


The performance of AI models depends on both software optimization and hardware power. Analyzing the interactions between these two dimensions is a central issue in effectively rolling out generative AI on a large scale.
Memory bandwidth remains the main limiting factor, and current innovations are trying to get around this constraint.
Memory bandwidth is increasing much slower than computing power. It is by far the limiting factor of LLMs. All current optimizations are trying to compensate for this obstacle.
What Is a GPU and Why Is It So Important?
Generative artificial intelligence models, such as ChatGPT or Claude, are IT programs that are extremely computationally intensive. To operate quickly, they need specialized processors called GPUs (Graphics Processing Units) that can perform thousands of operations at the same time. A GPU can be considered a miniature computer dedicated to parallel computing. Unlike your computer’s CPU (Central Processing Unit) that processes tasks one by one, GPUs can process thousands of operations simultaneously.
A GPU has its own processing units, memory hierarchy and communication interfaces. This independent architecture allows the GPU to operate on its own once the data is loaded, without constant intervention from the host CPU.
For example, the NVIDIA H200 GPU contains:
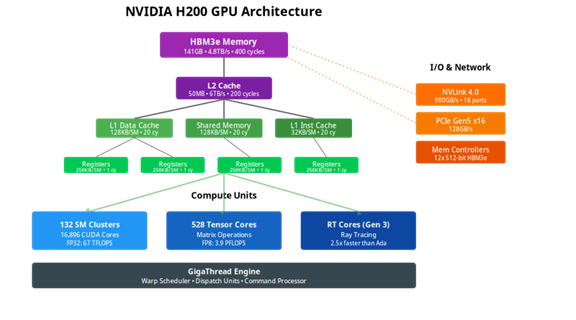
- 132 compute units working simultaneously
- 141 GB of high-speed memory
- Specialized connections to communicate with other GPUs
The following figure illustrates the architecture:
Memory — The Main Bottleneck
The major obstacle is not computing speed, however, but access to memory. By analogy, it would be like having a team of 1000 very fast workers, but a single elevator to bring them materials. The GPU’s HBM3e memory can transfer 4.8 terabytes per second. This is 40 times faster than connections to the computer’s main memory. This difference creates a major bottleneck during CPU-GPU transfers. Efficient inference systems therefore minimize these transfers by maintaining data on the GPU for the duration of processing. Each unnecessary transfer between CPU and GPU can slow down processing time by several orders of magnitude.
How Do Transformer Models Work?
Modern language models use a transformer architecture, which works in two phases during inference.
The prefill phase processes the entire input text at the same time to build the initial context. The generation phase then produces the output tokens sequentially. These two phases have contrasting computational profiles: The prefill is compute-bound, meaning it is constrained by the available computational power, whereas the generation is memory-bound, meaning it is limited by the available memory bandwidth. All the weights of the model must be transferred from the GPU’s memory to the registers through the memory caches. This difference determines the appropriate optimization strategies for each phase.
The Attention Mechanism
Attention mechanisms form the core of transformer architecture. For each token in a sequence, the model calculates three matrices called: Query (Q), Key (K) and Value (V). The query matrix represents what the current token is looking for, key represents the information each token offers and value stores the actual content to be transmitted.
The attention calculation works as follows: The model calculates scores by multiplying the current token’s query with all keys in the sequence. These scores are then normalized via a softmax function to obtain weights between 0 and 1. These weights are then applied to the values to produce the final output. The model uses several attention “heads” at the same time (submatrices for Q, K and V), each capturing different types of relationships in the text. This architecture allows the model to understand complex relationships, such as identifying what a pronoun refers to in a long sentence.
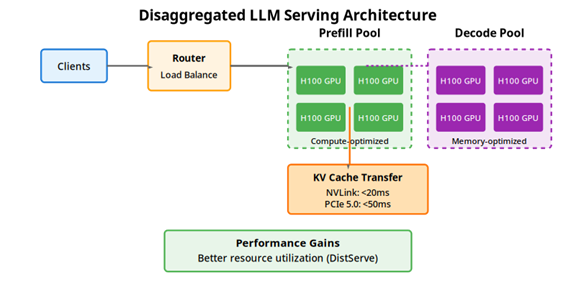
Figure: Disaggregated LLM Serving Architecture
Fundamental Optimizations
- : avoiding unnecessary calculations
Instead of recalculating the same information with each new word generated, the system stores the previous results in a KV cache. - FlashAttention: optimizing memory access
This technique combines several operations into one to eliminate unnecessary back-and-forths into the memory. Instead of making six data transfers, it only makes two, which improves efficiency from 35% to 75%. - : swapping precision for speedModels can operate with less numerical precision. Instead of using 32 bits per number, you can use 16, 8 or even 4 bits. This divides the model size by 2, 4 or 8, allowing more queries to be processed simultaneously.
The Challenges of Scaling: Tensor vs Pipeline Parallelism Strategies
Larger models do not fit on a single GPU. They therefore need to be distributed over several GPUs that must communicate with each other. Two main strategies exist. Tensor parallelism, or TP, divides each layer of the model between GPUs: Each GPU calculates a portion of each matrix operation and the results are combined. This approach requires constant communication between GPUs (after each layer), so high bandwidth is essential. Pipeline parallelism, or PP, assigns entire layers to each GPU: GPU 1 runs layers 1–20, GPU 2 runs layers 21–40 and so on. Data moves from GPU to GPU, like a production line. This approach requires less bandwidth but creates downtime when some GPUs wait for the results of others.
Hardware Specialization, Distributed Orchestration and Mobile AI for Improvements
As frontier models exceed a trillion parameters and context windows extend to millions of tokens, three trends are emerging clearly:
- Hardware specialization is speeding up.
Tensor cores, FP8 accelerators and architectures like Blackwell show that the era of the general-purpose GPU is coming to an end. Each new design is optimized specifically for transformers’ memory access patterns. Keep an eye out for the arrival of even more specialized circuits, such as Groq, Cerebras and Etched.
- Distributed orchestration is becoming critical.
With models requiring 8, 16 or even dozens of connected GPUs, the effectiveness of inter-accelerator communication directly determines economic viability. NVLink, InfiniBand and optical interconnects are no longer luxuries but necessities.
- Intelligence is moving closer to edge (AI on mobile).
Mobile chips are starting to run models of several billion parameters locally. This increased popularity of inference will radically transform human-machine interaction, eliminating network latency and guaranteeing confidentiality, but the capabilities of embedded models are still very limited.
Conclusion
The joint evolution of GPU architectures and transformer models has created a remarkable synergy that is fueling the generative AI revolution. Each level of hardware architecture—from high-speed registers to HBM3e memory—plays a crucial role in overall performance. Memory bandwidth remains the fundamental bottleneck, dictating optimization strategies at all levels.
Software innovations like FlashAttention, PagedAttention and quantization are not just simple marginal optimizations; they represent key changes in our approach to parallel computing. Transitioning from FP32 to FP8 or INT4 is no longer a compromise but a strategic necessity to deploy ever-larger models. Prefill-decode disaggregation shows that system optimization goes beyond simple hardware acceleration to fundamentally rethink the service architecture.
The central paradox remains: While computing power continues to increase sharply, memory bandwidth progresses linearly. This divergence is forcing constant innovation in algorithms and architectures.
For practitioners, the message is clear: Understanding the interaction between hardware and software is no longer optional. Technical decisions like choosing between FP16 and INT4, between tensor and pipeline parallelism, between vLLM and TensorRT-LLM determine whether a service will be economically viable or not. A model of 70 billion parameters can cost €0.01 or €1 per query depending on the implementation.
The immediate future promises fascinating challenges. MoE (Mixture of Experts) architectures like Gemini 3 Pro show that certain limitations can be circumvented by selectively activating parts of the model. But in the short term, optimizing what already exists—reducing every unnecessary memory transfer and maximizing the use of each GPU cycle—remains a daily challenge.
We are at an inflection point where deep understanding of these systems separates successful deployment from costly failures. Effective inference is not just a matter of performance; it is the key that unlocks the transformative potential of generative AI for real-world large-scale applications.
4.8 TB/s :
Bandwidth of the NVIDIA H200. The memory throughput of a high-end GPU card is 5000 times higher than that of residential fiber.
Sources :
– [NVIDIA H200 Architecture Whitepaper] (https://www.nvidia.com/en-us/data-center/h200/)
– [FlashAttention 2] (https://arxiv.org/abs/2307.08691)
– [vLLM: Easy, Fast, and Cost-Efficient LLM Serving] (https://vllm.ai/)
Read more :
– [Attention Is All You Need: Transformer architecture] (https://arxiv.org/abs/1706.03762)
– [A White Paper on Neural Network Quantization] (https://arxiv.org/abs/2106.08295)
– Orange Research Blog Tickets: Is ChatGPT a human-like conversational agent? – Hello Future







