


• Ils ont organisé des dégustations de vin où 256 participants ont classé des échantillons en fonction de leurs similarités gustatives, utilisant ces données combinées aux étiquettes et aux avis des utilisateurs d’une application de vin pour former un nouvel algorithme.
• Cette approche peut être appliquée à d’autres domaines tels que la bière, le café ou même la santé, offrant des recommandations de produits ou de recettes alimentaires adaptées aux profils de goût individuels.
Comment savoir si un aliment que nous n’avons jamais acheté va nous plaire ? Il est possible de consulter les avis des consommateurs, par exemple sur des applications qui notent les vins. L’avis résultant est limité au goût des autres consommateurs ou à ce que l’emballage indique. À l’Université de Copenhague, une équipe de chercheurs a démontré qu’il est possible, grâce au machine learning, de prédire avec précision les préférences individuelles en matière de vin. « Nous avons collaboré avec l’application Vivino, qui recense des avis de consommateurs sur le vin et des informations détaillées sur les bouteilles, pour constituer une base de données sur les arômes des vins et leurs similarités. Notre objectif était de constituer une carte des arômes », explique Thoranna Bender, qui a mené l’étude sous la tutelle du Pioneer Centre for AI de l’université de Copenhague. L’étude a permis de créer un outil baptisé WineSensed, un vaste ensemble de données multimodales sur le vin qui offre la possibilité d’étudier les relations entre la perception visuelle, le langage et la saveur. Il n’aurait pas été possible de créer cet outil sans intégrer à l’algorithme des données issues d’une étude humaine.
Un système automatique de computer vision a pu reconstituer les matrices représentant les similarités des vins grâce à une analyse spatiale
Une étude de perception humaine complétée par l’informatique
Les chercheurs ont combiné des données collectées à partir de l’application Vivino – plus de 820.000 commentaires – avec des données issues d’une étude à taille humaine : « Nous avons utilisé la méthodologie dite de napping, qui consiste à disposer sur une nappe les vins que les utilisateurs trouvent similaires. Nous avons réalisé plusieurs dégustations avec 256 personnes en leur demandant de faire des commentaires sur les vins. L’objectif est de disposer les vins sur une feuille en les rapprochant si les testeurs les trouvent similaires en termes de goût, sans pouvoir voir ce qu’ils dégustent. » Au total, ce sont 5.000 distances entre saveurs qui ont pu être annotées lors de ces études, sachant que seuls cinq verres ont été goûtés par participant, afin de ne pas trop altérer leurs papilles gustatives. « Nous avons numérisé automatiquement les annotations des participants en prenant une photo de chaque feuille. » Un système automatique de computer vision a ensuite pu constituer les matrices représentant les similarités des vins grâce à une analyse spatiale.
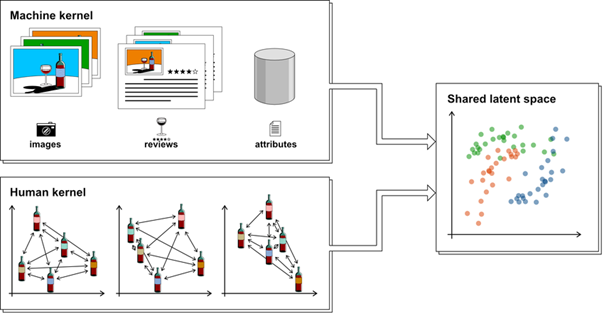
L’ensemble de données WineSensed est constitué d’une vaste collection d’images, de commentaires d’utilisateurs et de métadonnées sur les millésimes (en haut à gauche). Dans le cadre d’une vaste étude sur les utilisateurs, les chercheurs ont recueilli des annotations sur la saveur de plus de 100 vins en utilisant la méthode « Napping » [Pagès, 2005], qui consiste à demander aux participants de placer les vins sur une feuille de papier en fonction de leur similarité gustative perçue (en bas à gauche). Ils proposent ainsi un algorithme pour combiner ces modalités de données dans une représentation partagée (à droite). Ils ont constaté que l’utilisation des annotations gustatives comme modalité supplémentaire améliore les performances dans les tâches en aval.
Compilation des résultats
Pour obtenir une analyse fine des résultats et les croiser avec les avis de consommateurs, une approche d’apprentissage multimodale a été utilisée, combinant les images constituées grâce à l’étude, les informations présentes sur les bouteilles comme la région du vin, le pourcentage d’alcool et le cépage, ainsi que les avis sur Vivino. Pour connecter les textes et les images, un réseau de neurones baptisé Contrastive Language-Image Pre-training (CLIP) a été utilisé. Il s’agit d’une méthode d’apprentissage de la représentation d’images à partir de la supervision du langage naturel. Il a été combiné à un autre outil d’analyse des annotations réalisé par les personnes ayant participé à l’étude, afin d’apporter une cohérence entre les représentations 2D réalisées, et les informations sur les millésimes étudiés. « De cette manière nous avons pu représenter un « espace de saveurs » pour le vin, dans lequel la distance entre chaque vin représente sa similarité en termes de saveur. »
L’algorithme créé par l’équipe de chercheurs est capable de prédire plus précisément les préférences des consommateurs en matière de vin que lorsqu’il n’utilise que les types de données traditionnels sous forme d’images et de texte. Cela est possible uniquement en combinant les expériences sensorielles humaines avec les informations déjà existantes. Pour l’industrie agroalimentaire, ce type d’étude représente un fort potentiel dans la compréhension du goût, même s’il ne s’agit que des débuts. Cette approche peut être utilisée pour d’autres types de produits de grande consommation, comme la bière ou le café.
En savoir plus :
Aucun niveau de consommation d’alcool n’est sans danger pour notre santé (Organisation mondiale de la santé)
 Thoranna Bender
Thoranna Bender






