


Résumé
Le “Fog Computing” (“informatique dans le brouillard”) génère un intérêt grandissant dans les domaines du Cloud Computing (« informatique dans le nuage »). En 2011, Cisco en a donné une des premières définitions : « Le Fog Computing est une plateforme hautement virtualisée, qui fournit des services de traitement, de stockage et de réseau entre les terminaux et les centres de données utilisés par le Cloud Computing traditionnel. » La métaphore est construite sur l’image « du brouillard qui est un nuage proche de la Terre ».
L’Internet des objets est présenté comme la principale motivation pour le « Fog Computing ». Les bénéfices attendus du Fog Computing sont : de meilleures latences, une qualité d’expérience supérieure pour les utilisateurs et moins de trafic dans les cœurs de réseaux, mais aussi une plus grande sécurité (localisation des données sensibles, plus grande surface d’attaque) et résilience (pas de points uniques de défaillance).
Les chercheurs d’Orange investiguent ces sujets dans le cadre d’un partenariat noué notamment avec l’Inria autour de l’initiative Discovery (une action du laboratoire commun Orange-Inria ), qui vise à concevoir un système de gestion distribuée des ressources plus apte à prendre en compte la dispersion géographique des « devices » (terminaux mobiles des utilisateurs, capteurs/actionneurs de l’IoT, etc.).
Article complet
Fog Computing = Cloud + Internet des Objets
Le « Fog Computing » (« Informatique dans le brouillard ») génère un intérêt grandissant dans les domaines du cloud computing (« informatique dans le nuage », « infonuagique »). Plusieurs articles commentant la vision de Cisco, dont un du Wall Street Journal qui est souvent considéré comme l’une des sources initiales, ont donné lieu à de nombreux discussions et débats en ligne. Des évènements scientifiques (par exemple FOG, ManFog) apparaissent également dans la communauté scientifique.
La vision originelle de Cisco a été révélée dans une conférence invitée lors d’un symposium international en 2011, puis développée ensuite dans plusieurs articles scientifiques émanant de la recherche de Cisco.
La métaphore est construite sur l’image « du brouillard qui est un nuage proche de la terre ».
De nombreuses applications bénéficient du « cloud traditionnel » avec ses économies d’échelle dues à une agrégation massive d’équipements dans de grand centres de données. Ceci n’est pas le cas, néanmoins, pour de nombreuses autres applications – telles que celles qui requièrent des latences faibles et prédictibles, de la mobilité et de la localité, qui ont intrinsèquement une large distribution géographique, avec un accès sans fil prédominant et une connectivité variable.
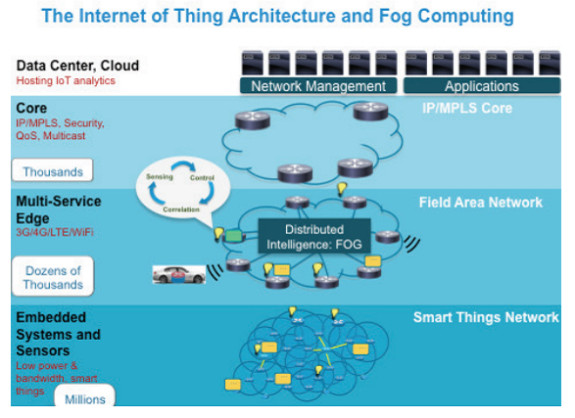 Les applications de l’Internet des Objets (IoT en anglais) présentent ces caractéristiques. C’est la raison pour laquelle l’Internet des Objets est présenté par Cisco comme la principale motivation pour le « Fog Computing » d’un point de vue économique/industriel, avec des applications typiques dans les domaines des véhicules connectés, des réseaux électriques intelligents (« smart grid »), des réseaux sans fils de capteurs et « actuateurs ».
Les applications de l’Internet des Objets (IoT en anglais) présentent ces caractéristiques. C’est la raison pour laquelle l’Internet des Objets est présenté par Cisco comme la principale motivation pour le « Fog Computing » d’un point de vue économique/industriel, avec des applications typiques dans les domaines des véhicules connectés, des réseaux électriques intelligents (« smart grid »), des réseaux sans fils de capteurs et « actuateurs ».
L’architecture de référence proposée par Cisco (cf. figure ci-dessus) illustre le rôle prédominant de l’Internet des Objets dans le développement du « Fog Computing ». Le rôle de la couche « Fog » est de collecter les données issus des capteurs et terminaux, de traiter localement ces données, puis de renvoyer des commandes de contrôle aux actuateurs. La couche « Fog » peut également filtrer, agréger, puis « remonter » ces données « plus haut dans le réseau », possiblement jusqu’à un centre de données éloigné, à des fins de traitement par lots (« batch processing ») et analyse (« Big Data »).
« Le Fog peut soulager le réseau. Avec 50 milliards d’objets qui deviendront connectés dans le monde d’ici 2020, cela ne fera pas de sens de tout gérer dans le cloud. Les applications distribuées et les terminaux en bordure de réseau ont besoin de ressources distribuées. Le Fog rapproche les traitements des données. Les terminaux à faible énergie, à proximité de la bordure du réseau, peuvent délivrer une réponse en temps réel » explique Rodolfo Milito de Cisco.
Autres initiatives autour du cloud géo-réparti
NTT développe un concept d’ »Informatique en bordure de réseau » (« Edge Computing ») « qui peut réduire le temps de réponse des applications du cloud jusqu’à un facteur 100, comme démontré dans son premier résultat de recherche, le prototype d’accélération Web en bordure ». L’idée, très proche de celle de Cisco, est de localiser de petits centre de données à proximité des utilisateurs et des terminaux afin d’éviter d’envoyer tous les traitements à de grands centres de données distants. NTT cite des applications qui pourraient bénéficier le plus de cette vision : les bâtiments et villes intelligentes (« smart buildings/cities »), le « Machine-to-Machine », le domaine médical, les jeux vidéo en ligne, la reconnaissance de la voix ou la reconnaissance d’images.
AT&T Labs Research développe une vision du cloud réparti appelée Cloud 2.0 qui ressemble au Fog Computing: « Etant donné les capacités de traitement croissantes des terminaux, les chercheurs ont proposé une nouvelle architecture hybride qui vise à équilibrer traitements locaux et téléchargements à distance pour des solutions plus flexibles. Le Cloud 2.0 se base sur ce principe en étendant les capacités traditionnelles du cloud pour promouvoir les traitements locaux dès que possible ». L’idée centrale est de favoriser les capacités de stockage et de traitements locaux par un terminal ou une fédération de terminaux (e.g. une combinaison de téléphones et autres terminaux mobiles, « boxes », ordinateurs personnels) via une coopération entre terminaux, dans la lignée du « Device-to-Device (D2D) » dans lequel les terminaux personnels ne sont pas juste des équipement réseaux terminaux mais réellement des éléments du réseau avec des capacités de communication (routage) – tout en maintenant le stockage et les traitements dans des clouds traditionnels pour les applications qui ne peuvent pas se contenter uniquement de ressources locales, et/ou pour le stockage et les traitements qui sont intrinsèquement accédés par des terminaux et utilisateurs distants.
Intel travaille sur le « Cloud en bordure » (« Cloud Computing at the Edge ») qui vise la distribution du stockage et calcul dans le cloud au sein des éléments du réseau d’accès radio (« Radio Access Network », RAN). Des expérimentations sur le terrain se déroulent actuellement avec plusieurs sociétés. Saguna Networks, par exemple, optimise la livraison de contenus en poussant des caches de stockage dans la station de base, la cellule ou l’agrégateur.
IBM et Nokia Siemens Networks ont annoncé une collaboration pour construire une initiative similaire…
Ce que font les Orange Labs sur le sujet
Les principaux bénéfices attendus du Fog Computing sont de meilleures latences et Qualité d’Expérience pour les utilisateurs, moins de trafic dans les cœurs de réseaux. D’autres bénéfices attendus incluent une plus grande sécurité (localisation des données sensibles, plus grande surface d’attaque) et résilience (pas de points uniques de défaillance). Ces arguments sont attirants pour les opérateurs de télécommunications qui doivent faire face à une explosion du trafic et qui sont souvent blâmés par les utilisateurs en cas de piètre qualité d’expérience.
Une autre opportunité mise en avant par la recherche des Orange Labs est de construire un cloud réparti dans le réseau (« in-network distributed cloud »), i.e. de distribuer le cloud dans les points de présence de l’opérateur de manière à transformer le réseau – vu comme un continuum depuis de grands centre de données jusqu’aux terminaux/capteurs en passant par les points de présence réseau – en une plate-forme de cloud réparti (pour le stockage et le traitement) qui pourrait être monétisée auprès des fournisseurs de services Internet. Ceci pourrait réellement donner une position différenciante aux opérateurs de télécommunications dans le Cloud et l’Internet des Objets.
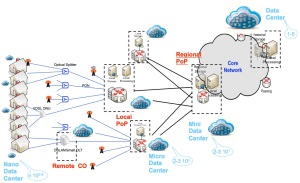
La recherche d’Orange investigue ces sujets dans le cadre d’un partenariat avec l’INRIA et d’autres acteurs dans le contexte de l’initiative de recherche ouverte Discovery. Discovery vise à proto-typer une infrastructure d’informatique utilitaire basée sur la géo-localisation : « contrairement à la tendance actuelle qui vise à construire des centre de données de plus en plus grands dans quelques lieux stratégiques, le consortium Discovery propose d’utiliser n’importe quel point de présence réseau existant disponible sur Internet » (cf. Figure ci-dessus avec des mini/micro centre de données dans les futurs réseaux d’Orange).
En savoir plus :
- Forget ‘the cloud’: ‘the Fog’ is Tech’s Future. Christopher Mims. The Wall Street Journal, 2014.
- Cloud and Fog Computing: Trade-offs and applications. Flavio Bonomi, Cisco. International Symposium of Computer Architecture, 2011.
- Fog Computing and Its Role in the Internet of Things. Flavio Bononi and al, Cisco. ACM SIGCOMM International Conference on Mobile Cloud Computing, 2012.
- Improving Web Sites Performance Using Edge Servers in Fog Computing Architecture. Jiang Zhu and al, Cisco. IEEE International Symposium on Service-Oriented System Engineering, 2013.
- Cisco Technology Radar Trends, chapter Fog Computing. Cisco, 2014.
- Announcing the “Edge computing” concept and the “Edge accelerated Web platform” prototype to improve response time of cloud. NTT Press Release, 2014.
- I’m Cloud 2.0, and I’m Not Just a Data Center. Emiliano Miluzzo, AT&T Labs Research. IEEE Internet Computing, 2014.
- Increasing Network ROI with Cloud Computing at the Edge. Intel Solution Brief, 2014.
- Beyond the Clouds! An Open Research Initiative for a Fully Decentralized IaaS Manager.







