Is it possible to identify one person whose data are scrambled among numerous data? Is it possible to cross multiple different anonymous data sources with different formats to reidentify one person? Yes it is and some articles have shown it. That’s why anonymization technologies are evolving to bring always more privacy guarantees and Differential Privacy is one of them.
Introduction
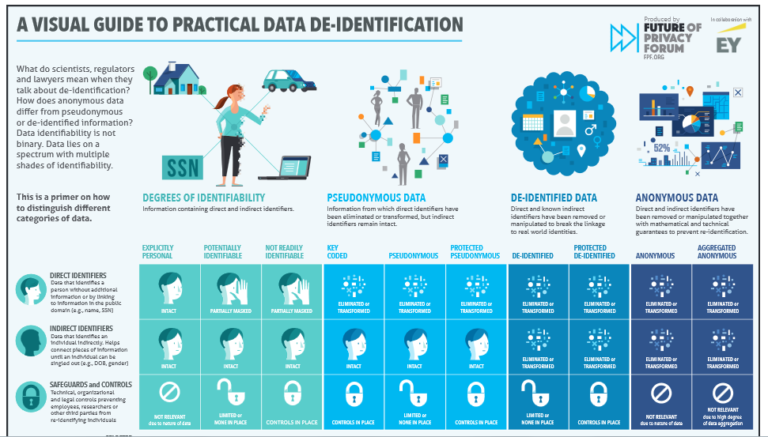
In the General Data Protection Regulation, which defines common rules in the European Union to manage personal data, we can read: “The principles of data protection should therefore not apply to anonymous information”. This encourages organizations to use anonymization technologies to develop data treatments such as statistics, open data publication for their internal use or external monetization. The G29 group has defined precisely features that de-identification technology should bear. To summarize, the opinion elaborates on the robustness of each technique based on three criteria: (i)is it still possible to single out an individual,(ii)is it still possible to link records relating to an individual, and (iii)can information be inferred concerning an individual? In practice such criteria are very hard to fulfill, and that is why research on those technologies is active. The figure below shows the wide range of different cases we can encounter when mining data and try to protect them from re-identification. In this article we will focus on differential privacy, a promising technology based on a mathematical framework, first introduced by Cynthia Dwork at Microsoft in 2006.
What is differential privacy?
Differential privacy proposes techniques to protect personal data by introducing random noise in datasets. This randomization ensures that the noisy datasets are independent of the participation of a single user. As a direct consequence, a customer may share personal sensitive data safely when this data is processed by differential privacy.
The privacy guarantee is mathematically proven and does not depend on any other information that an attacker could have. This is a crucial point since many data are publicly available today (social networks, …) and may be used to perform further correlations. In particular, differential privacy is insensitive to data crossing and linking attacks, which is in sharp contrasts with prior existing anonymization techniques such as k-anonymization.
An important feature of differential privacy is that the level of privacy is manageable. Indeed, the amount of noise depends directly on a parameter of the algorithm, which is called the privacy budget epsilon ε.
What can be achieved today?
Some key players have already announced practical usage of this technology, for example Apple, Google or Uber. Some others (4.5.5 paragraph) still need to be convinced.
At Orange, we can provide our own design of differentially private algorithms for a specific use-case, for which we obtain the best trade-off between privacy and utility, compared to state-of-the-art techniques. We have presented an instantiation of these anonymization techniques in the last Orange research exhibition, where we have used differential privacy to protect Orange customers privacy while performing data-mining tasks.
What are the main limitations?
The main limitation today is the lack of guidance and experience in choosing appropriate values for the privacy parameter epsilon, and the comparison to such a value to other privacy indicators (such as for example the parameter k in k-anonymization, which calibrates the indistinguishability of a single person data among at least k persons). Today research has just started the process of mapping the choice of ε to existing privacy regulations.
What is the role of Orange on this subject?
Orange is developing anonymization techniques compliant to privacy regulations. In research, we have studied specifically the case of graph anonymization. Multiple usage data (contact, mobility…) can be represented as a graph, but are still sensitive to re-identification and inference attacks in this graph form. Differential privacy is well-adapted to such a mathematical object, and permits to release a random graph, close to the original graph, that finds a clever trade-off between privacy and utility of usage. The challenge is then to optimize the algorithm to improve the trade-off privacy/utility, and that is what we improved. A patent has been applied for.
They are multiple other propositions regarding data anonymization, and the best solutions will probably be a combination of several techniques. This study is underway in a current French collaborative project named Adage with INRIA and CNRS.
What is the future of differential privacy?
As was the case in cryptography a few years ago, randomized mechanisms are going to be developed quickly in the coming years for applications in the area of data protection, so as to adapt to the new privacy regulations requirements. We discussed here the central notion for randomized anonymization mechanisms, which is differential privacy. To keep pace with the fast evolution of these techniques, we also study variants of differential privacy, such as geo-indistinguishability, a variation of differential privacy adapted to the obfuscation of locations, and the protection of mobility data.
Differential privacy is now at the heart of data anonymization processes, all intended to answer to a particular context with specific privacy needs, and requiring a privacy impact assessment and risk management processes.