated intrinsically and extrinsically. Intrinsic methods include analysing relationships between words in the model’s internal representations or observing differences in how the model assigns probabilities to words. Extrinsic methods, meanwhile, focus on how the model performs at specific tasks. There are evaluation metrics specific to traditional NLP tasks that aim to measure the quality of LLMs on reference data sets or generated text. In addition, (comprising a test data set and NLP task-specific evaluation metrics) can be used to measure the quality and effectiveness of models on specific tasks such as machine translation, text generation etc. However, the test data sets used in the benchmarks can bring their own biases. The suitability of the benchmarks used is therefore a key issue when evaluating LLMs.
Mitigating bias
Bias in LLMs can be mitigated with or without additional training.
- Additional training may entail supervised or semi-supervised fine-tuning or methods to align the models with expected values (via reinforcement learning from human feedback or self-diagnostics). These methods make it possible to adjust models to reduce bias while maintaining their performance, but they are resource-intensive and can introduce new opinions, or new representations, and therefore new biases that are consubstantial with the new data added for these mitigation techniques.
- In the absence of additional training, techniques such as post-generation self-diagnosis[1] or prompt engineering can be used. These techniques, which do not require additional training, are simpler and require less expertise. They are therefore easier to implement. Post-generation self-diagnosis entails designing specific instructions to steer the model towards generating fairer and less biased responses. This is based on the model’s ability to evaluate its own outputs after generating them. Carefully formulated prompts, meanwhile, can force the model to adopt varied perspectives and avoid stereotypes. Prompt engineering with roleplay, where the respondent’s profile is specified (e.g. gender, education level), is also an effective method for revealing and mitigating certain biases. For example, by asking the model to answer a question as if it were an expert or a person from a specific social group, the bias implicit in the generated responses can be identified and corrected.
Vigilance and compromise are sometimes necessary to ensure that bias-mitigation actions do not harm the model’s performance.
Corporate action plan
All the above must be combined with appropriate governance, including establishing guidelines for managing bias, appointing ethics officers and managers responsible for training employees, and implementing active monitoring and development of technical tools. It is vital that the members of the teams involved in developing AISs are diverse.
Furthermore, several actions must be carried out on a case-by-case basis, depending on the use case, the deployment context and the people involved.
First, it is necessary to choose the fairness criteria and metrics and then to identify the NLP task underlying the use case and the known biases. Then, different LLMs should be compared using an existing benchmark or developing one ad hoc. Developing a benchmark requires collecting data, annotating it if necessary, defining the task and establishing how to measure that the task has been performed well on the body of data in question (evaluation metrics). Then it is a question of selecting the least biased (and sufficiently powerful) model by comparing the results of different models on the benchmark used. The last step uses prompt engineering to compare the results obtained on the benchmark with different prompts in an attempt to optimise the prompt, in accordance with the chosen fairness criteria. It should be noted that model performance may vary according to the parameters of the prompt (temperature[2], instruction[3], context[4], whether or not examples are provided[5] and system prompt[6]) and the role taken in the prompt. Testing and adjusting models according to specific use cases is therefore essential.
Conclusion
To sum up, managing LLM bias remains a complex and evolving subject. Although there are ways to evaluate (intrinsic and extrinsic methods, existing or new benchmark) and mitigate bias (with or without additional training), the area is not yet fully mature. Within companies, the focus is currently on organisation, developing prototypes and experimenting. Developing fair and accountable LLMs will undoubtedly help with their large-scale adoption.
[1] This technique is based on the model’s ability to evaluate its own outputs after generating them. The model uses predefined criteria to evaluate the quality and fairness of the generated output (e.g. give me the answer and tell me if it is biased). These criteria may include measures of bias, stereotyping or toxicity. If the initial output is deemed to be biased or inappropriate, the model can either adjust the output in real time or generate a new response that takes the evaluation criteria into account. The revised output is then validated to ensure that it meets the fairness and quality criteria before being presented to the user.
[2] Adjusting the temperature of the model allows you to control the creativity and diversity of the responses generated. Temperature is a hyperparameter that controls the probability of selecting subsequent words in a sequence. A low temperature (close to 0) makes the model more deterministic, while a high temperature (close to 1) increases the diversity of responses.
[3] Instructions provide clear guidance on the task to be performed. They should be written concisely and accurately to minimise ambiguity and guide the model towards a specific response.
[4] Context can be added to the prompt to provide general information that makes the instruction easier to understand. The context should be positioned at the beginning of the prompt in order to place the model in a specific framework and guide its responses.
[5] Providing one or more examples of the expected prediction can help the model understand the task. The example must be representative of the task and be positioned at the end of the prompt to maximise its impact.
[6] This involves adding guidelines to limit model responses to a specific format, thereby reducing noise and irrelevant responses.
NLP (Natural Language Processing)
An area of artificial intelligence that focuses on how machines understand and manipulate human language. It encompasses tasks such as machine translation, voice recognition, sentiment analysis, text generation etc.
A short sentence or text provided as an input to a language model to guide it in text generation. It can be used to specify the subject, style or constraints of the text to be generated. The prompt can influence the content and structure of the text generated by the model.
A specific type of language model capable of generating text autonomously. When you train an LLM like Llama, Bard or GPT-4, you teach it how to generate text based on a wide range of existing examples.
a benchmark is an ensemble comprising a body of data, tasks and ways of measuring that the task has been performed well on the body of data in question (evaluation metrics). Benchmarks measure the quality and effectiveness of models on specific tasks such as machine translation, text generation, sentiment analysis etc. They allow researchers and developers to determine how one model behaves versus other models based on objective and reproducible criteria.
 Christèle Tarnec
Christèle Tarnec
 Anais Bekolo
Anais Bekolo
 Emilie Sirvent-Hien
Emilie Sirvent-Hien






