


After a dialogue research overview in the previous article, I propose to discover the difficulties encountered when transferring research results to industry in the dialogue system context: for instance, the french interactive voice response (1013, 3000, 3900, …) or the personal assistants (Siri, Google Now, Cortana, or Echo).
Reinforcement learning issues with industrial dialogue systems
For twenty years or so, reinforcement learning [Sutton1998] has been used in dialogue research [Levin1997, Lemon2007, Young2013] in order to optimise the system’s behaviour. Yet, excepted very rare commercial success stories [Putois2010] (appointment scheduling on the french 1013 service), its adoption by industry remains limited for two main reasons: the definition of system state space representation (set of all states the system might be) requires a high scientific skill ; and the behaviour is optimised in order to maximise an objective function, which is in turn difficult to determine.
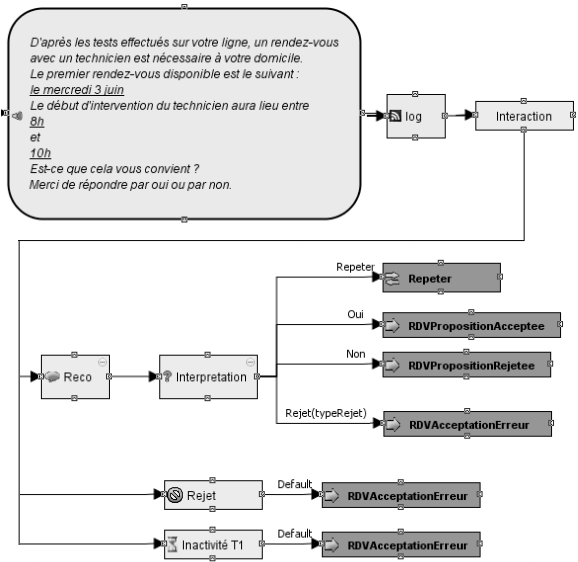
Example of handcrafted dialogue logic
The state space representation raises several issues [Pieraccini2005, Paek2008]. The system state must contain the dialogue context information necessary to a knowledgeable decision making. The decision quality is teherefore directly depending on the state space representation. But there exists a phenomenon called the dimension curse that prevents from including all the system variables in this representation. Indeed, doing so would compromise the convergence speed of the reinforcement learning algorithms. It is therefore advised to represent the relevant information, and only it, and there’s an art to it.
The reward function enables the dialogues evaluation, in such a way that, optimising it implies that future generated dialogues are of the best quality. A bad reward function induces an optimisation according to wrong criteria and consequently bad dialogues. In dialogue systems, it often incurs that evaluating automatically dialogues is problematic [Walker1997, Boularias2010, Sugiyama2012]: did the user end the call because he got what he was looking for, or because he gave up?
A plug-and-play approach
Based on previous works of her team [Laroche2009, Laroche2010], Layla El Asri endeavoured, during her PhD thesis at Orange, to bring answers to both issues. To do so, she designed a methodology according to three courses of action. Firstly, the vocal application designer is not familiar with reinforcement learning, which implies that the state space representation and the reward function must be learnt automatically from data. Secondly, he designer must keep control of his service, meaning that he should have a feedback on what the system learns. In other words, the learning results must be easy to interepret. Thirdly and finally, the system must learn online, i.e. when the service is deployed. This last point is crucial because vocal service deployments are costly and it provides a better agility.
The methodology is summarised in the figure below.

Data preprocessing
The service designer takes care of the system design but lets a certain number of alternatives: in some situations, the system may have several possible actions. For instance, for a restaurant finder service, if the user said “I want a pizza”, the system may propose the search results presented as a list, or may alternatively ask him in which area, or may again ask for the price range. These are three fair answers given the context, and it is difficult to predict a priori which one would be the most efficient.
The second step consists in collecting a dialogue corpus. During this corpus collection, the system follows a random strategy over the specified alternatives. It is crucial that all options are tested: without test, no possible evaluation.

Then, the third and fourth steps consist in annotating the corpus with key performance indicators, which are potentially numerous: dialogue duration, answers provided to the user, number of asr rejects, task completion, … and with dialogue evaluations, either by the users themselves, or buy experts: global evaluation, evaluation of the ability of the system to understand the user, evaluation of the system to be understood by the user, future use, …
Reinforcement learning of the strategy
The annotated corpus enables to learn successively, thanks to the algorithms developed buring Layla’s thesis:
Step 5: compact and interpretable state space representation: sparse distributed memory [Kanerva1988] stores a limited number of state prototypes to which the new encountered states are compared. A genetic algorithm [Rogers1990, Anwar1999] is added in order to keep only the prototypes that are the fittest. This representation is both efficient in terms of performance and memory, and it offers a fair level of interpretability [ElAsri2016a]: the state prototypes are les than 20 and the designer just has to analyse the adopted strategy at each one to earn an overview of the learnt strategy.

Step 6: reward function estimation: it is about predicting the diaogue quality from the key performance indicators. A test bench has been performed over a wide set of supervised algorithms, and according several evaluation metrics (Spearman rank correlation, Euclidean distance, Manhattan error, and Cohen agreement coefficient). The results revealed that support vector machines for ordinal regression [Chu2007] (SVOR) outperforms the bench over all metrics [ElAsri2013a, ElAsri2014c, ElAsri2014d].
Step 7: behavioral strategy reinforcement learning: one could directly use the final rewards computed in the sixth step, but it has been shown [Ng1999] that the most timely the rewards are attributed, the fastest the reinforcement learning algorithm converge, without any bias. In order to take advantage of this, two algorithms have been implemented and compared [ElAsri2012, ElAsri2013b, ElAsri2014e, ElAsri2016b].
In order to validate these works, they have been applied to an appointement scheduling dialogue system, NASTIA [ElAsri2014a, ElAsri2014b], which was used to collect 1734 dialogues, evaluated by the users themselves.
Still some remaining issues
Even if the main sticking points at the designer usability level have been solved, one remains far from reinforcement learning adoption in the dialogue industry. The developed algorithms are computationally heavy. One still needs to define an architecture allowing to run algorithms in background, in order to avoid service breaches. Enven more importantly, vocal application developers look for robustness, readability and code maintainability, before system performance. This means that they continue favouring a non optimal simple system, over a complex one with reinforcement learning, even if they have shown to be able to reduce by two the dialogue failures.
Next effort should therefore relate to an exchange with business units to help them comprehend the machine learning opportunity and to the dialogue technology evolution sothat the multiplying of alternatives does not affect neither the readability nor the maintainability.
More info:
If you do not know, or if you forgot what is reinforcement learning, and/or how it relates to dialogue systems, I strongly recommend that you read my previous article (co-written with Jean-Léon Bouraoui) before starting the reading of this one.
Ecosystem:
Anwar A., Dasgupta D., and Franklin S.(1999). Using genetic algorithms for sparse distributed memory initialization. Evolutionary Computation.
Boularias A., Chinaei H.R., and Chaib-draa B. (2010) Learning the reward model of dialogue pomdps from data. NIPS.
Chu W., and Keerthi S.S. (2007). Support vector ordinal regression. Neural computation.
El Asri L., Laroche R., and Pietquin O.(2012) Reward Function Learning for Dialogue Management. STAIRS.
El Asri L., and Laroche R. (2013a) Will my Spoken Dialogue System be a Slow Learner?. SIGDIAL.
El Asri L., Laroche R., and Pietquin O.(2013b) Reward Shaping for Statistical Optimisation of Dialogue Management. SLSP.
El Asri L., Lemonnier R., Laroche R., Pietquin O., and Khouzaimi H. (2014a) NASTIA: Negotiating Appointment Setting Interface, LREC.
El Asri L., Laroche R., and Pietquin O.(2014b) DINASTI: Dialogues with a Negotiating Appointment Setting Interface. LREC.
El Asri L., Khouzaimi H., Laroche R., and Pietquin O. (2014c) Ordinal regression for interaction quality prediction. IEEE ICASSP.
El Asri L., Laroche R., and Pietquin O.(2014d) Régression Ordinale pour la Prédiction de la Qualité d’Intéraction. JEP.
El Asri L., Laroche R., and Pietquin O.(2014e) Task Completion Transfer Learning for Reward Inference. MLIS (AAAI workshop).
El Asri L., Laroche R., and Pietquin O.(2016a) Compact and interpretable dialogue state representation with Genetic Sparse Distributed Memory, IWSDS.
El Asri L., Piot B., Geist M., Laroche R. and Pietquin O. (2016b) Score-based Inverse Reinforcement Learning, AAMAS (à paraître).
Kanerva P. (1988). Sparse distributed memory. MIT press.
Laroche R., Putois G., Bretier P., and Bouchon-Meunier B. (2009) Hybridisation of expertise and reinforcement learning in dialogue systems. Interspeech.
Laroche R. (2010) Raisonnement sur les incertitudes et apprentissage pour les systèmes de dialogue conventionnels. Thèse.
Lemon O., and Pietquin O. (2007) Machine learning for spoken dialogue systems. Interspeech.
Levin E., and Pieraccini R. (1997) A stochastic model of computer-human interaction for learning dialogue strategies. Eurospeech.
Ng A.Y., Harada D., and Russell S. (1999). Policy invariance under reward transformations: Theory and application to reward shaping. ICML.
Paek T., and Pieraccini R. (2008) Automating spoken dialogue management design using machine learning: An industry perspective. Speech communication.
Pieraccini R., and Huerta J. (2005) Where do we go from here? Research and commercial spoken dialog systems. SIGDIAL.
Putois G., Bretier P., and Laroche R. (2010) Online Learning for Spoken Dialogue Systems: The Story of a Commercial Deployment Success. SIGDIAL.
Rogers D. (1990). Weather prediction using a genetic memory. Report.
Sugiyama H., Meguro T., and Minami Y.(2012) Preference-learning based Inverse Reinforcement Learning for Dialog Control. Interspeech.
Sutton R. S., and Barto A. G. (1998) Reinforcement learning: An introduction. Cambridge: MIT press.
Walker M.A., Litman D.J., Kamm C.A., and Abella A. (1997) PARADISE: a framework for evaluating spoken dialogue agents. EACL.
Young S., Gasic M., Thomson B., and Williams J. D. (2013) POMDP-based statistical spoken dialog systems: A review, Proceedings of the IEEE.







