


- Users are all different. Some have no particular constraints but have usage habits and preferences. Others, such as people with disabilities or seniors, may have, in addition to those habits, constraints when using a digital service.
- These constraints can be very diverse, of a perceptual nature (visual, auditory, tactile), of a motor nature (pointing, manipulation, speech) or cognitive (comprehension, reading). However, it is hardly conceivable to anticipate all of them when designing a service.
- What if any service, or any interface, could continually adjust to users’ usage habits and constraints? This is where a Machine Learning algorithm can prove highly relevant.
The need for personalised digital interfaces
It is evident that digital technology has become ubiquitous in society, with users and use cases becoming increasingly diverse, but that has led to the emergence of obstacles to using services, some of which completely block a significant portion of the population from accessing them.
The adaptive and original implementation of a non-parametric Bayesian approach makes it possible to meet the requirements of adaptive interfaces in terms of robustness and learning from little data.
With that in mind, how should digital interfaces be designed to meet as many people’s needs as possible? Or rather, how can all services and interfaces be made accessible for every individual who uses them? In other words, how can they be made simultaneously perceptible, manipulable, understandable and robust? At present, the typical response to this is to seek compliance, mainly from a technical perspective, with WCAG 2.2[1], including compatibility with assistive technologies (screen magnifiers, screen readers, Braille display etc.). That, however, involves many settings that users may find overly complex when using the interface. Moreover, this standardised approach to accessibility, while necessary, does not account for usage habits, such as the more or less frequent use of a particular service or function, or usage based on different strategies for certain services or functions. In view of that, and with the aim of enhancing the usability of its products and services, Orange is conducting research into an approach where the interface adapts to the specific needs of the current user. This approach is based on interface personalisation, as defined by Simonin & Carbonell [1]. These needs may be related to sensory, actional, cognitive constraints linked to impairments, or to particular contexts (little or no light, ambient noise, sitting position, multi-tasking, stress etc.). These needs may also be related to usage habits, which current digital services and tools rarely take into account. Moreover, an adaptive interface should allow user experience to be modified to meet their specific needs by configuring the layout [2], content or functionalities of the system. This personalisation may involve moving elements in an interface to reflect their priorities, highlighting their preferred interface elements and usual paths, and anticipating their actions etc.
Adaptive system and interaction model
More generally, an adaptive system will be defined as a system capable of automatically or semi-automatically modifying its characteristics according to the user’s needs for a defined use in a specific context. This will include taking into account the diversity of:
- user profiles (their preferences and physical capabilities),
- their usage habits or usage strategies (task models),
- the environmental contexts in which they evolve.
Research on interface personalisation [3] [4] [5] has shown that users often fail to configure/personalise their interface themselves, and that they would like assistive tools built into the system to help them establish their own user profiles and learn what their user habits are (and how they change over time) and how usage contexts vary. This paradigm has been explored for specific applications, such as browsing the news on a smartphone [6], to facilitate navigation and go beyond content recommendation: “People like you who did that then chose this”. It is based on an interaction model designed as an extension of the user profile: “You usually do that and will probably choose this”. Its generation involves, on the one hand, continuous capture of user activity (which buttons they select, which links they click, which menus they use etc.) and, on the other hand, heuristics or a predictive model created by a machine learning algorithm capable of inferring the characteristics of the user profile over time. For example, in Constantinides & Dowell [6], the inference of the three so-called “high-level” characteristics (such as the user’s navigation strategy) uses a predictive model (of the classifier type) that has been trained offline based on labelled data from a corpus of “activity logs”. However, this type of approach is not very flexible or adaptable in response to behavioural changes over time. As such, the aim of Orange’s research is a more flexible approach where the model’s learning happens over time. Far removed from Big Data and generative AI, this research is concerned with “Small Data”, i.e. the specific data gathered from the user and for their personal use. The system uses this activity data to generate a probabilistic task model that is continuously updated. It is the foundation of how the experience is personalised. In terms of [2], it focuses on a personalisation paradigm that would allow the user to better navigate their interface and act more easily according to their own usage habits. In particular, it will be necessary to compile interface usage statistics for each habit, and each constraint specific to each individual, in order to give the user the option of adjusting how they use the service. This would involve either guiding them on their usual paths (e.g. with highlighting) or making the interface more efficient (by reorganising it or creating shortcuts). For this objective to be achieved, algorithmic difficulties in designing and implementing this paradigm, and then ergonomic difficulties, must be resolved.
Algorithmic problems in personalisation
An operational implementation would require automating the generation of the interaction model, and the model would need to evolve over time, so that it continuously adjusts to the changing behaviour of the user. How, then, can an application automatically create and continuously update an interaction model specific to the current user? To answer this, we start from the principle that the predictive model must satisfy several properties, particularly in terms of [3] and continuous learning, which is not without difficulties. In machine learning, predictive models are generally static [7]. They cannot adapt over time [8] or can only adapt marginally through “fine tuning” techniques [9]. In fact, they regularly need to be retrained. But in a dynamic environment that changes regularly, such as one based on human behaviour, this approach is inappropriate. This is why the emerging field of “Continual Learning”, also called “incremental learning” or “lifelong learning” [10] [11] [8] [12], studies algorithms capable of learning continuously in a changing environment, with the ability to retain and accumulate past knowledge, to be able to draw inferences from it, to use this knowledge to acquire new knowledge more easily and thus solve new tasks. More precisely, it is a question of developing sequential learning capability. This property is generally associated with continuous learning. It is of crucial importance in the context of human-machine interaction. Unlike classical learning where all tasks are learnt simultaneously from a balanced dataset, in sequential learning not all tasks are present in the data at the same time, as some will appear later, or even disappear after a certain period. The whole challenge is to have a predictive model capable of learning new tasks without having to replay past data, which implies keeping previous learnings in the model’s memory. The solution to this problem of continuous adaptation of the interface is centred around autonomous systems learning from a continuous data stream [8].
Orange researchers are particularly interested in self-supervised incremental online learning. This means that only one example is presented at a time to update the predictive model [12]. Such systems therefore continue to learn after their deployment, autonomously and economically. However, this new field, very oriented towards “neural networks”, is coming up against the phenomenon of instability known as “catastrophic forgetting”[11], which appears when trying to learn a new task without replaying the past examples that were used to learn the old tasks. Several strategies have been developed to counter this problem, but to date they do not seem to be fully developed. Meanwhile, Deep Learning involves large amounts of data, which we do not have since the capture focuses on the activity of a single user. Moreover, even using large quantities of data, this approach makes it difficult to reliably measure the uncertainty of predictions. Indeed, unlike some probabilistic models, most neural networks do not directly produce probability distributions, which are a reliable indicator of confidence. In addition, they usually adapt perfectly to training data, which can lead to an overestimation of confidence in the case of new data to be processed. All of the above has led Orange researchers to favour a Bayesian probabilistic approach, as such an approach is better able to quantify and rigorously manage uncertainty, especially in a changing environment.
Ergonomic problems in personalisation
From a UX standpoint, several research studies [13] [14] [15] point out the importance of the benefit/cost ratio (human) of adaptations in the acceptance of these mechanisms, as well as the criteria of stability, reliability (in the sense of accuracy) and predictability. The reliability of predictions combined with the predictability of the interface are a key component of human trust in the machine. In his mixed-initiative approach, Eric Horvitz [14] explains that the system must be able to continuously evaluate the benefit/cost ratio of system-initiated adaptations. The benefit here corresponds to the value perceived by the user (e.g. successful guidance). It takes into account the success rate of the AI, which can be measured using probabilities (or degrees of confidence). It is all the more important given that the system rarely errs (low uncertainty). With respect to the cost, this corresponds to the consequences for the user in the event of an adaptation error (an inappropriate proposal that results in unnecessary additional actions for the user). In this context, the nature of the adaptations (reorganisation, creation of shortcuts, suggestions etc.) is guided by this ratio, which is evaluated over time. Horvitz highlights the fact that the measure of uncertainty (the opposite of the degree of confidence) is central to being able to manage, at any time, the level of automation of the service and the dialogue with the user. In other words, the challenge is to find, at any given moment, the correct level of delegation to the system and the means of controlling that delegation. One of the consequences is that, in the presence of uncertainty, one should prefer to “do less” but correctly. This is the case, for example, with guided navigation, which gives rise to few interface modifications and can therefore be implemented quickly without waiting for a high level of confidence concerning the user’s intentions, with the consequences of any improper adaptations being limited.
This approach is highly topical given the questions around the use/adoption of AI in digital services. Today, the company LangChain is building on this concept with its -based design framework[4]. This empirical formula quantifies the confidence perceived by the user when using an AI-assisted service, by balancing the value for the user (when the AI succeeds) with the psychological barriers related to anxiety about mistakes and the effort required to fix them.
Continuous robust probabilistic modelling of usage habits
As has been stated, because humans are constantly changing beings, continuous and sequential learning is essential. Orange researchers are therefore studying the topic of robust continuous learning (self-supervised and incremental) with the aim of creating and maintaining, over time, an interaction model specific to the current user. Orange’s research has thus led to the design of a robust machine learning approach aimed at designing digital interfaces capable of dynamically adapting to different users and usage strategies. The algorithm, called [5], uses Bayesian statistics to model users’ browsing behaviours, focusing on their habits rather than group preferences. It is distinguished by its online incremental learning, allowing reliable predictions even with little data and in the case of a changing environment. This adaptive inference method therefore aims to model the usage habits of the current user. The algorithm learns new tasks while preserving prior knowledge. A habitual task will then be considered as a sequence of actions that the user routinely performs on the interface in order to achieve a goal (for example, making a bank transfer or starting an episode of their favourite series). However, this technique, centred on usage habits, does not address the other dimensions of the user profile, such as their preferences or physical capabilities [17], which can be addressed by other means, notably through flexible and adaptable interfaces in a universal design logic [18].
With ABIT-H, Orange’s research is implementing an original adaptive inference technique combining the theory of Bayesian networks [19] with that of digital filtering. The non-parametric Bayesian approach, based on Bayes’ theorem, makes it possible to determine the most probable class for a new observation based on the a priori distribution of the classes (the output hypotheses) and the conditional distribution of the data. Filtering theory is also used to construct adaptive estimators of relative frequencies. The latter allow the probabilities involved to be estimated adaptively, with each new observation updating their value. These estimators have an internal memory whose size automatically adjusts to the problem. This makes it possible to maintain the probability estimates over time and to guarantee their coherent combination in the calculation of the Bayesian probability (i.e. the posterior probability). Thanks to the adaptive technique in Orange’s research, probability distributions are accurately estimated over time. The application of the criterion of maximising posterior probability thus provides the solution that minimises the overall classification error. The [6] of the algorithm stems from this optimal mathematical approach, designed to adapt to a changing environment.
This technique has been implemented within the [7] mobile app and has proven effective in real manipulation by a user, with usage habits being created.
Orange’s research focused on the following two personalisation paradigms:
- Guiding the user along their usual paths, using a selection highlight (in the form of an orange rectangle) automatically placed around the most likely action buttons.
- Automatically creating action shortcuts (the “Voice Labels” button) on the home screen related to the user’s most common habits, as shown in Figure 1.
Automatic guidance during an interaction task reduces the user’s mental load, which benefits everyone and also helps compensate for cognitive impairments. The automatic creation of action shortcuts reduces the number of actions needed to perform a task, which also benefits everyone and is extremely useful in mitigating, in particular, motor-based disabilities.
With this prototype, Orange’s research also sought to test the ability of ABIT-H to precisely model users’ interaction activity, using a “task model” that can be generated automatically by the algorithm. This interpretable model provides a graphical representation of the interaction (coded in Dot language) incorporating usage statistics, as illustrated in Figure 1. In this directed graph, each node corresponds to a menu that has been selected by the user. Each branch of the graph corresponds to a navigation task performed by the user, such as the sequence: Menu -> Settings -> Other Audio -> Voice Labels. The model shows the interface’s logical structure of navigation, and the conditional probabilities of transitions between menus. The joint probability for each task is indicated at the end of the path (on the right) on the scale of evidence in decibans (dB). This probability reflects the usage level of each task at the current time. For example, it can be deduced from this model that access to the “Voice Labels” function (evidence of -6 dB) is the task most likely to be performed by the user at the moment in question.
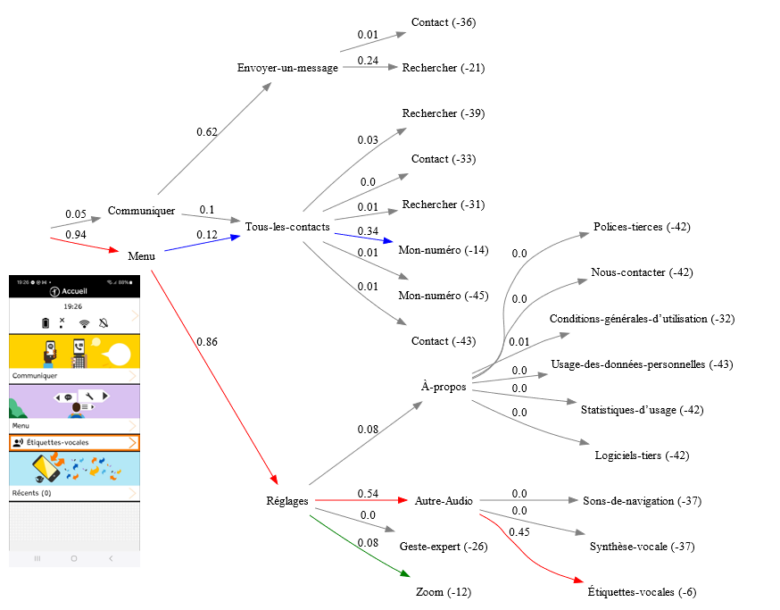
Figure 1: Task model generated in real time by ABIT-H based on a user’s interaction with the Tactile Facile mobile app.
The task model makes it possible to monitor, in real time, the evolution of how the user uses the application, differentiating between occasional and habitual uses and highlighting personal navigation strategies: for example, here, getting to the “My Number” function via the “Menu” category rather than via “Communicate”.
For more comprehensive and quantitative validation, Orange’s researchers carried out numerical simulations [16] demonstrating the algorithm’s sequential learning capacity. It should be noted that this useful characteristic involves both the learning of new habits and the unlearning of old habits that have become obsolete. In this new scenario, the relationship between man and machine is continuously adjusted on both sides, in a form of co-learning.
Conclusion
Our article describes an innovative approach to improving the interaction between a digital interface and its user, using Bayesian statistics to analyse and understand the habits and constraints specific to each user.
Because humans are changing beings, Orange’s research has focused on continuous and sequential learning in a dynamic environment. In this context, Bayesian inference gives the model the ability to rationally revise its beliefs with each new data in the presence of uncertainty. This work has given rise to the development of the ABIT-H algorithm, which enables iterative and incremental implementation and the production of reliable uncertainty measures on predictions. This is crucial in a UX context where the system may make autonomous decisions leading to interface modifications. The technique was tested through the Tactile Facile mobile app and simulations of navigation tasks in a hierarchical menu, thus demonstrating the model’s ability to quickly and robustly learn new tasks while maintaining its past knowledge.
These research outcomes pave the way for adaptive systems that improve users’ experience by helping them to better navigate and act on their interface. Through this approach, the design of the human-machine interaction has been reconsidered to reduce the need for users to adapt to the constraints of the machine, with the machine having to adapt to the human.
[1] Web Content Accessibility Guidelines
[2] UX = User eXperience; refers to user-centric ergonomic design.
[3] The notion of robust inference refers here to the ability of AI to doubt reasonably, which means that it needs to be able to identify uncertainties, whether due to a lack of knowledge, the intrinsic variability of the data or the presence of contradictory examples.
[4] CAIR stands for “Confidence in Artificial Intelligence Results”: https://blog.langchain.com/the-hidden-metric-that-determines-ai-product-success
[5] ABIT-H: “Adaptive Bayesian Inference Technique with Hierarchical structure” is an algorithm for multi-label adaptive classification, used for modelling action sequences [16].
[6] Robustness is understood as the ability of a system to remain stable (short-term) and viable (long-term) despite fluctuations in the environment, according to the definition of biologist Olivier Hamant. Hamant notes that robustness is different to performance, which relates to a stable and controlled environment.
[7] Tactile Facile: Orange research prototype providing basic telephony functions and incorporating the principles of universal design.
Sources :
[1] Simonin & Carbonell, 2007. Interfaces adaptatives Adaptation dynamique à l’utilisateur courant. Interfaces numériques.
[2] Vanderdonckt, Bouzit, Calvary, & Chêne, 2020. Exploring a Design Space of Graphical Adaptive Menus: Normal vs Small Screens. ACM Transactions on Interactive Intelligent Systems.
[3] Oppermann, 1994. Adaptively supported adaptability. International Journal of Human-Computer Studies, Vols. 40-3, pp. 455-472.
[4] McGrenere , Baecker , & Booth, 2002. An evaluation of a multiple interface design solution for bloated software. In CHI ‘02(ACM Press).
[5] Bunt & Conati, 2004. What role can adaptive support play in an adaptable system? In Proceedings of the 9th international conference on Intelligent user interfaces (ACM), pp. 117–124.
[6] Constantinides & Dowell, 2018. A Framework for Interaction-driven User Modeling of Mobile News Reading Behaviour. Proceedings of the 26th Conference on User Modeling, Adaptation and Personalization, pp. 33 – 41.
[7] Wikipedia, Machine Learning, 2025. Supervised machine learning
[8] Shaheen, Hanif, Hasan, & Shafique, 2022. Continual Learning for Real-World Autonomous Systems: Algorithms, Challenges and Frameworks. Journal of Intelligent & Robotic Systems, Volume 105, Issue 1.
[9] IBM, 2025. fine tuning.
https://www.ibm.com/think/topics/fine-tuning
[10] Chen & Liu, 2018. Lifelong machine learning. Synthesis Lectures on Artificial Intelligence and Machine Learning. Morgan & Claypool Publishers.
[11] Luo, Yin, Bai, & Mao, 2020. An Appraisal of Incremental Learning Methods. Entropy – Open Access Journals, 22, 1190. (doi.org/10.3390/e22111190).
[12] Hoi, Sahoo, Lu, & Zhao, 2021. Online learning: A comprehensive survey. Neurocomputing, 459, C, 249–289 (doi.org/10.1016/j.neucom.2021.04.112).
[13] Sears, A., & Shneiderman, B. (1994). Split menus: effectively using selection frequency to organize menus. ACM Transactions on Computer-Human Interaction (TOCHI), Volume 1, Issue 1, pp. 27 – 51.
[14] Horvitz, 1999. Principles of mixed-initiative user interfaces. In Proceedings of the SIGCHI conference on Human Factors in Computing Systems, CHI ‘99, pp. 159-166.
[15] Gajos, K., Everitt, K., Tan, D., Czerwinski, M., & Weld, D. (2008). Predictability and Accuracy in Adaptive User Interfaces. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pp. 1271 – 1274.
[16] Robust and continuous machine learning of usage habits to adapt digital interfaces to user needs, HAL 2025.
https://hal.science/hal-05204331v2/
[17] Martin-Hammond, et al., 2018. Designing an Adaptive Web Navigation Interface for Users with Variable Pointing Performance. Proceedings of the 15th International Web for All Conference W4A ‘18, Vols. 31, 1–10(ACM NY USA).
[18] Stephanidis, 2001. User Interfaces for All: New perspectives into Human-Computer Interaction. Concepts, Methods, and Tools (Mahwah, NJ: Lawrence Erlbaum Associates), pp. 3-17.
[19] Wikipedia: Bayesian network
Read more :
In practice, it is not uncommon to find a function that can be reached via different paths in an application (web, mobile, TV). Thus, several strategies are usually possible when using a rich user interface. Taking a certain path may determine how a function is used or may condition the sequence of actions performed. In this case, the navigation/actions logic graph shows nodes with several inputs and several outputs. A naive Bayesian approach does not work in this case, hence the importance of considering an optimal approach taking into account all the dependency relationships between variables.







