


Les techniques d’apprentissage automatique font partie de l’univers de l’intelligence artificielle. Mais comment mettre un nom sur chacune d’entre elles : entre active, supervisée, par renforcement, …, ? Et savoir laquelle sera appropriée à une tache prédéfinie ? C’est le but de ce petit bestiaire.
Introduction
De nos jours, les données sont devenues l’un des atouts majeurs qui constituent la richesse des entreprises. Les informations présentes, mais noyées dans la grande masse de données, sont devenues pour ces entreprises un facteur de compétitivité et d’innovation. Les GAFA (Google, Apple, Facebook, Amazon…) ainsi que les acteurs des télécoms comme Orange sont des exemples d’entreprise ayant exploité les données de leurs utilisateurs/clients afin d’avoir un aperçu sur leurs préférences à partir de leurs données de comportement. En général, ces données permettent aux analystes de découvrir et d’expliquer certains phénomènes existants ou bien d’extrapoler des nouvelles connaissances à partir des informations présentes. Pour exploiter ces grandes masses de données, de nombreuses techniques d’apprentissage automatique ont été développées. Dans ce document, nous nous intéressons particulièrement aux techniques d’apprentissage supervisé et non supervisé qui ont historiquement permis d’organiser efficacement des ensembles de données de taille importante.
Les techniques d’apprentissage peuvent se découper en deux grandes familles selon leur vocation principale : celles servant à décrire les données (méthodes descriptives) et celles permettant de prédire un phénomène (plus ou moins) observable (méthodes prédictives).
Les méthodes descriptives ont pour objectif d’organiser, de simplifier et d’aider à comprendre les phénomènes existant dans un ensemble important de données. Cet ensemble est organisé en instances constituées de plusieurs variables descriptives, où aucune des variables n’a d’importance particulière par rapport aux autres. Toutes les variables sont donc prises en compte au même niveau. Les trois grandes catégories de méthodes descriptives sont : la description, la segmentation et l’association.
Les méthodes prédictives permettent de prévoir et d’expliquer à partir d’un ensemble de données étiquetées un ou plusieurs phénomènes (plus ou moins) observables. Dans ce cadre, plusieurs types de techniques se distinguent : la régression (prévision d’une variable numérique – par exemple le montant de la facture), la classification supervisée (prévision d’une variable catégorielle – par exemple l’appétence à une offre commerciale), …
Le but de ce document n’est pas d’être exhaustif mais de donner au lecteur quelques éléments de vocabulaire et de compréhension. Pour chaque forme d’apprentissage mentionné ci-dessous, on donne une ou deux références bibliographiques (en général un survey, un livre de référence sur le sujet).
Les différentes formes d’apprentissage automatique
On débute les définitions par la présence ou l’absence d’information d’étiquetage. On se réfère après à la figure ci-dessous.
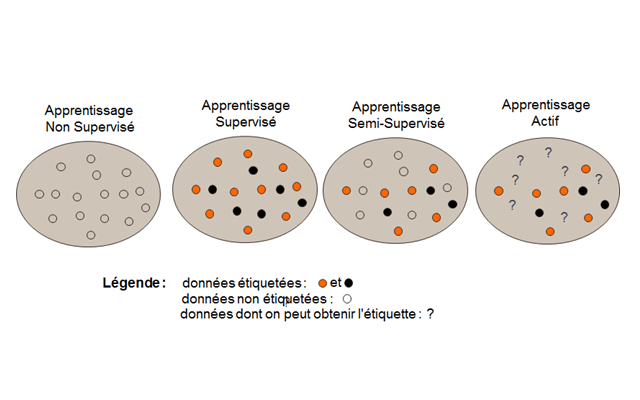
L’apprentissage non supervisé [1] les données ne possèdent pas d’étiquettes, plus exactement l’algorithme d’apprentissage ne reçoit aucune information de l’environnement lui indiquant quelles devraient être ses sorties ou même si celles-ci sont correctes. L’algorithme doit donc découvrir par lui-même les corrélations existant entre les données. On cherche à dégager un certain degré d’organisation. L’objectif est de décrire les données, par exemple, de générer une taxonomie des données sans connaissances préalables (groupage, clustering…).
L’apprentissage supervisé [2] est une technique d’apprentissage automatique où l’on cherche à produire automatiquement des règles à partir d’une base de données d’apprentissage contenant des exemples de cas déjà étiquetés. Plus précisément, la base de données d’apprentissage est un ensemble de couples entrée-sortie, que l’on considère être tiré selon une loi inconnue. Le but de la méthode d’apprentissage supervisé est alors d’utiliser cette base d’apprentissage afin de déterminer une représentation compacte et donc de généraliser pour des entrées inconnues ce qu’elle a pu « apprendre » grâce aux données déjà étiquetées. Les étiquettes peuvent provenir de données du passé (les clients partis à la concurrence le mois dernier) ou par des experts (est-ce qu’un client est solvable ?). On distingue généralement deux types de problèmes que l’on cherche à résoudre avec une méthode d’apprentissage automatique supervisée : (1) lorsque la sortie que l’on cherche à associer à une entrée est une valeur dans un ensemble continu de réels, on parle d’un problème de régression; (2) lorsque l’ensemble des valeurs de sortie est de cardinal fini, on parle d’un problème de classification car le but est en fait d’attribuer une étiquette à une entrée. Il existe aussi le cas de vecteurs à prédire de type « multi classes », « multi labels », ou « structurés » etc… dont on ne parlera pas ici.
Il faut aussi dans le cas supervisé, distinguer la « prédiction » (qui est le cadre général) de la « prévision » (qui est un cas particulier où les données ont une caractéristique temporelle et où l’objectif est dans le futur).
Dans le cas de l’apprentissage semi-supervisé [3], il s’agit d’utiliser une petite quantité de données étiquetées conjointement à une masse importante de données non-étiquetées. Cela correspond à une situation de plus de plus fréquente en recherche d’information.
Il arrive aussi que l’on utilise des techniques d’apprentissage partiellement supervisé. C’est le cas quand on énonce qu’une donnée n’appartient pas à une classe A, mais peut-être à une classe B ou C.
On peut aussi poser des contraintes du type : ces deux données sont de même classe ou ces deux autres ne sont pas de même classe (link, cannot-link).
Dans le cas de l’apprentissage actif [4] (une des formes d’apprentissage en interaction), l’idée est de chercher à chaque pas les exemples les plus informatifs. Il consiste à combiner la construction de modèles à partir de données issues d’expérience avec un système visant à produire de nouvelles données de manière à accélérer l’apprentissage. Il peut donc choisir judicieusement les exemples que l’utilisateur (l’expert) doit étiqueter de façon à minimiser l’effort qui lui est demandé ou le temps d’apprentissage.
L’apprentissage par renforcement [5] fait comme l’apprentissage actif partie des formes d’apprentissage en interaction. Il fait référence à une classe de problèmes d’apprentissage automatique, dont le but est d’apprendre, à partir d’expériences, ce qu’il convient de faire en différentes situations, de façon à optimiser une récompense numérique au cours du temps. Un paradigme classique pour présenter les problèmes d’apprentissage par renforcement consiste à considérer un agent autonome, plongé au sein d’un environnement, et qui doit prendre des décisions en fonction de son état courant. En retour, l’environnement procure à l’agent une récompense, qui peut être positive ou négative. L’agent cherche, au travers d’expériences itérées, un comportement décisionnel (appelé stratégie ou politique, et qui est une fonction associant à l’état courant l’action à exécuter) optimal. C’est une forme d’apprentissage adaptée en cas d’information partielle (la récompense indique si on est proche de la bonne prédiction d’en dévoiler ce qu’aurait été la décision optimale à la différence de l’apprentissage supervisé). Comme pour l’apprentissage actif, il s’agit de trouver un bonne politique, compromis entre l’exploitation du modèle courant et l’exploration d’un nouveau meilleur modèle (en réitérant par exemple de nouvelles expériences).
Pour la suite des méthodes, il est à présent utile de poser quelques éléments supplémentaires. En effet, la disponibilité des exemples varie : tous dans une base de données, tous en mémoire, partiellement en mémoire, un par un dans un flux… On trouve dans la littérature différents types d’algorithmes selon la disponibilité et la taille des données. La figure ci-dessous présente ces différents types d’accès aux données.
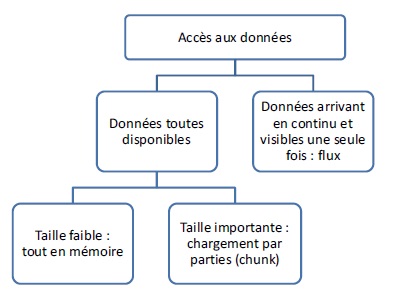
Si les données peuvent être toutes chargées en mémoire alors l’algorithme a, à tout moment, accès à toutes les données. Cette hypothèse correspond au cas le plus simple sur lequel repose la plupart des algorithmes. Mais parfois la quantité d’exemples peut être très importante, et il est impossible de tous les charger en mémoire. Il faut donc concevoir un algorithme qui puisse générer un modèle sans avoir besoin que tous les exemples soient en mémoire. On peut alors chercher à découper les données en plusieurs ensembles (chunks) de manière à pouvoir les traiter les uns après les autres et ne pas avoir à tout charger en mémoire et / ou à utiliser des techniques de parallélisation de l’algorithme d’apprentissage.
Dans le pire des cas, les données sont très volumineuses et arrivent de manière continue, on parle alors de flux de données. Les exemples ne peuvent être vus qu’une seule fois et dans l’ordre dans lequel ils arrivent. L’algorithme doit réaliser l’apprentissage suffisamment rapidement pour suivre le flux de données. La spécificité principale des flux vient du fait que les données (leurs distributions) peuvent changer au cours du temps et qu’il faut donc apprendre une suite de modèles. On parle alors de changement de concept. Celui-ci doit être pris en compte par les algorithmes d’apprentissage pour les flux.
L’apprentissage hors-ligne [6] correspond à l’apprentissage d’un modèle sur un jeu de données disponible au moment de l’apprentissage. Ce type d’apprentissage est réalisable sur des volumes de taille faible à moyenne (jusqu’à quelques dizaines Go). Au-delà, le temps d’accès et de lecture des données devient prohibitif, et il devient difficile de réaliser un apprentissage rapide (qui ne prenne pas des heures ou des jours). Ce type d’algorithme montre ses limites dans le cas où les données ne sont pas entièrement chargeables en mémoire ou arrivent de manière continue ; (ii) la complexité calculatoire de l’algorithme d’apprentissage est supérieure à une complexité dite quasi-linéaire. L’apprentissage incrémental est bien souvent une alternative intéressante face à ce genre de problème.
L’apprentissage incrémental [7] correspond à un système capable de recevoir et d’intégrer de nouveaux exemples sans devoir réaliser un apprentissage complet. Un algorithme d’apprentissage est incrémental si, pour n’importe quels exemples il est capable de produire des modèles tel que le nouveau modèle ne dépende que du précédent modèle et de l’exemple courant. Par extension de la définition, la notion d’exemple courant peut être étendue à un résumé des derniers exemples vus, résumé utile à l’algorithme d’apprentissage utilisé. La propriété désirée d’un algorithme incrémental est un temps d’apprentissage beaucoup plus rapide, par comparaison à un algorithme d’apprentissage hors-ligne. Pour atteindre cet objectif, les algorithmes ne lisent souvent qu’une seule fois les exemples, ce qui permet en général de traiter de plus grandes volumétries.
Le qualificatif d’apprentissage « en-ligne » [8] est ajouté lorsque l’arrivée des exemples se fait de manière continue pour réaliser l’apprentissage. Les exigences en termes de complexité calculatoire sont plus fortes que pour l’apprentissage incrémental. Par exemple, on cherchera à obtenir une complexité calculatoire constante en O (1) si l’on désire réaliser un algorithme d’apprentissage à partir de flux. Il s’agit d’apprendre et de prédire à la vitesse du flux. Bien souvent s’ajoutent à cette différence essentielle des contraintes de mémoire et des problèmes de dérive de concept.
En général la mise en place d’un modèle de prédiction se réalise en deux étapes : une étape d’apprentissage du modèle, (ii) une étape de déploiement du modèle. Dans le cas d’un apprentissage non incrémental ces étapes sont réalisées l’une après l’autre mais dans le cas de l’apprentissage incrémental, on repasse en phase d’apprentissage dès qu’un nouvel exemple arrive. Cette phase peut être plus ou moins longue et il est parfois nécessaire de pouvoir en maîtriser la complexité calculatoire.
On peut alors essayer de définir le concept d’algorithme d’apprentissage et/ou de prédiction anytime [8] : capable d’être arrêté à tout moment et de fournir un modèle et/ou une prédiction, (ii) la qualité du modèle et/ou de la prédiction sont proportionnels au temps consommé.
La famille des algorithmes par contrat est assez proche de celle des algorithmes anytime. On peut « s’intéresser à » proposent un algorithme s’adaptant aux ressources (temps / processeur / mémoire) qui lui sont passées en paramètres (comme par exemple le problème dit du « sac à dos »).
Enfin on parlera de l’apprentissage par transfert [9], de plus en plus utilisé notamment par la communauté « deep learning ». L’apprentissage par transfert peut être vu comme la capacité d’un système à reconnaître et appliquer des connaissances et des compétences, apprises à partir de tâches antérieures, sur de nouvelles tâches ou domaines partageant des similitudes. Par exemple comment le fait d’avoir appris à reconnaitre des chats dans une image peut-il m’aider à transférer cette connaissance (ou le modèle appris) vers la reconnaissance de tigres, …, d’éléphants ?
Il va de soi que chacune de ses formes d’apprentissage peut plus ou moins changer de nom selon la nature des données sur lequel elle est exercée (texte, graphe, logs…) et que toutes les formes d’apprentissage n’ont pas été abordées dans cette introduction.
Quelques enjeux et éléments quantitatifs
L’idéal serait d’avoir des outils permettant de réaliser ces différentes formes d’apprentissage selon les critères d’évaluation suivants :
- sans paramètres utilisateurs
- avec une capacité de passage à l’échelle (scalablité et parcimonie)
- dynamique (interactions)
- rapide et précis
- sachant apprendre à apprendre (transfert)
- dont les modèles soient interprétables
- donc les connaissances découvertes soient actionnables
- ayant une bonne généralisation (bien faire sur les futures données qu’on ne connait pas)
L’atteinte de tout ou partie de l’ensemble de ces objectifs a bien sur un coût que nous n’avons pas explicité jusqu’ici mais qui devrait être pris en compte. Ces coûts et leur analyse (compromis gains / performances / coûts / généralisation / …) ne sont pas souvent présentés dans la littérature. On cite néanmoins à titre d’exemple :
- pour les flux de données l’étude menée par Indrė Žliobaitė et al. dans « Towards cost-sensitive adaptation: When is it worth updating your predictive model? » Neurocomputing, 2015
- pour les architectures de type « deep learner » l’étude menée par par Alfredo Canziani et al. dans « An Analysis of Deep Neural Network Models for Practical Applications », ArXiv : 1605.07678v4, 2017, où il est montré qu’une architecture plus « light » peut être aussi (ou proche) performante qu’une architecture plus coûteuse. Les architectures « résiduelles » sont même très légères en nombre de paramètres.
L’accès aux données est aussi un facteur très important selon la méthode d’apprentissage et le modèle utilisé. Certains modèles peuvent bien apprendre avec peu [10], d’autres au contraire nécessitent de vaste de jeu de données pour pouvoir être correctement entrainés et atteindre des performances raisonnables; ceci tout en sachant que l’adaptation plus ou moins incrémentale des modèles est souvent requise afin de se prémunir des variations dans les données au cours du temps.
Enfin ces outils et méthodes doivent être aussi être développés, utilisés, par des personnes qualifiées… Dans un processus, projet, de fouille de données (data mining) trois experts, trois rôles, issus de métiers différents doivent cohabiter : l’expert métier, l’expert des systèmes d’information et l’expert « data miner, statisticien ». Aux différentes étapes du projet, il y a un besoin continu de participation dans chacun de ces rôles. On pourrait espérer que ces trois rôles soient tenus par la même personne mais le célèbre mouton à cinq pattes (data scientist couvrant les 3 rôles) n’existe pas. Des personnes différentes doivent donc tenir les différentes facettes de ces rôles et il peut exister une tension sur la capacité à recruter ou à conserver des personnes de qualité.
En effet la progression dans le temps de l’utilisation des méthodes d’apprentissage (machine learning) croît plus vite que le nombre d’analystes formés. Un enjeu consiste donc à ce que les utilisateurs des méthodes (développées éventuellement par d’autres) restent bien formés de sorte à les utiliser correctement : paramétrage et interprétation à titre exemple. Or nombre d’entreprise recherche de nos jours des « utilisateurs » de boites à outils qui ne maitrisent pas nécessairement les algorithmes sous-jacents ce qui peut induire de mauvaises utilisations.
En savoir plus :
Les auteurs :
Références bibliographique citées dans le texte ci-dessous :
- [1] R. O. Duda et al, “Pattern Classification”, chapter « Unsupervised Learning and Clustering”. Wiley Inter science (2001)
- [2] S. Kotsiantis. “Supervised machine learning: A review of classification techniques”. Informatica Journal, 31 :249–268 (2007)
- [3] O. Chapelle, “Semi-supervised Learning”. MIT Press (2006)
- [4] B. Settles, “Active Learning”, Synthesis Lectures on Artificial Intelligence and Machine Learning. Morgan and Claypool Publishers (2012)
- [5] R. Sutton et al, “Reinforcement Learning – An Introduction”, MIT Press (2012)
- [6] A. Cornuéjols et al, “Apprentissage artificiel Concepts et algorithmes”, Eyrolles (2010)
- [7] A. Gepperth et al, “Incremental learning algorithms and applications”, ESANN (2016)
- [8] S. Shalev-Shwartz, “Online learning: Theory, Algorithms, and Applications ». PhD Thesis, the Hebrew university (2007).
- [9] Sinno Jialin Pan et al, « A survey on transfer learning », IEEE Transactions on Knowledge and Data Engineering, no 20(10), (2010).
- [10] Salperwyck et al, « Learning with few examples: an empirical study on leading classifiers International Joint Conference on Neural Networks (2011)







