L’identification des personnes présentes est une fonctionnalité attendue pour l’indexation et la navigation dans les contenus audiovisuels. Elle requiert l’analyse conjointe de l’image et du son, suivie d’un processus de fusion multimodale. Le consortium PERCOL, auquel participaient des chercheurs d’Orange Labs aux côtés des laboratoires d’informatique des universités d’Aix-Marseille, Avignon et Lille, a remporté au printemps 2014 la phase finale du défi pluriannuel REPERE financé par l’ANR, portant sur l’identification multimodale des personnes dans les émissions TV.
L’identification des personnes, pour quoi faire ?
L’identification des personnes présentes dans les émissions TV est une fonctionnalité dont l’intérêt est manifeste et immédiatement compris par nos clients: rechercher les dernières apparitions d’une personnalité médiatique, écouter les déclarations de telle personnalité politique ou naviguer dans des émissions « people », en allant d’invité en invité, sont autant de fonctions spontanément évoquées par les utilisateurs d’un moteur de recherche de TV de rattrapage.
Comment ?
Pour identifier les personnes présentes, on peut utiliser des approches biométriques de reconnaissance de la voix et du visage. Cette approche a ses limites, pour 2 raisons. D’une part, les technologies de reconnaissance biométriques de voix et du visage sont encore limitées. Même si la reconnaissance du locuteur, dans des conditions acoustiques de bonne qualité comme le sont celles des contenus TV, permet de reconnaître les personnes avec des bonnes performances, elle ne peut traiter pour l’instant que des dictionnaires de quelques centaines de personnes. Quant à la reconnaissance des visages, dans les conditions de pose et d’éclairage très variables des contenus TV, ses performances sont encore assez faibles, et cela, même avec des dictionnaires restreints à quelques dizaines de personnes. D’autre part, même si les performances de la reconnaissance biométrique s’améliorent, les questions de la taille forcément limitée du dictionnaire biométrique et de sa mise à jour constitueront toujours un verrou : en effet, les personnes présentes dans les contenus TV peuvent être considérées comme un ensemble ouvert, où de nouvelles personnalités apparaissent chaque jour au fil de l’actualité.
D’autres sources d’informations sont possibles pour identifier les personnes, par leurs noms, incrustés à l’écran, ou prononcés par leurs interlocuteurs. Ainsi, dans de nombreux contenus de type documentaire, talk-show ou informations, le nom des personnes présentes est incrusté dans l’image, lors de leur première prise de parole par exemple. D’autre part, les invités sont souvent présentés oralement, par l’animateur de l’émission. Ainsi, si on est capable de reconnaître les noms incrustés à l’écran, ou si l’on est capable d’identifier dans le flux de parole, les noms de personnes, et, par l’analyse du contexte linguistique, de discriminer entre un nom de personne simplement citée dans l’émission et un nom de personne présente dans l’émission, voilà autant d’indices pour identifier les personnes. L’identification finale est faite grâce à ces indices, les scores biométriques quand ils sont disponibles, et une structuration du contenu TV en personne visible ou qui parle.
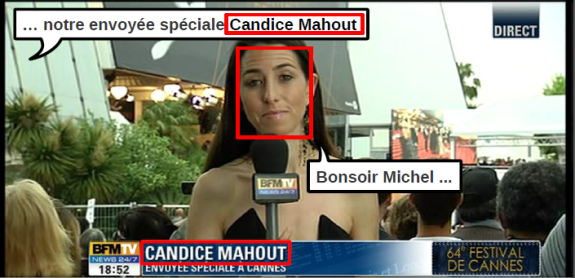
Un tel processus met donc en jeu de nombreuses briques technologiques (reconnaissance du locuteur, reconnaissance des textes incrustés, reconnaissance de la parole, analyse linguistique, détection et suivi des visages, reconnaissance des visages…) ainsi qu’une brique de fusion multimodale de toutes les sorties des briques technologiques. Cette brique de fusion multimodale doit prendre en compte, outre le fait que les sorties des briques technologiques soient possiblement erronées, les problèmes d’a-synchronie (la personne qui parle n’est pas toujours visible, et la personne qu’on voit ne parle pas toujours), et les problèmes d’insuffisance de données (les personnes à identifier peuvent être ou non dans les dictionnaires biométriques, peuvent avoir ou non leur nom incrusté dans la vidéo…).
le défi REPERE
L’ANR a proposé en 2010 un défi pluriannuel, pour mettre en compétition plusieurs consortiums, sur la tâche d’identification des personnes dans les contenus TV. Trois consortiums ont été sélectionnés et financés pour participer à ce défi, au travers de trois campagnes annuelles d’évaluation. Les chercheurs d’Orange Labs ont participé au consortium PERCOL, aux côtés des laboratoires d’informatique des universités d’Aix-Marseille, Avignon et Lille. Les 3 campagnes d’évaluation successives ont permis une progression très significative de l’état de l’art, et PERCOL a remporté la phase finale du défi, au printemps 2014. La contribution d’Orange Labs dans ce succès a été majeure, puisque nous avons développé avec nos partenaires des technologies d’analyse de la parole et de l’image ainsi que le système de fusion des analyses audio et visuelle.
Les résultats du défi montrent que l’on peut identifier correctement plus de 80 % des personnes qui parlent dans les émissions traitées, et ouvrent des perspectives intéressantes sur le traitement de collections entières d’émissions.
En 2015, cette thématique de recherche se poursuit au sein d’une nouvelle tâche « Person Discovery in TV » dans la campagne d’évaluation internationale MediaEval, et Orange a soumis un projet ANR, avec l’INA et des partenaires académiques ayant concouru dans le défi REPERE, portant sur l’indexation des personnes sur des gros volumes d’archives audiovisuelles.
En savoir plus :
[1] F. Bechet, M. Bendris, D. Charlet, G. Damnati, B. Favre, M. Rouvier, R. Auguste, B. Bigot, R. Dufour, C. Fredouille, G. Linarès, J. Martinet, G. Senay, P. Tirilly. Multimodal Understanding for Person Recognition in Video Broadcasts. Interspeech 2014, Fifteenth Annual Conference of the International Speech Communication Association, 2014.
[2] H. Bredin, A. Laurent, A. Sarkar, V.-B. Le, S. Rosset, C. Barras. Person Instance Graphs for Named Speaker Identification in TV Broadcast. Odyssey 2014: The Speaker and Language Recognition Workshop, 2014.
[3] G. Bernard, O. Galibert, J. Kahn. The First Official REPERE Evaluation. SLAM 2013, First Workshop on Speech, Language and Audio for Multimedia, 2013.
[4] A. Giraudel, M. Carré, V. Mapelli, J. Kahn, O. Galibert, L. Quintard. The REPERE Corpus: a Multimodal Corpus for Person Recognition. LREC 2014, Eighth International Conference on Language Resources and Evaluation, 2014.
[5] J. Poignant, L. Besacier, G. Quénot. Unsupervised Speaker Identification in TV Broadcast Based on Written Names. IEEE/ACM Transactions on Audio, Speech, and Language Processing, Vol. 23, No. 1, 2015.