

“We need to be able to answer one essential question in particular: how can we trust the decisions calculated by these AI-based systems?”
Awareness of all stakeholders: regulatory, business, society
Since 2018, through various studies, Europe has been promoting ethical AI by offering simple recommendations. In 2021, however, it will define a binding legal framework on the use of AI algorithms with the introduction of high-risk artificial intelligence systems [1]. At the same time, businesses are starting to implement AI governance. Orange, for example, having signed the first international charter for inclusive Artificial Intelligence [2] last year with the Arborus Fund, is now setting up its Data and AI Ethics Council [3] in order to support the implementation of ethical principles governing the use of data and Artificial Intelligence technologies. Last but not least, faced with the increasingly widespread use of AI, some public concerns have begun to emerge and there is a certain growing dismay with decisions made automatically by algorithms resulting from machine learning technologies. This means that an individual could find himself in a situation where he do not know whether a decision concerning them is based on human reasoning or the calculations of a machine. There are a great many examples, with varying degrees of intentional and unintentional impact on an individual’s personal life. The use of artificial intelligence systems can be detrimental in both material (health and safety) and immaterial (invasion of privacy) terms and can involve a wide variety of risks resulting from flaws in the overall design of artificial intelligence systems or from the use of data without mitigation of possible biases.
Develop trustworthiness as quickly as possible using a technoethical approach
In the context of the Fifth Industrial Revolution, with its focus on digital data and artificial intelligence, there is a growing awareness of the potential associated risks. Ethical principles resulting from thousand-year-old philosophical reflections must be respected. Some of them, however, can be reinterpreted and adapted to the field of AI with the aim of creating a system of digital ethics. We need to be able to answer one essential question in particular: “How can we trust the decisions calculated by these AI systems?” This notion of trustworthiness is key and must be taken into account as early as possible, starting with the design of the artificial intelligence system. A technoethical approach is what will enable us to answer this question. For the European High-Level Expert Group (HLEG) [4], a trustworthy artificial intelligence system must have three essential characteristics. It must be: lawful, respecting all applicable laws and regulations; technically and socially robust; and ethical, respecting a certain number of principles and values. Among the ethical principles to be followed, fairness and explainability can be factored in as soon as possible thanks to the collaboration of two key players, the product manager and the data scientist. In this context, the former is responsible for the design of an artificial intelligence system, while the latter is responsible for its development. Success will ultimately depend on the interaction between these two professions at each phase of the system’s development.
The Artificial Intelligence System and its 4-stroke engine
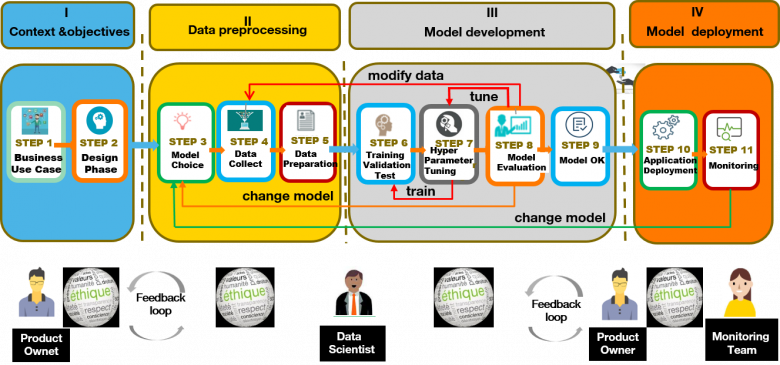
Each phase of the development lifecycle of any model must include ethical questioning and the dialogue between Product Manager and Data Scientist is essential.
First, the data scientist — dedicated to presenting the objectives and the usage context — must understand the ethical requirements that the product manager will ask them to integrate. These requirements relate to fairness (the nature of the differences in treatment to be addressed if there are risks of bias) and to the explainability of the model itself, or of the decisions made by it. The second step is to select the algorithms and data to train the model, with a risk of bias in these data. Thirdly, the data scientist develops their model by integrating the ethical requirements. In the fourth and final step, when the model’s performance is sufficient, it is integrated into the final service and then made available to users. The management of ethical issues must therefore be examined in each phase, but primarily in the specification phase and during the development of the system itself. Another determining factor, however, concerns the data used to construct the model.
First and foremost: quality data
Designing a model that is efficient but also ethical depends on the data quality. Stakeholders must be familiar with the data collection process and the process to ensure their representativeness (consistency with the actual operational context), compliance with the General Data Protection Regulation, and integrity (the introduction of malicious data in an AI system can change its behaviour). The following table provides the main metrics to be considered when developing a model:
| Metric | Questions to be asked by the data scientist | |
| Precision | Does the data have the expected precision? | |
| Consistency | Are the data consistent, without contradictions | |
| Accuracy | Are the data free of errors? Are there any missing data, or outliers? | |
| Availability | Are the data searchable and persistent over time? | |
| Compliance | Does the data comply with applicable standards, in particular the GDPR? | |
| Trustworthiness | Do the data come from trusted sources or organisations? | |
| Representativeness | Do the data contain the necessary information and in sufficient quantity | |
| Freshness | Are the data collected on the agreed date and at the agreed frequency? | |
Table 1: Some data quality metrics
Then prioritise together
Once the ethical requirements have been enumerated, the product manager/data scientist duo can rely on a criticality matrix. Depending on the context, the pair will define the severity and probability of occurrence of ethical issues. This matrix will help them prioritise the actions to be implemented according to the risks and their severity, as shown in the example below.
| Issue | Risk | Severity | Probability | Priority |
| Fairness
|
Treating people or groups of people differently according to their sensitive characteristics: gender, disability, ethnicity, sexual orientation, age, religion? | high | low | P2 |
| Explainability | Could providing a low level of explainability has critical or detrimental consequences? | high | high | P1 |
| Performance | Could providing a low level of performance has critical or detrimental consequences? | high | low | P2 |
| Multicultural team | Is the AI model at risk of being biased due to a lack of diversity among designers/developers (cognitive biases of those developing the model)? | low | low | P3 |
Table 2 The criticality matrix shows, in this example, that the highest priority is placed on explainability , followed by fairness and performance, while the presence of a multicultural team is not a priority.
During the model’s development phase, the data scientist integrates the ethical requirements into his code according to these priorities by reducing the biases likely to cause unequal treatment and by providing any necessary explanations for the understanding of either the model itself or the decisions made — the approval or denial of a bank loan, for instance.
What unfairness of treatment are we fighting?
While algorithms have been accused of reproducing certain biases, they can also help correct them. In the pursuit of fairness, artificial intelligence can be a formidable tool for the benefit of the fight against inequality [5], provided that the right strategy is chosen. The product manager must therefore ensure that the artificial intelligence-based system, once developed, does not go against the principles of a company charter or the regulatory framework with which the service must comply. It is the product manager’s responsibility to determine the type of fairness to be implemented (individual or group fairness), and it is the data scientist’s responsibility to develop an artificial intelligence-based system that meets this requirement. Individual fairness ensures that individuals with similar profiles will be treated the same; in other words, individuals are treated based on their own merits. Group fairness ensures that individuals are treated identically regardless of the group to which they belong. Group fairness can be obtained by preventing that disparate impacts (DI) affect certain groups, for example an unfavorable decision or by trying to obtain identical error rates for each of the groups and to prevent that Disparate Mistreatment (DM) affect certain groups.
Once the project manager has identified which type of fairness to pursue, the data scientist’s goal of ensuring fairness generally comes down to integrating a certain number of constraints into the optimisation program, allowing a decision-making rule to be learned from the measurable data. This can be applied to either the data used to train the AI model (pre-processing), the construction parameters of the model (in-processing), or the results of the model (post-processing). If group fairness is the target, to help choose the right strategy and algorithm, the data scientist can use a decision tree like the one below, which will help him to determine the right algorithm to use, depending on the chosen strategy.
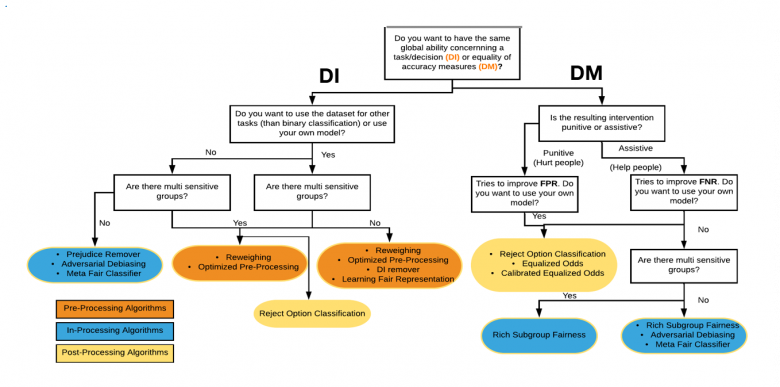
Choosing the appropriate algorithm to meet group fairness requirements (inspired by the tree suggested by the company Aequitas [6])
Which type of explainability ? A matter of context
The ability to explain how a model works and/or why it has made a given decision is the last requirement to be met because it assumes that the model is performing accurately and that the fairness issues are resolved. The need to explain is important for three main reasons: to achieve an ecosystem of trustworthiness sought by the European Commission, to be in compliance with the General Data Protection Regulation and to improve the security of artificial intelligence systems, especially in terms of cybersecurity issues.
Ideally, according to the principle of transparency, it should always be possible to provide a rational justification for any decision made with the help of an artificial intelligence-based system and to translate the calculations made into a form that can be understood by humans. But this is not always possible and, as explained in a previous article [7], a new field of research has emerged and many algorithms are now available that allow us to explain how predictive models work. In addition, implementations of these algorithms are starting to be made available in toolkits provided by various software vendors such as IBM’s AIX360 and AIF360, Google’s What-If Tool and Aequitas, developed by the University of Chicago. But choosing the correct explainability algorithm for each use case is a matter of context and balance between technical performance and ethical compliance.
To help choose the most appropriate method, our duo must consider the usage context of the artificial intelligence-based system. Several factors can help the data scientist to identify the most appropriate way to provide an explanation: the recipient, the impact of the system, the regulatory environment and the operational factors. Depending on the recipient’s profile, the explanations to be provided will be very different, as shown in the table below.

The explanation to be provided will vary depending on the user profile.
Let’s suppose that the data scientist develops an AI model to help select creditworthy bank loan applicants. He must develop a model that can be used to both explain to an applicant who was refused his request why his request was denied and help the auditor understand how the model works in general. To do this, he will choose both a “local” approach explainability algorithm to explain the individual decision and a “global” approach explainability algorithm to explain the overall functioning of the model. Beyond this choice, depending on the predictive model used, the data scientist can choose a directly explainable model or a specific explainability algorithm that he will use after training the model (post-hoc approach). Likewise, he can choose to use an explainability algorithm specific to the model developed or an agnostic algorithm that can be used with any type of model.
Based on the product manager’s expectations in terms of explainability, it is up to the data scientist to define the algorithm that provides the expected explanation. This can be done using a decision tree, as shown below, which shows the different solutions available. This method consists of navigating from top to bottom of this tree until the appropriate algorithm is identified based on the objectives.
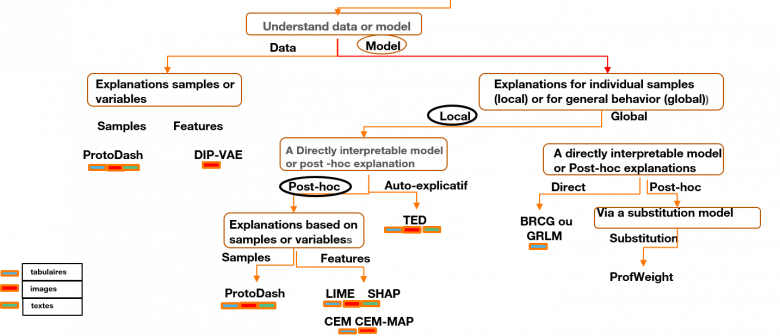
Algorithms for the explainability of AI models: sample decision tree from IBM [8]. The final leaves on the tree provide the available algorithms.
So we follow the path a, b, c, d, and finally e, which proposes one of the four algorithms available to perform this task, in this case the SHAP algorithm [9]. Once the data scientist has developed his learning model, he will use SHAP to provide an explanation.
Ethics affects all of us
Within the company, it is becoming necessary to introduce a real culture of ethics and to have all employees adhere to it. This is because a growing number of professions will be involved in the design of responsible AIS, beyond the product manager/data scientist duo. At Orange, digital technology must be responsible, sustainable and in its rightful place. Researchers are working on ethical AI, which addresses issues related to inclusion and environmental sustainability [10].
On the other hand, training in ethics and the societal impacts of technology should be included in training courses for engineers, helping to make it natural and obvious to take this dimension into account once they start working within companies and contributing to the design of new products.
In addition, for the past 10 years, awareness of the problems, raised by the increasingly widespread use of AI, has grown to effective levels and, in both the political and scientific arenas, much work and thought has been put into making artificial intelligence systems more understandable, fair and transparent.
Of course, strong AI is still in its infancy and there is no fear, in either the short or medium term, that it could produce artificial intelligence systems with omniscient artificial consciousnesses. However, those who like to speculate about dystopian futures could lead us, in the short term, to an algocracy based on the excessive use of AI and algorithms. We can bet that the European decision to integrate strong ethical requirements into the development of these systems will be part of the response to the challenges that await us.
Learn more
[1] white paper on Artificial Intelligence -A European approach to excellence and trust (PDF)
[3] https://www.orange.com/fr/newsroom/communiques/2021/orange-cree-un-conseil-dethique-de-la-data-et-de-lia
[4] HLEG High Level Expert Group on Artificial Intelligence Ethical Guidelines for Trusted AI https://ec.europa.eu/digital-single-market/en/high-level-expert-group-artificial-intelligence
[5] https://hellofuture.orange.com/fr/comment-lia-peut-aider-a-reduire-les-inegalites/
[7] https://hellofuture.orange.com/fr/x-ia-comprendre-comment-les-algorithmes-raisonnent/
[8] IBM AIX360 https://github.com/Trusted-AI/AIX360
[9] https://github.com/slundberg/shap ; voir aussi https://www.quantmetry.com/blog/valeurs-de-shapley/
[10] https://hellofuture.orange.com/fr/folder/dossier-salon-de-la-recherche-dorange-edition-2021-preparons-le-futur/
 Christèle Tarnec
Christèle Tarnec







