


To go from voice command to dialogue: that is the challenge of artificial intelligence in producing larger-than-life virtual assistants.
Summary
To overcome the paradigm of the voice command and to include it in a dialogue: that is the current challenge of artificial intelligence in producing larger-than-life virtual assistants. Even though research has been working towards this for nearly two decades, the heart of the difficulty in achieving natural man-machine dialogues is down to the extremely dynamic nature of dialogue’s task-solving. These dynamics involve the definition of exchange management strategies faced with exponential complexity – as each new round of interaction must be processed according to all of the previous rounds –, and for taking into account problematic situations such as misunderstandings or a user’s change of mind.
So, we are still far from the fantasies of science fiction, but machines are already capable of a lot of things and research is currently trending towards promising routes. Among these, the automatic creation of dialogue systems from content, multitask assistants, or the creation of incremental dialogue systems: breaking away from the round-by-round dialogue model, thus giving everyone the possibility to speak up when they wish and point out an error or add a reference.
Full Article
The myth, initiated with science-fiction literature, got incarnated for a general audience through cinema (HAL 9000, R2-D2, Samantha or TARS), and large companies of course did not deprive themselves to keep the dream going in order to promote their personal assistant technologies: Siri, Google Now, Cortana, and Echo. The last advances of academic research and the multiple industrial initiatives allow us to perceive a part of reality in the promise of a natural communication with a machine capable of speech. Still, there remains numerous technical and scientific challenges to rise up to to fully reach the promise.
It is true that audio signal processing with models learnt through Deep Learning (Hinton 2012) has greatly improved the performance of speech recognition technologies. It is also correct that, coupled with information retrieval technologies and natural language processing, one can get a good understanding of a wide range of vocal commands: should I take an umbrella? What time is it? Call Mum.
But, we will remain at the stone age of personal assistant as long as we do not overtake the vocal command paradigm to embed it into a dialogue. Formally, a dialogue is an exchange of information between two (or more) agents. These agents may be human or machine. Most dialogues have for objective to perform a task. In other words, these agents will collaborate to perform a given task, which may in turn be composed of several subtasks. The task and subtasks completion is usually achieved through a semantic representation. The dialogue problem is much more complex than the one of voice decoding. It even has an exponential complexity, since each new dialogue turn must be processed according to all the previous ones.
A market in a strong expansion
The first commercial spoken dialogue systems are 20-years old and used to automatise call centers, under the name of interactive voice response. Users did not like their apparition, since they were provided in replacement of a human service, and were therefore seen as a degradation of service. But since 2011 and Siri release, users started to adopt the dialogue technology when it is offered as functionality addition.
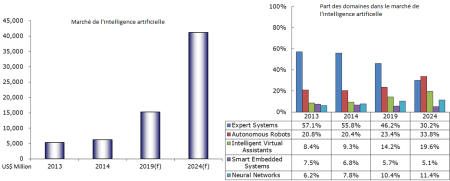
In order to illustrate this growing interest for the dialogue technology and personal assistants in particular, we can quote a study study performed by MIC (Market Intelligence & Consulting Institute), which forecasts that the artificial intelligence market would follow an exponential growth over the 10 next years and that personal assistants (called Virtual Intelligent Assistants in the study) would be its main actor by multiplying by 2.5 its relative artificial intelligence market part. According the same study, between 2014 and 2024, the personal asisstant market should have an average compound annual growth rate of 30%, and see its turnover multiplied by 14.
A modular architecture with signal and language processing, and interaction strategy
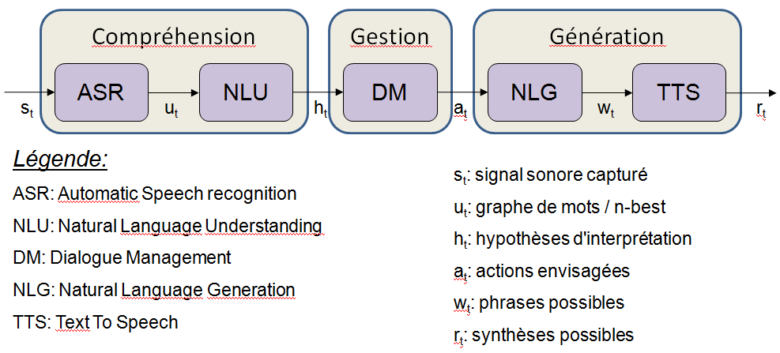
Usually, a human-machine dialogue system is composed of five modules (Jurafsky 2009, Landragin 2013), that we regroup here in three categories:
- Understanding: it is about extracting the mearning of what the user says, with possibly taking into account contextual information. Techniques involve audio signal processing and natural language processing. A semantic representation (language model) is defined by expert, by machine learning, or by both.
- Management: here, the dialogical aspect of dialogue is taken into account. The dialogue is indeed a dynamical sequence of interaction between the user and the system, which implies strategy definition, to perform subtasks and to retrieve from unexpected situations such as misunderstanding of the user.
- Generation: to answer the user, the dialogue system must make an utterance and vocalise it. The utterances are generally processed thanks to template-based sentences. The voice amy be prerecorded and assembled online, or synthesised from a phonem-based model of the language.
Orange Labs has a complete software suite to design and implement a spoken dialogue system: Orange Dialogue Studio (ODS). ODS is an industrial solution, that any developer may use to build a dialogue application, but also a flexible tool for academic research.
A research domain largely relying on reinforcement learning
Reinforcement, issued from behavioural psychology (Skinner 1948), is a processus that builds the animal bahviour in order to repeat the generation of a positive stimulus (reward), and/or to limit the appearance of negative stimulus (penalty). In artificial intelligence, reinforcement learning (Sutton 1998) is about making an agent learn to adopt a behaviour (i.e. an action model given a current state) enabling to engender a maximal sum of future rewards. The dialogue can be modelled as a reinforcement learning problem (Lemon 2007, Young 2013): the current state is determined by the system understanding of the user’s goal ; on the basis of this state, the system decides an action to perform, in order to optimise its reward expected value, reward that it evetually receives when the task is accomplished.
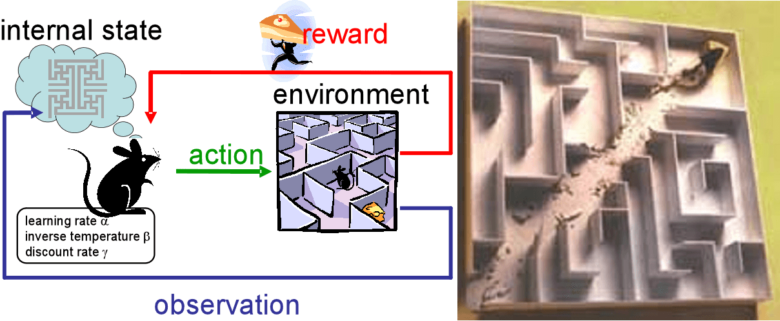
Reinforcement learning in spoken dialogue systems is the main research subject since nearly two decades (Levin 1997, Singh 1999). The dialogue applicative context assumes that reinforcement learning is at the same time sample efficient (Gašić 2010, Pietquin 2011): convergent after several hundreds of dialogues ; and robust to noise (Williams 2007): a good dialogue strategy is not always a winner and inversely, a bad strategy might succeed by chance. But until recently, these statistical methods were not compatible with an industrial process (Pieraccini 2005, Paek 2008).
In order to solve this, several studies on reinforcement learning hybridisation were led in such a way that the reinforcement learning possible actions are constrained to relevant ones (Singh 2002, Williams 2008, Laroche 2009 & 2010a). However, these results remain only usable by reinforcement learning experts. Then, several new studies focused on how to make these techniques accessible to an average developer: reinforcement learning results monitoring (Laroche 2010b), convergence speed prediction (El Asri 2013), or again interaction quality prediction (El Asri 2014).
Apple seems to trust dialogue research, in particular from Cambridge university (Williams 2007, Gašić 2010, Young 2013) since they bought fom more 50M£ the start-up VocalIQ.
Endless source of new research problems
More recently, other research subjects take orthogonally more and more room:
 Spoken dialogue system evaluation: they are made of several modules and the technical individual evaluation of these modules is not sufficient. Indeed, the induced behaviours must be evaluated in terms of system correctness, appropriateness, and adequacy (Dybkjaer 2004). Subjective evaluation might be realised by users after the realisation of a dialogue (Walker 1997), or by expert annotators (Evanini 2008). In order to estimate this evaluation online, several objective key performance indicators are used such as dialogue length, visited states, ASR rejects, etc. This prediction can be made by regression (Walker 2000), classification or ordinal regression (El Asri 2014).
Spoken dialogue system evaluation: they are made of several modules and the technical individual evaluation of these modules is not sufficient. Indeed, the induced behaviours must be evaluated in terms of system correctness, appropriateness, and adequacy (Dybkjaer 2004). Subjective evaluation might be realised by users after the realisation of a dialogue (Walker 1997), or by expert annotators (Evanini 2008). In order to estimate this evaluation online, several objective key performance indicators are used such as dialogue length, visited states, ASR rejects, etc. This prediction can be made by regression (Walker 2000), classification or ordinal regression (El Asri 2014).
![]() Incremental dialogue systems (Skantze 2009, Schlangen 2011, Raux 2012, Khouzaimi 2014 & 2015): the objective is to overtake the turn-by-turn dialogue model, where each speaker can only take the ground when the other speaker explicitly releases it, and to offer to each the possibility to take the ground when needed, for instance to correct a mistake, notify a misundertanding, make reference to a specific concept, etc. It implies an end-to-end incremental processing of the dialogue chain.
Incremental dialogue systems (Skantze 2009, Schlangen 2011, Raux 2012, Khouzaimi 2014 & 2015): the objective is to overtake the turn-by-turn dialogue model, where each speaker can only take the ground when the other speaker explicitly releases it, and to offer to each the possibility to take the ground when needed, for instance to correct a mistake, notify a misundertanding, make reference to a specific concept, etc. It implies an end-to-end incremental processing of the dialogue chain.
 Multi-task dialogue systems: personal assistants are vocal swiss army knives ; they have to be able to answer a wide scope of tasks for a specific user, which implies several news issues: system extension to a new task (Gašić 2013), context exchange between different tasks (Planells 2013), heterogenous dialogue task fusion (Ekeinhor-Komi 2014), dialogue with connected objects, or user adaptation (Casanueva 2015, Genevay 2016).
Multi-task dialogue systems: personal assistants are vocal swiss army knives ; they have to be able to answer a wide scope of tasks for a specific user, which implies several news issues: system extension to a new task (Gašić 2013), context exchange between different tasks (Planells 2013), heterogenous dialogue task fusion (Ekeinhor-Komi 2014), dialogue with connected objects, or user adaptation (Casanueva 2015, Genevay 2016).
 Human-human conversation listening: still a limited research subject in practice, but some theoretical results appear (Barlier 2015). It is a very hard problem, but the applications are real: Expect Labs, whose investments are from Google Ventures, Samsung, Intel, the CIA and others already released a product Mindmeld: an application that listens to your phone calls and proposes related contextual content. At Orange, the expressed need concerns several domains: the smart home, where conversations are numerous, meeting rooms where some laborious tasks might be automated, call centers to let the human operator focus on its interaction with the customer, and not the IT tools, etc. It has to be noticed that these applications are strongly connected to constraints regarding the private life, and Orange takes them very seriously.
Human-human conversation listening: still a limited research subject in practice, but some theoretical results appear (Barlier 2015). It is a very hard problem, but the applications are real: Expect Labs, whose investments are from Google Ventures, Samsung, Intel, the CIA and others already released a product Mindmeld: an application that listens to your phone calls and proposes related contextual content. At Orange, the expressed need concerns several domains: the smart home, where conversations are numerous, meeting rooms where some laborious tasks might be automated, call centers to let the human operator focus on its interaction with the customer, and not the IT tools, etc. It has to be noticed that these applications are strongly connected to constraints regarding the private life, and Orange takes them very seriously.
 The automatic conception of dialogue systems from data: Watson, the IBM software that won Jeopardy against the best human competitors, is now industrially exploited to answer this kind of issues (Ferrucci 2012). A content base is hoovered, analysed, structured and transformed in a dialogue system that can answer a maximum of user’s requests. One of the advantages is a easier and faster conception and deployment of dialogue systems (Laroche 2015). This research area is still quite confidential.
The automatic conception of dialogue systems from data: Watson, the IBM software that won Jeopardy against the best human competitors, is now industrially exploited to answer this kind of issues (Ferrucci 2012). A content base is hoovered, analysed, structured and transformed in a dialogue system that can answer a maximum of user’s requests. One of the advantages is a easier and faster conception and deployment of dialogue systems (Laroche 2015). This research area is still quite confidential.
 Multimodality (Bellik 1995, Oviatt 2002, Bui 2006): the dialogue systems that use more than one mode of communication with the user (for instance the vocal and tactile modes) are called multimodal. Both main issues raised by this kind of dialogue applications concern the coordination between the modalities: the multimodal fusion is the coordination between several inputs from distinct communication modes, and multimodal fission is the coordination of several outputs in direction of distinct communication modes.
Multimodality (Bellik 1995, Oviatt 2002, Bui 2006): the dialogue systems that use more than one mode of communication with the user (for instance the vocal and tactile modes) are called multimodal. Both main issues raised by this kind of dialogue applications concern the coordination between the modalities: the multimodal fusion is the coordination between several inputs from distinct communication modes, and multimodal fission is the coordination of several outputs in direction of distinct communication modes.
As a conclusion, still a lot to do
We are still far from the science-fiction fantasms, but machines are already capable to understand and do a lot of things. Their use will grow fast in the years to come. The first commercial applications and start-ups are multiplying and the market growth perspective are high. Users will learn to use them, a co-adaptation is therefore going to take place in a moving environment: new ecosystems, new technologies, new computing powers, and most important of all new usecases. Orange is already well positioned and this, since more than 20 years, with an industrial solution and a sustained activity in research, but the effort must continue, through good partnerships, like in 2010 during the European project FP7 CLASSiC, including the most influent European laboratories, or like now with the anticipation project FUI VoiceHome, including industries at the state of the art: OnMobile, Technicolor et Delta Dore.
More info:
Currently, Siri, Google Now and Cortana are vocal information retrieval solutions more than dialogue engines: the task is performed in one turn of dialogue, and each new request is processed independently fr omthe previous ones..
A dialogue takes place in a context conditionning and defining most interactions. These context elements may be for instance, depending on the application, the fetch, the daytime, the communication mode (phone or face to face), the location, the interlocutor identity or characteristics, etc.
Orange Dialogue Suite served to develop commercial services gathering more than 200 million calls every year. On the research side, Orange Dialogue Suite was used as a tool for 14 international conference articles published these 2 last years.
The VUI-completeness is a set of constraints that are critical to research application to the industry. It requires a total control of dialogues that may generated with the system, and an interpretability of the policies learnt by the machine learning algorithms.







