Les données non structurées comme les textes sont naturellement explicites (les informations nécessaires à la compréhension du contenu sont dans les phrases ou leur voisinage, agencées selon des règles de construction connues), la difficulté résidant alors dans l’extraction des éléments pertinents et du sens correct en fonction du contexte. A contrario, la sémantique des données structurées ou semi-structurées comme les tableaux est exclusivement latente : un mécanisme implicite (inférence) basé sur les connaissances propres du lecteur est requis pour qu’ils soient compréhensibles, dans la mesure où il n’y a pas de contexte explicite.
Associer des annotations sémantiques aux données tabulaires afin d’en augmenter la valeur ajoutée pour des applications d’Intelligence Artificielle est un enjeu majeur, en particulier dans les entreprises où la majorité des données se présente sous cette forme.
Plateforme de recherche issue de projets IA, DAGOBAH est un système d’annotation sémantique de données tabulaires indépendant du contexte, permettant la génération de graphes de connaissances enrichis sur lesquels les utilisateurs peuvent s’appuyer pour répondre à leurs besoins. DAGOBAH est un projet de recherche collaboratif développé par des équipes d’Orange Labs de Belfort et Rennes, en partenariat avec le département Data Science d’EURECOM à Sophia Antipolis.
Des données tabulaires à la connaissance
“L’information n’est pas la connaissance”[1]. Avec ces mots, Albert Einstein sous-entendait que la connaissance ne pouvait qu’être dérivée de l’expérience. Si on applique cette idée aux données tabulaires –qui peuvent être assimilées à de l’information brute-, cela signifie que tout tableau est dénué de sens sans le regard d’experts (des personnes ayant de l’expérience) du domaine concerné. Cette affirmation est vraie, en effet. Mais si on considère l’expertise comme un ensemble de connaissances de base qui peuvent être représentées et encodées au sein d’un référentiel, n’existerait-t-il pas une manière de transformer ces données brutes en nouvelles connaissances explicites à la lumière de ce référentiel ? Nous pensons que l’information peut devenir de la connaissance. Pour savoir comment, embarquez pour un voyage à destination de DAGOBAH. [2]
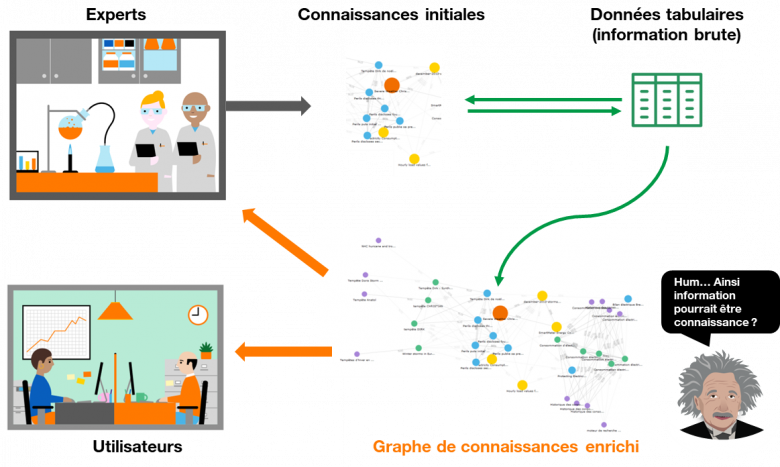
Figure 1 : Des données tabulaires aux connaissances
Pour rendre les données tabulaires compréhensibles, il faut tout d’abord comprendre la nature des informations présentes dans chaque colonne et chaque ligne, ainsi que les relations existantes entre elles. Autrement dit, il faut ajouter des étiquettes sémantiques à chaque élément du tableau, c’est-à-dire réaliser des « annotations sémantiques », dont le processus peut être divisé en trois tâches principales :
- Column-Type Annotation (CTA): trouver le type (ou la classe) d’une colonne donnée (ex : type film);
- Cell-Entity Annotation (CEA): désambigüiser la valeur de chaque cellule du tableau (ex : la ville de Rennes, l’année 1990, le titre de film « Les Beaux Gosses »);
- Column-Property Annotation (CPA): déterminer la relation sémantique entre les colonnes (ex : <film> est sorti en <année> >, <film> a été tourné à <lieu>).
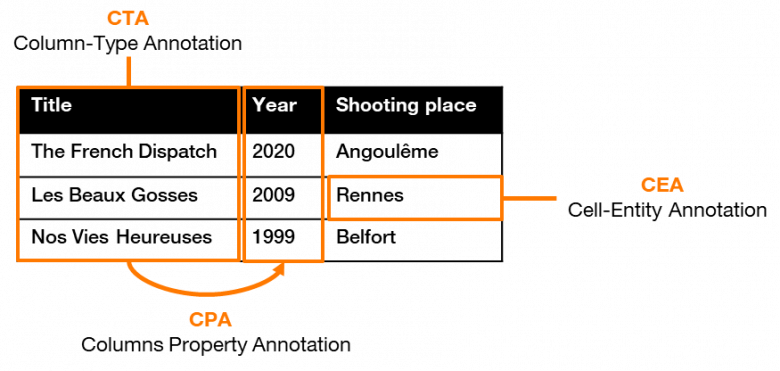
Figure 2 : Les tâches d’annotations sémantiques
Si une analyse simple du tableau permet d’extraire certaines caractéristiques haut-niveau (nombre de 4 chiffres, chaîne de caractères…), l’annotation ne peut être sémantiquement explicite sans l’utilisation d’une base de connaissances existante permettant de préciser le typage (personne, pays, film…). Ces connaissances répertoriées sont de plus en plus souvent formalisées sous forme de graphes, au sein desquels sont associés à chaque entité des attributs explicites (ex : “Angoulême” est une instance de « commune de France »), les relations sémantiques étant quant à elles exprimées sous forme de triplets <sujet, prédicat, objet> (ex : “The French Dispatch” est le sujet, “filming location” est le prédicat, et “Angoulême” est l’objet).
Le graphe de connaissances Wikidata fait office de stockage central des données structurées provenant de divers projets Wikimedia comme Wikipedia, Wikivoyage, Wiktionary, Wikisource, et d’autres. Il rassemble plus de 80,000,000 entités dont le nombre augmente chaque jour. Le Linked Open Data Cloud donne un aperçu de l’omniprésence des graphes de connaissances dans une multitude de domaines.
L’annotation de tableau exploitant les graphes de connaissances est un sujet important car une part conséquente des données du Web comme des entreprises sont représentées sous cette forme. Ce type de données est difficile à interpréter dans la mesure où il n’y a pas ou peu de contexte associé, ce qui ne permet pas de résoudre les ambigüités sémantiques, et où la mise en forme même peut être source de problème. La possibilité d’annoter automatiquement les tableaux à l’aide de graphes de connaissances (que ce soit des graphes de connaissances encyclopédiques comme DBpedia et Wikidata, ou des graphes orientés métier) permet d’envisager de nouveaux services basés sur la sémantique à destination d’utilisateurs, experts ou non.
Cela ouvre par exemple la voie à des solutions de recherche plus efficaces (ex : “aller au-delà des mots-clés” pour la recherche de jeux de données), mais aussi de manipulation et de traitement de corpus de tableaux hétérogènes, permettant à des plateformes de partage de jeux de données comme Dataforum d’avoir une plus forte valeur ajoutée. DAGOBAH est une solution logicielle qui adresse cet enjeu d’annotation via un traitement de données tabulaires de bout en bout.
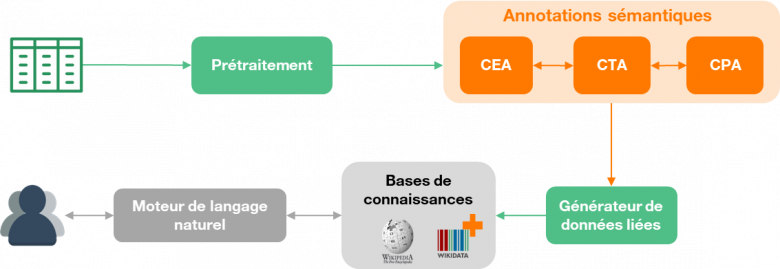
Figure 3 : Chaîne technique DAGOBAH
Prétraitement pour la caractérisation des tableaux
Afin de réaliser des annotations pertinentes, il est tout d’abord indispensable de réaliser un nettoyage simple des données et de convertir les tableaux dans des formats manipulables. Dès lors, la première étape spécifique du processus consiste à comprendre la structure des tableaux, ce qui n’est en général pas trivial compte-tenu de la nature même des corpus. En effet, les tableaux peuvent présenter une hétérogénéité à la fois structurelle (orientation horizontale ou verticale, fusion de lignes ou de colonnes, absence d’en-tête,…) et sémantique (acronymes ou abréviations, phrases longues ou mots isolés, numériques, multilingues,…), mais aussi des données incomplètes voire dynamiques [Figure 4].
Figure 4 : Le Cri des données tabulaires (ou le Cauchemar des formats)
Dans le cadre de données issues de gisements métier où il existe parfois peu ou pas de connaissances a priori des tableaux considérés, l’information produite par le prétraitement s’avère décisive pour la qualité des annotations. La chaîne de prétraitement mise en œuvre dans DAGOBAH, partiellement basée sur l’extracteur du DWTC, génère quatre types d’information:
- Typage primitif des cellules (basé sur onze types prédéfinis, ex : chaîne de caractères, nombre flottant, date…)
- Détection de l’orientation du tableau (horizontal si les attributs sont en colonnes, vertical sinon)
- Extraction d’en-tête
- Détection de la colonne-clé (algorithme DWTC), qui identifie le sujet des triplets qui seront générés à partir du tableau
Après évaluation des algorithmes de DAGOBAH, basés sur un nouveau facteur d’homogénéité, une amélioration significative des performances de l’état de l’art a été constatée sur l’orientation des tableaux et l’extraction d’en-tête (faisant passer la précision moyenne de 62% à 85%). La sortie de ce prétraitement peut ensuite être utilisée par la phase d’annotation à proprement parlé.
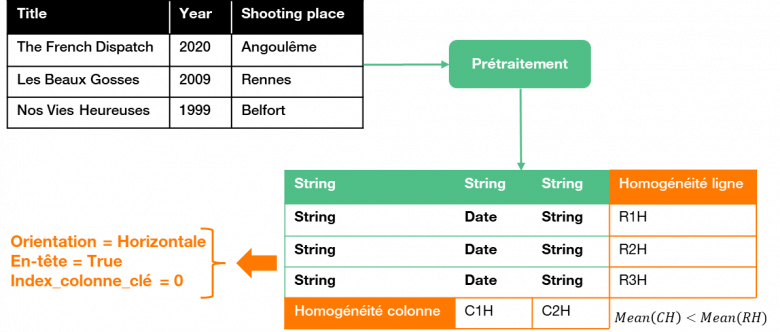
Figure 5 : Prétraitement des tableaux
Annotation par recherche syntaxique et exploitation des techniques de plongement lexical
Dans le but d’ajouter des étiquettes sémantiques aux éléments des tableaux, une approche naturelle consiste à utiliser les interfaces de recherche des bases de connaissances existantes (API Wikidata, API DBpedia…) afin de récupérer une liste de candidats pour une cellule donnée. Il est possible d’interroger simultanément plusieurs services de recherche de ce type, puis de compter le nombre d’occurrences de résultats communs pour en déduire les candidats les plus populaires (fréquents) et les types (classes) correspondants. Néanmoins, un critère de couverture basique (c’est-à-dire choisir le type le plus fréquent via un mécanisme de jugement majoritaire) n’est pas pertinent dans la mesure où le type exact peut être plus spécifique mais pas assez fréquent pour être considéré comme le type cible (seuls des types trop génériques –être humain, lieu géographique…- et portant peu d’informations risquent ainsi d’être extraits). Pour résoudre ce problème, nous avons introduit des heuristiques combinées à des méthodes comme le TF-IDF (Term Frequency – Inverse Document Frequency, souvent utilisé dans le traitement du langage naturel pour combiner des caractéristiques quantitative et qualitative d’un terme donné). Le type présentant le meilleur équilibre entre la spécificité et la fréquence est ainsi sélectionné (ce qui correspond à la sortie de la tâche de CTA), puis est ensuite utilisé pour désambiguïser les entités candidates (tâche CEA).
Cette solution naïve est relativement simple à implémenter et permet d’avoir une large couverture des entités de par la possibilité d’interroger de multiples sources pertinentes sur le domaine considéré, mais elle présente également de nombreux désavantages :
- Dépendance vis-à-vis des services d’interrogation (fiabilité non maîtrisée)
- « Boîte noire » concernant la génération des résultats (quelle stratégie d’indexation ? de scoring ? …)
- Volume des requêtes important
En conséquence, la phase de nettoyage des données devient d’autant plus critique pour accroître la probabilité de correspondances avec les entités des bases de connaissances.
Dans le but d’éviter ces inconvénients, DAGOBAH se base sur des techniques de plongement lexical (ou embeddings). Appliqué initialement aux textes non structurés, le principe consiste à encoder chaque mot en prenant en compte son contexte (qui peut être ici résumé comme l’ensemble des mots voisins) via un réseau de neurones dont la tâche est d’apprendre la distribution des paires de mots. Une fois les poids de la couche cachée optimisés lors de l’entraînement, la représentation cachée de chaque mot en est extraite. Cette représentation correspond à un vecteur dense dans un espace vectoriel de dimension réduite (égale au nombre de neurones choisi). Les propriétés de cette représentation vectorielle (ou « plongement ») sont particulièrement intéressantes, les vecteurs générés capturant les relations sémantiques latentes entre les mots du texte considéré : les mots similaires seront proches les uns des autres dans l’espace de plongement, les opérations entre vecteurs conservant une cohérence sémantique (ex : Oscars Awards – USA + France = César Awards) autorisant les analogies (ex : Wes Anderson est à “The French Dispatch” ce que Riad Sattouf est à “Les Beaux Gosses”) [Figure 6].
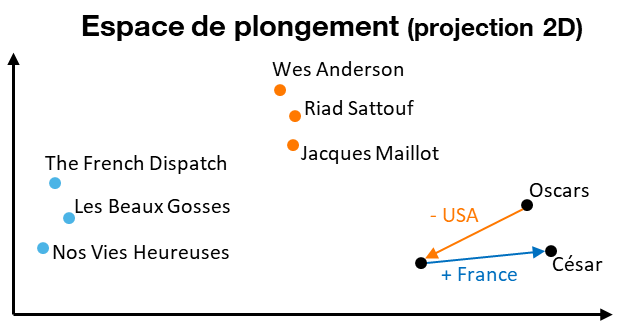
Figure 6 : Propriétés des plongements de mots
Ces plongements sont largement employés dans le traitement du langage naturel, et ont donné lieu ces dernières années à de nombreuses implémentations qui ne sont pas restreintes au texte. Il est en particulier possible de réaliser des plongements de graphes de connaissances comme Wikidata par exemple, ce qui a précisément été utilisé dans le cadre de DAGOBAH (via l’exploitation d’un modèle pré-entraîné issu d’Open KE). Dans cette approche, l’hypothèse très structurante est que les entités d’une même colonne d’un tableau doivent être proches dans l’espace de plongement puisqu’elles partagent des caractéristiques sémantiques (ex : titres de films), et peuvent ainsi former des groupes spatialement cohérents.
Le plongement brut une fois enrichi (avec les différentes valeurs d’alias associées à chaque entité) est interrogé afin de sélectionner les candidats du graphe de connaissances qui peuvent correspondre à une entité donnée du tableau. Ces candidats sont ensuite regroupés (clustering) dans l’espace vectoriel, ce qui réduit le problème d’annotation à un problème de classement et d’ordonnancement (ranking) de clusters dans le but de trouver le plus pertinent pour une colonne donnée, et ainsi en déduire le type cible et les bonnes entités [Figure 7]. Un score de confiance associé à chaque candidat est également calculé pour résoudre les éventuelles ambiguïtés restantes.
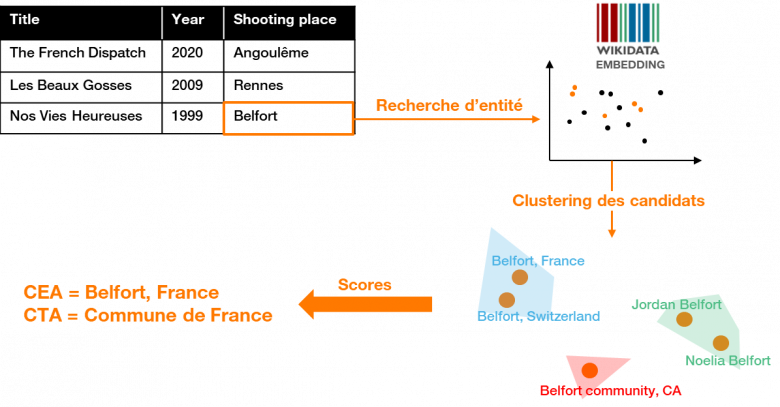
Figure 7 : Annotation sémantique par plongement
L’approche par plongement s’est révélée plus performante que l’approche basique, et s’avère très efficace pour déterminer le type d’une colonne, élément indispensable à de meilleures annotations. Par ailleurs, les résultats sont particulièrement intéressants dans le cas où les valeurs des cellules du tableau sont incomplètes ou très ambigües (ex : homonymes).
L’annotation sémantique, un atout-clé pour de nouveaux services
Maintenant que vous avez découvert les dessous de DAGOBAH, vous vous demandez peut-être : “belle mécanique… mais jusqu’où peut-elle me mener dans l’amélioration de mes services ?” Prenons un cas concret : le dernier film de Wes Anderson (The French Dispatch) existe dans le graphe de connaissance publique que vous avez l’habitude d’interroger. Malheureusement, ce graphe n’est pas à jour, et des informations manquent, comme par exemple les lieux de tournage (ce qui est précisément le cas de Wikidata à l’heure où nous écrivons ces lignes). D’un autre côté, vous avez accès à une autre source qui fournit des données brutes sur les films sous forme de tableaux dont vous n’avez jamais pris le temps de creuser le modèle. Si vous voulez enrichir le graphe de connaissances de départ, vous pouvez réaliser des jointures (si tant est qu’il existe au moins un attribut commun pouvant faire office de clé de réconciliation), mais pour ce faire, vous devez connaître le modèle de données. De plus, des ambiguïtés complexes peuvent rendre cette réconciliation difficile et chronophage, impliquant un développement sur-mesure lié à cette source de données (et donc non mutualisable). Enfin, il ne sera pas possible d’exploiter toute la puissance des relations sémantiques déjà disponibles dans le graphe de connaissances d’origine.
C’est dans ce type de situation que DAGOBAH vous sera très utile, en transformant les données tabulaires complémentaires en connaissances sémantiques à la lumière du graphe de connaissances existant, qui sera enrichi sans effort de manière cohérente. Ce faisant, les utilisateurs pourront alors interroger en langage naturel votre service amélioré sans qu’une réponse vide ne vienne gâcher leur expérience [Figure 8].
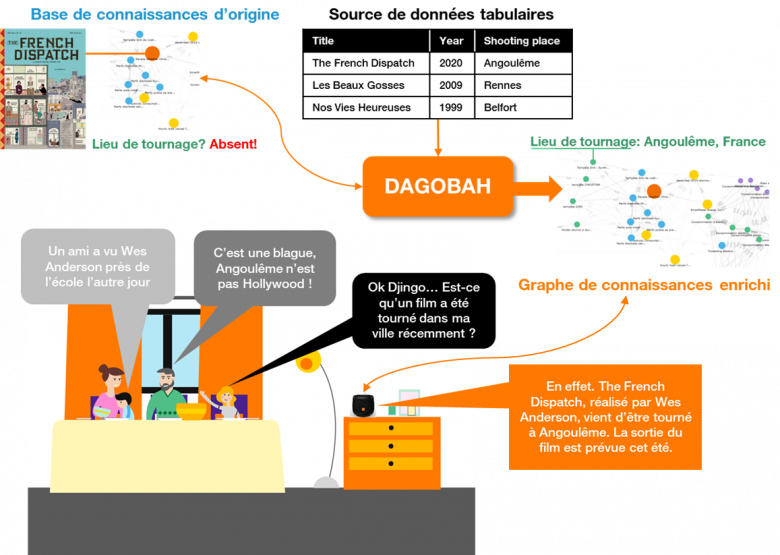
Figure 8 : Service amélioré via l’enrichissement d’un graphe de connaissances
Conclusion
Comme précisé tout au long de cet article, le traitement aboutissant à l’annotation sémantique des tableaux permet de générer desconnaissances dès lors que de nouvelles entités provenant des tableaux peuvent être ajoutées de manière fiable à un graphe, associées à des types et des relations connus : la connaissance latente est ainsi transformée en triplets porteurs de sens. Le graphe de connaissances résultant est directement exploitable par les utilisateurs sans expertise particulière. Les métadonnées générées peuvent de plus être utilisées à des fins de référencement, de recherche et de recommandation de jeux de données comme dans Dataforum.
Pour autant, des défis restent encore à relever : les données tabulaires présentes dans les « data lakes » des entreprises font souvent référence à des connaissances métier difficilement intelligibles pour le néophyte, et en général non décrites dans des bases de connaissances généralistes. Des liens entre des données métier et des connaissances encyclopédiques peuvent être trouvés dans le meilleur des cas (ex : un service VOD pour la TV). A défaut, un embryon de connaissances doit être construit avec les experts du domaine pour démarrer le processus d’annotation. Dans tous les cas, extraire de la connaissance des tableaux est un atout majeur pour améliorer l’accès aux connaissances et imaginer de nouveaux services à valeur ajoutée !
DAGOBAH est un projet de recherche collaboratif développé par les équipes d’Orange Labs de Belfort (Yoan Chabot, Jixiong Liu) et Rennes (Thomas Labbé), en collaboration avec le département Data Science d’EURECOM à Sophia Antipolis (Prof. Raphaël Troncy). Ces activités sont intégrées à deux programmes de recherche hébergés dans le domaine « Decision and Knowledge » piloté par Henri Sanson : « Distributed Intelligence Platform » (Thierry Nagellen) dont l’objectif est d’analyser et décrire les données massives structurées et non structurées, et «Natural Language Processing and Application» (Frédéric Herlédan) qui se concentre sur l’extraction de connaissances ontologiques des données.
[1] Einstein, Albert. Ideas And Opinions (p. 271). Crown Publishing Group.
[2] Yoan Chabot, Thomas Labbe, Jixiong Liu, Raphaël Troncy: DAGOBAH: An End-to-End Context-Free Tabular Data Semantic Annotation System. ISWC 2019 Semantic Web Challenge, Auckland, New Zealand (ISWC is the premier international forum, for the Semantic Web, Linked Data and Knowledge Graph Community)
 Yoan Chabot
Yoan Chabot