


Le développement des usages de la messagerie électronique au travail depuis les années 90 s’est notamment traduit par une augmentation continue des messages échangés. Cette augmentation a fait l’objet de très nombreuses études qui ont mis en évidence des conséquences délétères sur les travailleurs et une dégradation de leur activité (“surcharge cognitive”, interruptions, fragmentation du travail ou stress [1, 2]). Afin de réduire ces conséquences, de nombreuses pistes technologiques et organisationnelles ont été explorées. Concernant les pistes technologiques, différents systèmes ont été proposés : par exemple, des systèmes de classement en différents groupes, de filtrage automatique (les filtres anti spam) ou de hiérarchisation des messages selon le contexte (l’activité de l’utilisateur, l’objet du message, l’émetteur, etc. [3]).
S’inscrivant dans cette perspective, un système a été développé dans le cadre d’un projet de recherche d’Orange au sein du domaine de recherche “Digital Enterprise”. L’objectif principal de ce prototype de recherche est d’assister l’utilisateur dans ses activités de traitement des messages entrants, en tirant partie des progrès réalisés en Intelligence Artificielle, en particulier dans le domaine de l’apprentissage machine (Machine Learning). Ce système a fait l’objet d’une étude d’usage dans le cadre d’une expérimentation en situation de travail réel dans un établissement bancaire, avec pour objectif d’explorer différentes questions : qu’apporte réellement ce système en termes d’aide à l’activité de traitement des messages entrants au travail ? Allège-t-il cette activité ? Réduit-il les interruptions ? Comment les utilisateurs se l’approprient-ils ? Transforme-t-il leurs usages de la messagerie électronique ? Comment réagissent-ils face à un système apprenant, par exemple en termes de confiance ?
Le système de gestion de mails
Le système de gestion de mails développé – et enrichi de plusieurs fonctionnalités – est un “plug-in” du client de messagerie Outlook. Intégré dans la barre d’outils de la messagerie, sa fonction principale est de prioriser les mails reçus en fonction de leur niveau d’importance et d’urgence. Il calcule un score à partir de trois types de données principales : émetteur, objet et corps du mail. Le plug-in catégorise les messages selon quatre catégories avec un codage couleur (figure 1) : important en orange, important et urgent en rouge, urgent en jaune et secondaire en vert. Cette catégorisation s’inspire de la matrice dite d’Einsenhower [4] qui permet de classer les tâches d’une activité.
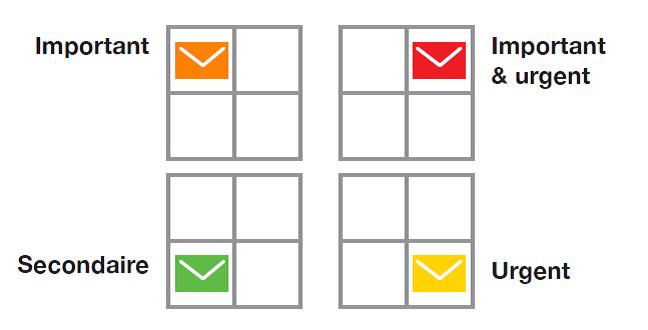
Figure 1. Catégories utilisées par le système de gestion de mails
Pour catégoriser les messages de façon adaptée à l’utilisateur, le système créé un modèle d’apprentissage personnalisé à partir des messages existants et des habitudes d’usage de la messagerie. Une particularité de ce système est que son apprentissage peut être supervisé par l’utilisateur. Ainsi, lorsque le système n’est pas “sûr” de la catégorisation d’un message, il propose à l’utilisateur de la valider. Le système gère également les notifications Outlook de réception de messages. Ainsi, elles sont désactivées pour les messages classés comme secondaires. Un point important est que tous les traitements des messages sont effectués en local, sur le PC de l’utilisateur. Les données restent donc privées. Le système propose également d’autres fonctionnalités, la création d’un référentiel de vocabulaire d’entreprise dont l’objectif est de faciliter l’accès à l’information contenue dans les mails par un enrichissement de ces derniers, le marquage “traité” des messages, l’affichage de l’ensemble des messages non traités sous forme de matrice, la répartition temporelle des mails, et le tri par degré d’urgence et d’importance des mails. La figure 2 présente l’ensemble des fonctionnalités qui apparaissent dans la barre d’Outlook lorsque le plug-in est installé.
Pour analyser les usages de ce système et ses conséquences sur la gestion des messages entrants, une enquête qualitative a été menée, en deux phases, auprès d’un échantillon réduit d’une dizaine d’utilisateurs (tous cadres : directeurs, chefs de projet, experts techniques, consultants internes…) appartenant au service informatique d’une banque française, qui a souhaité tester ce prototype, découvert lors du salon de la recherche d’Orange.
L’objectif de la première phase, réalisée juste après l’installation du plug-in, était de mieux comprendre les usages globaux de la messagerie électronique, en fonction du profil et de l’activité de la personne et de recueillir les premières réactions liées à l’usage du système.
La deuxième phase (deux mois après le démarrage) s’est concentrée sur les usages de celui-ci. Des entretiens approfondis avec les participants ont été réalisés au cours de chacune de ces deux phases.

Figure 2. Ensemble des fonctionnalités affichées sur la barre des tâches d’Outlook
Appropriation de la catégorisation des mails
Un premier constat qui s’est imposé en analysant les usages de ce système a été la difficulté des utilisateurs à s’y retrouver dans les quatre catégories utilisées par le système pour classer les messages.
En effet, il ressort des entretiens que les catégories principalement employées par les utilisateurs pour classer leurs mails sont : “important” et “secondaire”. La catégorie “important” recouvrait tous les mails qui nécessitaient une réponse, alors que la catégorie “secondaire” renvoyait à des mails contenant une information utile, mais qui ne nécessitaient pas de réponse (ex. des mails d’information reçus suite à l’inscription à une liste de diffusion ou des mails où le destinataire n’est qu’en copie).
Les distinctions entre les catégories “urgent”, “important” et “urgent et important” ne semblaient pas faciles à comprendre et à appliquer par les utilisateurs. Elles engendrent un travail cognitif supplémentaire, notamment sur le long terme :
“La difficulté c’est d’avoir un jugement, comment dire… homogène dans le temps. […] L’importance, on voit très vite, mais c’est l’urgence qu’on voit toujours mal. Est-ce que c’est vraiment urgent, est-ce que l’on a envie de traiter pour s’en débarrasser ?… Faut être homogène et carré par rapport à cette règle qu’on se donne. C’est de l’apprentissage, mais faut être cohérent quand même. Si on change d’avis tous les trois jours, ça va perturber l’apprentissage de la machine… ” (Directeur 1, entretien 1).
Le coût cognitif se caractérise ici par la nécessité pour l’utilisateur de garder une cohérence dans ses appréciations pour ne pas perturber l’apprentissage de la machine (avoir la même “règle” pour le traitement de l’urgence et “ne pas traiter vite un mail pour s’en débarrasser”).
Deux profils d’utilisateurs selon le volume de mails reçus
L’analyse des usages a mis en évidence deux catégories d’utilisateurs, notamment en fonction du nombre de mails reçus. Une première catégorie est celle des cadres dirigeants présents dans notre échantillon, qui recevaient un nombre de mails importants (entre 50 et 200 mails par jour). Pour ces utilisateurs, le système arrive relativement vite à apprendre, en classant en “secondaire” un bon nombre de mails issus des listes de diffusion, contenant souvent de la publicité ou des informations sur des évènements. Ces cadres ont progressivement développé une confiance dans les catégorisations du plug-in :
“Bon, je jette encore un œil pour tout vous dire, mais globalement le système a bien repéré ce qui était secondaire pour moi… globalement, c’est bien catégorisé” (Directeur, entretiens 1 et 2).
“Plus on avance, plus j’ai confiance, on voit qu’il ajuste le tir. Je ne lui fais pas une confiance aveugle, mais il est pertinent” (Membre du comité de direction, entretien 1).
Pour les autres cadres, qui recevaient beaucoup moins de mails (moins de 50 par jour) et qui étaient concernés plus directement par les mails reçus, la gestion de ceux-ci se faisait principalement au fil de l’eau. Contrairement aux autres, ces cadres se sont montrés plus méfiants vis-à-vis des catégorisations du système :
“Ben, à la fin je ne faisais plus trop confiance à l’outil […] je perdais plus de temps, vu que je devais toujours re-catégoriser, comme il me mettait tout le temps les mails que moi je jugeais importants en vert […] c’était un peu l’effet inverse, au lieu de me faire gagner du temps, j’en perdais” (Chargé de projet, entretien 2).
Cette méfiance était entretenue par l’opacité des règles de catégorisation de l’algorithme :
“Je pense que l’essentiel c’est la compréhension de la manière de classer, parce que si on ne comprend pas ça, il n’y a aucun intérêt à ce qu’il le fasse” (Consultant 1, entretien 1).
Certains utilisateurs ont ainsi souhaité pouvoir personnaliser le dispositif, en ayant la possibilité d’ajouter quelques règles et de choisir éventuellement une catégorisation spécifique.
Des incidences variées sur l’activité
L’analyse des usages révèle aussi différents types d’incidences qui montrent à la fois l’intérêt et les inconvénients potentiels du système, en fonction de la manière dont il est utilisé.
- Réduction des interruptions dans certains cas, mais sentiment de perte de contrôle dans d’autres
L’un des avantages de l’utilisation de ce plug-in est la désactivation des notifications de réception pour les mails jugés secondaires. Cette fonction visait notamment à réduire les micro-interruptions qui pouvaient être générées par les messages secondaires.
Sur ce point, directement relié aux deux profils d’utilisateurs identifiés, les incidences de l’utilisation de ce plug-in sur l’activité renvoient :
- pour les cadres dirigeants, à un sentiment de limitation des interruptions, de gain de temps et de découverte de nouvelles manières plus performantes de traiter ses mails et de gérer son temps (ex. traitement des mails secondaires selon créneau horaire) ;
“Ben là, j’optimise mieux mon temps, je suis plus efficace, je traite ce qui est important […] je travaille depuis quelques semaines en différé” (Directeur, entretien 1).
- pour les autres cadres, à un sentiment de perte de contrôle sur les messages reçus du fait même de la désactivation des notifications, perte jugée délétère pour l’activité. Dans l’extrait d’entretien ci-dessous, un cadre indique ainsi les conséquences du fait d’avoir raté un message qui avait été classé comme secondaire :
“Il m’a appelé en me disant : tu ne m’as pas répondu, ben trop tard, maintenant” (Consultant 2, entretien 1).
Par conséquent, ces derniers continuent à traiter au fil de l’eau tous les messages et arrêtent progressivement d’utiliser le plug-in.
- Un travail supplémentaire pour l’utilisateur
Un autre type d’incidence sur l’activité est le travail supplémentaire de l’utilisateur généré par la nécessité de valider les catégories sur des périodes de temps plus ou moins longues en fonction de la diversité des mails reçus :
“Là, j’ai bien senti le gain de ne plus avoir ces popups… ça c’est clair, mais du coup j’ai l’impression de perdre au moins une partie de ce gain en passant mon temps à retaguer, des choses où il est pertinent” (Membre du comité de direction, entretien 2).
“J’ai l’impression que lorsqu’on recommence un nouveau fil de discussion, il faudra toujours interagir pour lui dire non, non ça c’est important ou ça c’est secondaire, mais j’ai tendance à ne pratiquement plus le faire…” (Directeur, entretien 1).
Cette incidence pose la question de l’efficacité de l’apprentissage du système, de sa durée et du rôle de l’utilisateur. En effet, s’il est tout à fait pertinent de l’impliquer dans cet apprentissage, cette implication peut vite devenir contre-productive lorsqu’il doit valider en permanence les catégorisations du système.
En conclusion
Ces retours d’usage apportent d’intéressants éclairages sur l’apport potentiel d’une IA apprenante dans la gestion des mails.
Tout d’abord, les bénéfices et l’usage varient en fonction de différents facteurs comme le nombre de mails reçus (lié au type d’activité de l’utilisateur) ou la confiance dans le système. Ensuite, les difficultés dans la compréhension des règles utilisées dans la catégorisation est un obstacle à l’appropriation pour certains participants. Un dernier constat porte sur l’apparition d’une tension entre la possibilité offerte à l’utilisateur de superviser l’apprentissage du système (en validant les catégories) et l’effort que nécessite cette supervision. Enfin, parmi les catégories utilisées par le système, deux se sont avérées réellement pertinentes pour les utilisateurs : les mails nécessitant une réponse et ceux qui n’en requièrent pas.
Si ces éclairages demandent à être confirmés dans une nouvelle phase de l’étude construite sur un échantillon plus large, un axe d’amélioration immédiat consiste à faciliter l’appropriation du système en proposant dès à présent aux utilisateurs une personnalisation “à la carte” de catégories adaptées à leurs propres besoins et pratiques de traitement.
Mais au-delà de telles adaptations immédiates, si l’IA apprenante semble aujourd’hui prometteuse pour aider les utilisateurs à faire face à la “surcharge” de mails, son adoption à plus long terme par une plus grande variété d’utilisateurs passera nécessairement par la prise en compte, dès les premières phases de la conception, des incidences de son usage sur leurs activités.
[1] Whittaker S., Sidner C. (1996). E-mail overload: exploring personal information management of e-mail. Proceedings of the SIGCHI conference on Human factors in computing systems: common ground, pp. 276–283.
[2] Assadi, H. et Denis, J. (2005). Les usages de l’e-mail en entreprise : efficacité dans le travail ou surcharge informationnelle ? In E. Kessous, Le travail avec les technologies de l’information (p. 135-155). Paris: Hermes.
[3] Salembier, P. et Zouinar, M. (2017) Interruptions et TIC. De l’analyse des usages à la conception. In Alexandra Bidet, Caroline Datchary et Gérald Gaglio (Eds) : Quand travailler c’est s’organiser. La multi-activité à l’ère numérique. Presses des Mines
[4] Matrice Eisenhower : https://everlaab.com/matrice-eisenhower/
 Anca Boboc
Anca Boboc
 Moustafa Zouinar
Moustafa Zouinar







