- Data
- Décisions et connaissance
- Infrastructure logicielle
- Société numérique soutenable
- Univers Cyber-Physique


Quel est le point commun entre Blablacar, LaFourchette, AirBnB, Uber, Android, Kindle, Facebook, Wikipedia (…) ? Ce sont des exemples emblématiques de plateformes multi-faces (“multi-sided platforms”/MSPs). Définies et étudiées à l’origine par les économistes, elles sont devenues largement médiatisées, surtout depuis que Jean Tirole, pionnier de la recherche dans ce domaine, a reçu le prix Nobel d’Économie, en 2014.
Les plateformes multi-faces sont, de notre point de vue, des ensembles cohérents de composants ou de services qui supportent une médiation de l’information nécessaire à des transactions entre différentes catégories d’utilisateurs (correspondant aux différents « faces » du marché adressé dans la vision des économistes). Les MSPs génèrent typiquement des économies d’échelle en faisant jouer les effets de réseau à partir de l’extrémité des chaînes de valeur correspondant à la demande, plutôt que du côté de l’offre, comme c’était le cas dans l’économie traditionnelle.
Ces plateformes sont au cœur de l’économie en réseaux. Ce sont les moteurs de la destruction créatrice des acteurs en place qui verrouillaient l’accès aux marchés existants, cloisonnés et verticalement intégrés. Leurs modèles d’affaires et de prix ont été largement étudiés, de même que les incitations qui peuvent susciter la croissance inter-entretenue des affiliations aux différentes faces de la plate-forme en faisant jouer les effets de réseau croisés. Pourtant, en dépit de leurs proclamations d’ouverture superficiellement affichées comme subversives, la majorité de ces plateformes sont des silos de données fermés et gérés par un opérateur exclusif. Les opérateurs de plateformes sans but lucratif comme la fondation Wikimedia sont l’exception plutôt que la règle. La proposition réellement radicale est celle de plateformes entièrement réparties et non gérées par un acteur unique, qui, quand elles existent, peuvent mettre en jeu des effets de réseau impossibles à atteindre par une solution centralisée. Le Web reste l’exemple le plus parfait d’une telle plate-forme entièrement décentralisée permettant une croissance organique par le bas. Le Web réussit toujours à servir de point d’entrée et de connexion minimale entre toutes les autres plateformes : si opaques et propriétaires que soient ces plateformes (comme c’est le cas de réseaux sociaux bien connus) le fait d’être accessibles par le web leur apporte malgré tout une ouverture minimale.
Le Web d’origine a été conçu à destination d’utilisateurs humains. Le «Web des données », porté par la multiplication des données offertes en « Linked Data », est une proposition bien plus radicale, destinée à fédérer non seulement des documents consommés par les lecteurs humains, mais tous les éléments de données consommés par des programmes, à toutes granularités. Le Web des Données a le potentiel de fédérer les plateformes existantes pour générer à partir de leurs données des effets de réseau dont elles bénéficieraient en retour.
Pourrait-il les remettre en question ? Peut-on imaginer que le Web des données et des ressources programmables absorbe les MSPs existants dans une méta-plateforme, comme les MSPs ont absorbé ou remplacé leurs prédécesseurs moins compétitifs ? Les MSPs qui sont déjà quelque millions (ou milliards) d’utilisateurs dans leur dépendance n’ont probablement rien à craindre… Nous nous focalisons ici sur le domaine très fragmenté de l’Internet des Objets (IoT), pour lequel il n’y a pas de MSPs dominantes ou fédératrices, seulement des myriades de solutions de collecte de données de bas niveau et à portée très limitée. Même promu au rang d’un Web des Objets, l’IoT a un besoin pressant d’être dé-compartimentalisé, et son intégration dans le Web des Données peut être une proposition gagnante pour cela, en fédérant son archipel de micro-plateformes dans le « Web sémantique des objets ».
Du Web des documents au Web des Objets et au Web programmable
Si extraordinaire qu’ait pu être son succès en tant que plateforme biface (documents hypertextes / utilisateurs humains), le web des origines conserve un potentiel d’extension encore plus grand, des deux côtés, en tirant parti de l’universalité de ses protocoles. Du côté inférieur, il peut adresser, au delà des documents texte ou multimedia qui étaient sa cible initiale, tous les objets physiques du monde réel. Cette idée peut avoir différentes incarnations dans la pratique. Ces objets peuvent être des équipements (devices) directement connectés à un réseau, et ils peuvent alors exposer directement une interface « niveau Web » de leur fonctionnalité, quelle qu’elle soit, au travers du réseau: typiquement un actionneur fournira une interface pour l’action à distance et un capteur fournira une interface pour la collecte de données à distance. Pour des objets qui ne sont pas des devices connectés, le Web des objets peut intégrer des descriptions, des représentants ou des modèles informationnels de ces objets. De façon moins évidente, tout objet physique peut avoir en tant que tel sa propre identification dans le Web des Objets (au titre de «ressource non-informationnelle »), identification qui le distingue de son représentant informationnel (comme le numéro de sécurité sociale d’une personne est distinct d’une adresse de profil sur un réseau social). Cette adresse peut le cas échéant, rediriger vers une interface de monitoring supportée par des capteurs qui permettent de connaître l’état de l’objet en question (par exemple une caméra qui permet d’en observer l’état), ou la description/représentation déjà mentionnée. Le graphe du Web des objets devient, dans ce point de vue, étendu pour inclure en tant que nœuds les objets physiques eux-mêmes, et pas seulement leurs « ombres informationnelles ».
Du côté de l’utilisation des données, l’extension décisive consiste à utiliser les protocoles Web comme interface universelle accessible par des programmes, et pas seulement par des humains, ce qui conduit à l’idée du Web programmable. Cette extension est bien évidemment associée à la précédente (vers les objets physiques), du fait que la plupart des données sur l’environnement ne sont pas d’un intérêt direct pour des utilisateurs humains, et doivent au moins être filtrées, traitées et analysées avant de pouvoir leur être utile.
Le web sémantique, une fausse bonne idée ?
L’origine de la notoriété (sinon l’idée même) du web sémantique pourrait être datée de l’article éponyme de Tim Berners-Lee pour Scientific American en 2001, article qui est devenu depuis lors l’une des publications les plus citées (~ 20 000 citations à ce jour …) dans toute la littérature des Sciences et Technologies de l’Information ! Cette popularité est trompeuse, parce que l’utilisation effective du web sémantique par les praticiens (développeurs et webmasters) n’a pas suivi cette reconnaissance universelle qu’il s’agirait bien, en effet, d’une excellente idée …
Basiquement le web sémantique peut être vu comme la superposition, sur le web des documents, d’un graphe sémantique, dont les nœuds définissent, par leurs relations mutuelles, les concepts, les classes et les catégories à partir desquelles les instances et les sous-classes d’entités représentées ou décrites dans les documents sont dérivées. Le but est de rendre le sens des documents en langage naturel ou les identificateurs utilisés dans de tels documents explicites et compréhensibles par des programmes, pas seulement par des lecteurs humains. Le déploiement effectif du web sémantique dans son ambition initiale demanderait, en principe, une annotation a priori de tous les termes clé utilisés dans les documents web par référence des ontologies formellement définies. Ceci représente un travail immense, et en fait totalement irréaliste pour les documents et sites Web déjà existants. Les ontologies en question définissent les termes pertinents de manière formelle en spécifiant la nature de leurs relations à des termes plus généraux et complémentaires. Elles forment un graphe acyclique orienté multi-niveau, qui inclut une hiérarchie allant d’ontologies spécifiques à un domaine jusqu’à des ontologies transversales et supérieures. Ce graphe sémantique, aussi chimérique que puisse paraître l’ambition de sa couverture universelle en largeur et en profondeur, est censé représenter la clé de voûte de l’architecture du web sémantique. Quinze ans après, cette superstructure sémantique globale du web n’est encore qu’une juxtaposition hétéroclite d’ontologies fragmentaires et très hétérogènes, superbe dans certains domaines et fâcheusement déficiente dans d’autres. Dans la situation actuelle, les moteurs de recherche ont appris à compenser le manque de sémantique incorporée dans leurs principales sources de contenu en laissant cette sémantique émerger de la structure des liens et percoler en quelque sorte à partir de cette structure même. Si puissant qu’il puisse être, ce «graphe de la connaissance» reste une propriété exclusive des opérateurs de moteurs de recherche, très loin de la plate-forme ouverte et universelle que le web sémantique aurait pu devenir. Les moteurs de recherche restent toujours orientés vers le Web comme plate-forme à destination directe d’utilisateurs humains et ils n’adressent pas (encore) les besoins du web programmable, où des approches moins intensives en volume de données peuvent encore avoir un rôle à jouer.
Linked Data: la sémantique de terrain
Le programme « Linked Data » ou du « Web des données », initié, une fois encore, par Sir Tim lui-même, a émergé comme une approche plus pragmatique à partir de l’inaccomplissement de la vision initiale « de haut en bas » du web sémantique, impliquant l’usage d’une hiérarchie extensive d’ontologies. Le Web des données est, en un sens, un retour à l’idée d’origine et à l’essence du web vu comme un graphe, en ceci que l’information la plus riche et la plus significative réside dans les arcs du graphe et leur structure, plus que dans les nœuds eux-mêmes. Plus significativement encore, alors que le web sémantique a été initialement conçu comme devant se surajouter au web des documents, le web des données est naturellement et directement une extension du Web des objets et du web programmable. Dans le web des données , les nœuds ne sont pas seulement des documents ou des fragments de texte, ils peuvent correspondre à des données non textuelles de toute nature, de toutes origines et non destinées à des utilisateurs humains. Les liens entres ces différents morceaux de données peuvent être latents ou implicites : ce qui importe est la possibilité de devenir la destination de liens entrants par l’utilisation systématique des identifiants HTTP, reconnaissant le rôle central et universel des protocoles du web pour cela.
Le format RDF (Resource Description Framework) peut être utilisé pour décrire ces éléments de données comme sujets de propriétés qui les relient à des objets, où liens et objets référencent eux-mêmes d’autres URIs, sans qu’il soit obligatoire d’utiliser une hiérarchie complète d’ontologies pour cela. Une analogie peut être faite avec les descriptions de type «folksonomie» ou « social tagging », utilisées pour le marquage des photos sur les sites de partage de photos en ligne ou les réseaux sociaux. Contrairement à des taxonomies rigides, ces balises ne nécessitent pas de se référer à des les catégories tirées d’une hiérarchie prédéfinie, mais une classification stable peuvent néanmoins en émerger si elles sont suffisamment nombreuses. Une autre caractéristique de ces classifications « bottom-up » est que les classifications ou identifications contradictoires peuvent être « réconciliées » après coup, sans la nécessité de remettre en question les étapes précédentes de classification qui avaient conduit au conflit. En supposant qu’une même entité se voit attribuer ainsi deux identités différentes par deux infrastructures différentes, il n’est pas nécessaire de changer ces deux noms (ce qui risquerait de créer des liens brisés et de générer des incohérences en cascade …) pour éviter les conflits: il suffit le les relier entre eux par un lien supplémentaire RDF correspondant au prédicat « owl: sameAs ».
Le web des données définit les principes de la publication de données structurées de manière à ce qu’elles puissent être interconnectés pour permettre la requête et la découverte de connaissances. Les principes de base du Web des données sont :
- Utiliser systématiquement des URIs comme identifiants
- Utiliser des URIs HTTP pour permettre d’obtenir directement l’information correspondante
- Quand quelqu’un (qui peut être un programme) consulte un URI, fournir toutes les informations utiles en utilisant les normes RDF pour la description des données et SPARQL pour la requête de données
- Inclure des liens vers d’autres URIs, afin de permettre la découverte d’autres informations liées

La sémantique pour le REST d’entre nous
REST (de « Representational State Transfer ») est un « style architectural » défini a posteriori à partir du Web d’origine, un ensemble cohérent de principes et de contraintes appliqués aux composants, connecteurs et éléments de données d’un système hypermédia réparti. Ces contraintes sont : ressources systématiquement identifiées par des URI, interfaces uniformes, messages auto-descriptifs, transitions d’état et ressources accessibles décrites par des hyperliens (HATEOAS) et interactions sans état. Le Web of Things utilise REST par défaut, même si de nombreuses interfaces se déclarant abusivement comme « RESTful » ne fournissent pas de liens et n’utilisent pas d’URI comme identifiants .
Les interfaces REST fonctionnent généralement sur HTTP et sont contraintes à l’utilisation d’un répertoire limité de verbes génériques (GET, PUT, POST, DELETE) au lieu des appels de méthodes spécifiques utilisés par les API non-RESTful. Elles tournent autour de la notion de ressource pour associer les entités de toute nature avec un URI, permettant de capturer et d’exposer ses relations à d’autres entités par des hyperliens avec d’autres ressources. Ce principe, le moins bien observé des API REST, est pourtant crucial par rapport à l’idée de Web of Things, puisque les clients des API qui le respectent sont capables de découvrir des ressources connexes à partir d’un point d’entrée : un programme pourrait ainsi naviguer le web programmable des interfaces REST comme un utilisateur humain curieux peut surfer sur le web des documents, en cliquant sur les hyperliens. Ceci est destiné à assurer le découplage crucial des applications avec la plate-forme sous-jacente, de sorte que les deux peuvent mieux évoluer et jouer leurs rôles respectifs indépendamment l’un de l’autre, mais en collaboration. La plate-forme ne demande pas que les applications intègrent, comme une API traditionnelle, la connaissance a priori d’une description déclarative complète de l’interface (une sorte de « mode d’emploi ») qui peut changer au fil du temps et nécessiter la reprogrammation de ces applications.
L’heureuse rencontre des principes REST avec ceux des Linked Data correspond à une sorte d’alignement astral qui est de très bon augure pour l’avenir des plateformes ouvertes! Un standard élégant, concis et pragmatique est apparu au moment opportun pour matérialiser cet alignement.
La lingua franca du Web des données
JSON-LD (JSON for Linked Data), une recommandation (norme officielle) du W3C depuis 2014, est bien placée pour devenir la langue véhiculaire universelle pour le Web des Données, et pour les APIs du Web des Objets. Il étend le langage JSON (JavaScript Object Notation) largement utilisé et appréciée par les développeurs pour la description des contenus associés aux APIs REST, pour y ajouter de la sémantique et des liens. JSON-LD est totalement compatible avec JSON, et les développeurs n’ont besoin que d’ajouter deux mots-clés supplémentaires (@context et @ ID) afin d’utiliser les capacités de base de JSON-LD. « @context » est utilisé pour mettre en correspondance les identifiants courts utilisés dans un document JSON avec des à URIs afin de permettre un référencement sémantique des termes utilisés dans ce document. « @id » définit l’identifiant de référence (sur la base d’un URI) d’un nœud RDF dans un document JSON-LD.
Un exemple : faire le lien entre deux plateformes Internet des Objets
(Description détaillée dans l’annexe liée à ce post, en anglais)
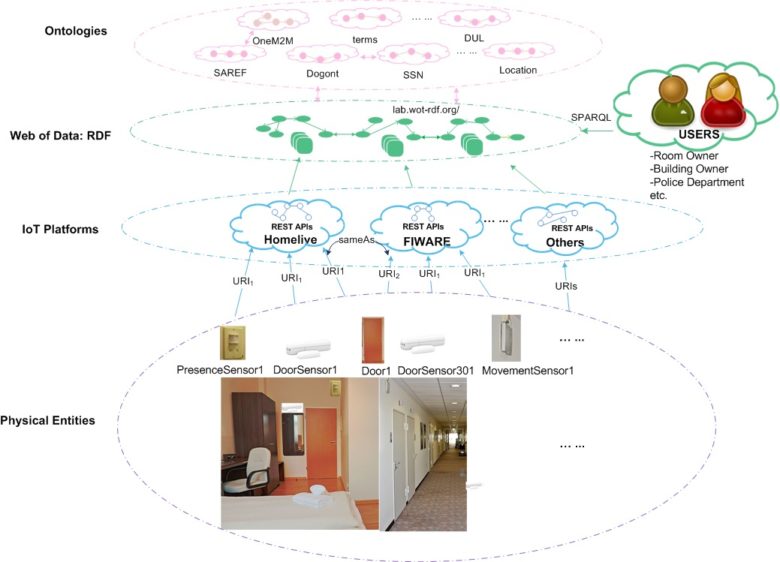
Le diagramme ci-dessous résume le principe de la fédération de plateformes avec JSON-LD. Des plates-formes IoT séparées sont supposés exposer des APIs REST avec des descriptions des ressources JSON. A travers un processus itératif de découverte des ressources liées et d’extraction l’information sémantique, les descriptions JSON des ressources de la plateforme peuvent être intégrées dans des graphes RDF sémantiquement riches. Les référencements sémantiques se font vers des ontologies publiques partagées pour assurer l’interopérabilité entre les plateformes. La connaissance implicite s’en trouve ensuite déduite par inférence et l’on peut « réconcilier » les descriptions des mêmes entités physiques qui auraient été faites différemment par plusieurs plateformes distinctes. Les données provenant de différentes plateformes IoT se trouvent ainsi reliées par la sémantique partagée et l’on peut dire que ces plateformes sont ainsi fédérées au niveau sémantique, comme par une sorte de «méta-plateforme ».
Conclusion
L’adjonction de liens sémantiques entre des plateformes IoT existantes, telle que présentée ici, ne correspond pas elle-même à l’idée d’une plate-forme à part entière et au plein sens du terme, et ne devrait pas être évaluée en tant que telle. Il s’agit au minimum d’un « placage » d’interopérabilité, pragmatiquement mince en profondeur, mais résolument large dans sa portée. Son objectif est d’abord de permettre aux plateformes existantes d’ouvrir leurs API et de partager une partie de leurs données. Ceci doit donc être considéré comme une incitation pour ces plates-formes à adopter des représentations et des interfaces de données qui sont conformes aux principes du web des données, de sorte qu’ils puissent prendre part à cette nouvelle méta plateforme qui permettra aux effets de réseau d’entrer en jeu à son propre niveau tout en préservant les bénéfices d’un fonctionnement décentralisé.
En savoir plus :
« Platform Revolution: How Networked Markets Are Transforming the Economy–And How to Make Them Work for You », Sangeet Paul Choudary, Marshall W. Van Alstyne, Geoffrey G. Parker, W. W. Norton & Company, March 2016
« Matchmakers: The New Economics of Multisided Platforms », David S. Evans & Richard Schmalensee, Harvard Business Review press, May 2016