Résumé
“Ontologie” vous fait peut-être penser à Platon ou Heidegger, mais dans le sens (dérivé) où on l’applique en informatique, ce ne devrait pas être un mot si intimidant : nous utilisons en permanence des ontologies chaque fois que nous désignons un objet par un nom commun se référant à une catégorie connue (un écran, une table, un clavier). Cela va de soi pour nous, mais pour les systèmes de traitement de l’information, cette assignation d’un objet à une catégorie, définie elle-même par rapport à un environnement de référence (ici, le bureau !), est un enjeu majeur, parce qu’elle reste difficile à automatiser.
Les catégories conceptuelles des langues naturelles sont notoirement floues et dépendantes des cultures. Les ontologies informatiques doivent, à l’inverse, être définies formellement et assorties de règles et de contraintes qui les rendent utilisables par des machines.
Dans le monde désormais ouvert de l’Internet des objets, comme dans celui du Web, on doit identifier les objets individuels par rapport à des catégories pertinentes définies dans de telles ontologies. C’est ainsi qu’un programme pourra adresser un tel objet sans intervention humaine, pour le faire fonctionner automatiquement avec un autre, par exemple.
Si l’importance de ce référencement sémantique est maintenant reconnue, il se heurte en pratique à une difficulté majeure : l’absence d’un espéranto partagé.
Une telle “ontologie universelle” est bien sûr illusoire. Ce qui en prend la place est ce que les spécialistes de modélisation sémantique appellent, joliment, la “réconciliation” : dans un environnement ouvert et sans autorité centrale, des définitions issues d’ontologies différentes pourront, au final, être “réconciliées” pour en permettre l’intercompréhension. Sur le plan technique, ce n’est pas une utopie !
Article complet
Un nouveau syndrome de détresse psychologique serait apparu chez certains développeurs informatiques : la “sémaphobie” ? Il s’agirait de l’angoisse de devoir affronter des notions aussi intimidantes que celles d’ontologie ou de triangle sémiotique… notions qui fondent cette sémantique dont parlent bien naïvement nombre de journalistes ou… de managers 😉, et dont la compréhension effective pourrait nous imposer un cours de philosophie ou de sciences humaines. Comment diable retrouve-t-on, à partir de problèmes très concrets dans les technologies de l’information, des idées issues, en leur origine lointaine, de la philosophie pré-socratique ?
Car il s’agit bien fondamentalement des mêmes questions : qu’est-ce qui définit une chose physique ou une entité abstraite, en tant qu’objet unique, à l’existence contingente et transitoire, par rapport aux catégories supposées invariantes auxquelles elle est supposée appartenir ? Lequel a la primauté sur l’autre ? Ce ne sont pas là des spéculations intellectuelles gratuites, mais des problèmes très pratiques que se posent les “ingénieurs de la connaissance” dans tous les domaines des technologies de l’information. Nous montrerons pourquoi et comment.
De l’ontologie à la sémiotique
Dans les Sciences de l’Information, la notion d’ontologie est comprise dans une acception bien spécifique, mais qui est en fait dérivée directement de son origine dans la philosophie grecque (voir encadré ci-joint). Une ontologie vise à formaliser le sens des concepts utilisés dans un “univers de discours”, tel qu’il peut être décrit ou référé par un système d’information où ce niveau de “méta-connaissance” est en général implicite et informel, capturé par exemple par le choix d’identifiants en langage naturel tel qu’un développeur peut le faire. Le but de cette formalisation est de rendre le “sens” des informations véhiculées “compréhensible” par un programme tiers, et pas seulement par un utilisateur humain.
Pour tenter d’être concrets sur ce sujet bien abstrait, nous prendrons tous nos exemples dans le domaine de l’Internet des Objets. Les connaissances que nous cherchons à formaliser sont celles qui sont utilisées pour identifier, décrire et manipuler des objets physiques dans une Plateforme de gestion de l’Internet des Objets. La notion d’objet physique est prise au sens large, pouvant correspondre par exemple à des sous ensembles de l’espace, des regroupements d’objets, mais aussi des êtres vivants.
La formalisation de ces connaissances se base sur la notion de triangle sémiotique introduite par Charles Kay Ogden dans un livre au titre… ambitieux (“The meaning of meaning”, voir “En savoir plus” [1]) que nous avons outrageusement et non moins immodestement copié ici :-).
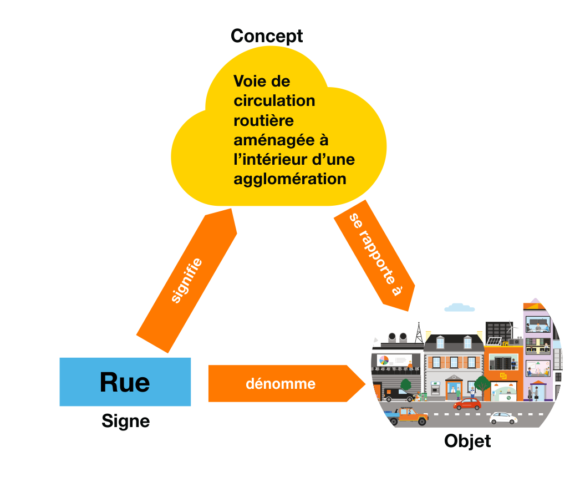
Triangle sémiotique
Afin de décrire sémantiquement un objet physique, nous devons le désigner sans ambiguïté en tant que membre d’une catégorie connue qui sera définie formellement dans une ontologie. Si le “signe” (ou “signifiant” dans le jargon de la sémiotique) représentant la catégorie conceptuelle (le signifié) à la quelle appartient l’objet a une relation analogique (de ressemblance) avec un objet (le référent) représentatif de cette catégorie, on parle de signe iconique, comme ceux qui sont utilisés dans les panneaux routiers, les pictogrammes, et certains idéogrammes. On s’intéresse beaucoup plus couramment à des signes de nature symbolique pour lesquels la relation entre signifiant et signifié est arbitraire et nécessite l’utilisation de conventions partagées (comme celles des langages naturels et des écritures alphabétiques) pour être comprise. Les systèmes symboliques sont fréquemment utilisés en cascade, le signifié d’un système inférieur (un caractère Unicode représenté par une séquence d’octets, par exemple) étant composé dans les signifiants d’un système supérieur (une variable ou un mot-clé d’un langage informatique).
Dans le cadre de l’ingénierie des connaissances telle qu’elle est préconisée aujourd’hui par le Web Sémantique, des symboles (à 2 niveaux) supposés universels, les URIs, (IRIs si elles utilisent Unicode plutôt qu’ASCII comme système symbolique de niveau inférieur) sont utilisés pour désigner et identifier des ressources qui peuvent être aussi bien des objets physiques individuels (on parle alors de ressources non-informationnelles) que des catégories d’objets dans un sens défini formellement et précisément par une ontologie d’un domaine spécifique dont relève ces objets, mais aussi les représentations numériques de ces objets, qui doivent être identifiées séparément pour les distinguer des objets physiques qu’elles représentent. Compte tenu de l’hypothèse du nom unique, plusieurs URIs peuvent faire référence à la même ressource tandis qu’une URI ne peut faire référence à plusieurs ressources. Cette propriété des URIs en fait l’un des mécanismes primordiaux pour créer les effets de réseaux qui font la force des Linked Data (Web des Données).
Le signe ainsi défini permet ensuite d’appareiller à tout objet une représentation conceptuelle qui le décrit. Cet ensemble de connaissances est formalisé à l’aide de langages dit sémantiques parmi lesquels figurent RDF, RDFS et OWL que nous décrivons dans la prochaine section. Par ailleurs, plusieurs propriétés intéressantes peuvent être recherchées pour cette représentation conceptuelle :
- La précision et l’exhaustivité visent à produire une représentation précise et explicite (et donc sans ambiguïtés).
- Le caractère formel (par l’utilisation de langages mathématiques dérivés des logiques du premier ordre) du modèle afin de rendre compréhensible par un agent logiciel la logique sous-jacente des entités composant la description sémantique. Cette propriété ouvre la voie aux raisonnements automatisés permettant à un agent logiciel de répondre à des questions simples à partir des connaissances contenues dans le modèle.
- Enfin, un modèle découlant d’une vision partagée d’experts garantit une bonne acceptation et une meilleure diffusion du modèle dans la communauté technique concernée.
Langages ontologiques
Mettant de côté la troisième propriété nécessitant un important effort d’élaboration pour atteindre le consensus au sein d’une communauté technique, le respect des deux premières propriétés est permis par l’utilisation du modèle le plus expressif du spectre des modèles sémantiques : l’ontologie. Cette dernière est décrite à l’aide de langages dits ontologiques parmi lesquels, trois recommandations du W3C généralement utilisées complémentairement :
- RDF permet d’exprimer des faits simples sous la forme de triplets <sujet, prédicat, objet> tels que “cet arbre est un végétal” ou “l’arbre du parc mesure 8m”. Dans les triplets précédents, les arbres sont les sujets, les verbes “être” et “mesurer” sont des prédicats et le concept végétal et la mesure de 8m sont des objets.
- RDFS introduit des axiomes structurant pour les bases de triplets. Ce langage permet notamment de définir des hiérarchies de classes et de propriétés et ajoute la notion de domaine (restreignant l’ensemble de concepts pouvant être sujet d’un prédicat donné) et de cible (image d’une fonction au sens des mathématiques pures, contraignant l’ensemble de concepts pouvant être objet d’un prédicat donné) pour les propriétés.
- Enfin, OWL est le langage ontologique le plus expressif. Il permet d’ajouter des contraintes sémantiques supplémentaires telles que des cardinalités et des propriétés de propriétés (symétrie, transitivité, etc.).
RDFS et OWL mettent à disposition des ontologistes une expressivité permettant de modéliser un éventail infini de domaines d’expertises, de la classification du vivant en biologie jusqu’à la modélisation de recettes de cuisine en passant par l’analyse de scènes de crimes. Par ailleurs, la sémantique de ces deux langages reposent sur la famille des logiques de description (et, par extension, sur les logiques du premier ordre) offrant ainsi le caractère formel recherché pour ouvrir la voie au raisonnement automatique.
Un exemple dans les “villes intelligentes”
Pour illustrer les notions précédentes, nous introduisons un cas d’application très concret des idées d’interopérabilité sémantique entre deux plateformes Internet des Objets dans une ville. Dans ce scénario, un gestionnaire de parking utilise une ontologie spécifique de son domaine dans la plateforme sur laquelle repose son système de gestion qui permet d’optimiser le déplacement des véhicules dans les différents étages en fonction des places occupées et des places libres. Cette ontologie lui permet également de modéliser les différents accès vers la sortie comme illustrée dans la figure suivante présentant un sous-ensemble du graphe de connaissances :
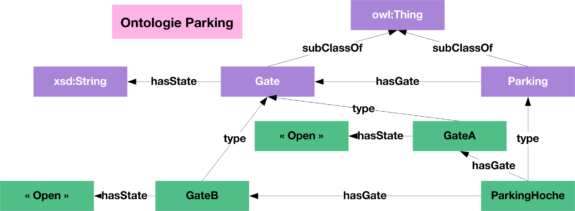
Ontologie de gestion du parking
L’ontologie modélise une vue structurelle du parking contenant des connaissances “métier” sur le bâtiment. Elle intègre une hiérarchie de classes permettant de représenter le parking (Parking) et ses portes d’accès (Gate). Une propriété d’objet (relation associative entre deux classes) est définie afin de représenter le fait qu’un parking possède une porte d’accès. Une propriété de données (relation liant un concept à un type primitif) est utilisée par ailleurs pour spécifier l’état d’une porte (ouverte ou fermée). Cette ontologie est ensuite instanciée. Deux portes d’accès ouvertes sont ainsi créées.
Vue fédérée sur la ville
Afin d’améliorer les conditions de circulation de la commune, le conseil municipal a fait appel à une entreprise spécialisée dans l’optimisation de trafic urbain. Cet opérateur utilise une plateforme qui utilise elle-même une ontologie permettant de modéliser de manière formelle et générique le réseau routier et les flux de véhicules circulant sur ce dernier. Cette ontologie, illustrée dans la figure ci-dessous, permet de représenter différents types de routes et leur état (congestionnée, trafic fluide, vide) ainsi que la notion de point d’entrée au réseau de circulation (RoadAccess), par exemple, les entrées en limite de la commune.
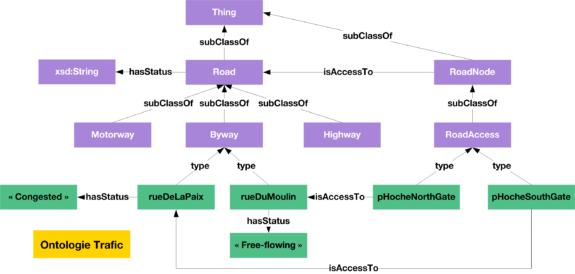
Ontologie de gestion de trafic
Pour limiter les risques d’embouteillage aux sorties du parking, la plateforme de l’opérateur de gestion du trafic doit inter-opérer avec celle du gestionnaire du parking. Le but est de permettre à l’algorithme de gestion de trafic d’intégrer les informations sur les flux sortants du parking, mais aussi de permettre au gestionnaire du parking de donner des consignes afin de diriger le trafic sortant vers les portes donnant sur des rues où la circulation est fluide.
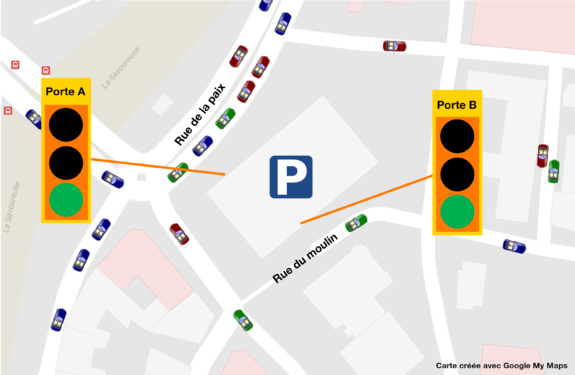
Parking et rues adjacentes
Lors de la mise en place de ce cas d’utilisation, l’opérateur est confronté à deux ontologies indépendantes dans lesquelles un même objet physique (à savoir, une porte d’accès au parking se trouve représenté par deux catégories différentes à savoir la classe Gate dans l’ontologie Parking et la classe RoadAccess dans l’ontologie Trafic). Pour mener à bien le cas d’utilisation, il est par conséquent nécessaire d’utiliser des techniques de médiation d’ontologies :
- Fusion d’ontologies : construire une nouvelle ontologie en unifiant les différentes ontologie dans une seule ontologie cohérente incluant tous les concepts.
- Alignement d’ontologies : établissement de règles de mapping entre les concepts définies collectivement par les différents concepts d’ontologie
- Intégration d’ontologies : construction d’une nouvelle ontologie intégrant les seuls concepts utiles d’autres ontologies.
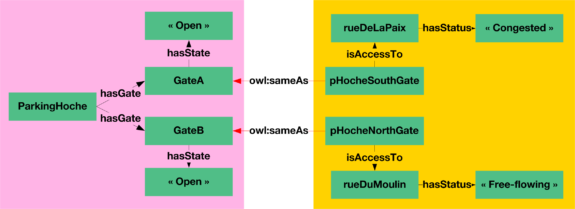
Médiation des ontologies Parking et Trafic
Une fois ce travail de médiation effectué, la vue unifiée et fédérée sur l’ensemble des connaissances liées au parking et au trafic urbain permet au gestionnaire de parking de proposer à ses clients des recommandations quant aux portes donnant sur des rues non congestionnées. Pour cela, un mécanisme de requête fédérée permet dans le langage de requêtes sémantique SPARQL de poser une question sur plusieurs graphes de connaissances.
SELECT ?porte WHERE
{
?porte rdf:type parking:Gate .
?porte parking:hasState « Open » .
?porte traffic:isAccessTo ?route .
?route traffic:hasStatus ?etat.
FILTER(?etat IN (« Free-flowing », »Empty »))
}
La requête proposée ci-dessous (simplifiée pour les besoins de l’article) permet ainsi d’obtenir les portes actuellement ouverte et donnant sur une route sur laquelle le trafic est faible ou nulle. Dans notre exemple, l’instance représentant la porte B du parking Hoche est retournée.
Conclusion
Plus de 15 ans après l’article fondateur de Tim Berners-Lee, le référencement sémantique des contenus du Web a enfin commencé à décoller par l’utilisation d’un modeste ensemble de “vocabulaires”, qui ne prétendent pas même au titre d’ontologies, sous l’égide du groupe schema.org mené par (entre autres) Google et Microsoft. Cette approche pragmatique a eu le mérite de surmonter la sémaphobie des webmasters, là où l’autorité de Sir Tim himself n’avait pas réussi! Pour autant cette approche a ses limites dans la mesure où les vocabulaires de schema.org sont limités et définissent en priorité des entités virtuelles ou informationnelles qui restent à l’intérieur du web d’origine en tant que système de documents. Dans le (vaste) domaine de l’Internet des objets que nous avons pris comme exemple ici, il est par contre indispensable, pour définir des objets physiques du monde réel, de prendre en compte les multiples modélisations (ontologiques ou de niveau légèrement inférieur) définies par une multitude de communautés de spécialistes métier dans leurs domaines respectifs. C’est une tâche ambitieuse et de longue haleine pour laquelle la modélisation “top-down” par modélisation ontologique devra se compléter avec l’approche plus bottom-up (celle des linked data) présentée dans un article précédent pour permettre de croiser et fédérer les informations de systèmes différents dont les ontologies n’offrent chacune qu’une vue très partielle d’un monde partagé. Dans une interprétation possible de la parabole des aveugles et de l’éléphant, les différents points de vue partiels (ceux des opérateurs de plateformes spécialisées dans notre exemple), doivent être pris en compte conjointement et sont en fait indispensables à leur niveau et dans leur domaine. Comme l’idée d’une plateforme unique avec son ontologie universelle est illusoire dans le domaine de l’Internet des Objets (domaine beaucoup plus fragmenté et hétérogène que celui des réseaux sociaux…), on doit aussi renoncer à l’idée qu’il y aurait un point de vue supérieur unique (l’équivalent de celui du voyant dans la parabole…) subsumant les autres. Nous laissons au lecteur le soin d’en dériver, à son gré, une interprétation philosophique ?
Aux sources de l’ontologie :
Rien de plus désespérément fondamental, ou de plus chimérique, apparemment, que l’ontologie (étude de ce qui est, étymologiquement). Certaines des questions originelles qui ont parcouru toute l’histoire de la philosophie relèvent, au sens propre, de l’ontologie. Le clivage entre matérialisme et idéalisme correspond ainsi à deux ontologies distinctes donnant respectivement la primauté à la nature matérielle (chez les philosophes pré-socratiques) ou idéelle (chez Platon) de la substance du monde. Le matérialisme a parcouru un long chemin depuis les ontologies pré-socratiques comme celle des quatre éléments fondamentaux (l’eau, la terre, l’air et le feu) d’Empedocle. On parlerait aujourd’hui plutôt de physicalisme, qui peut aller jusqu’à un réductionnisme que l’on trouve un peu caricaturalement chez certains physiciens, pour qui la biologie, mais aussi, partant, toutes les sciences humaines, ne seraient que des chapitres de la physique… Les ontologies dualistes (chez Descartes, par exemple) tentent au contraire de donner un statut équivalent à la matière et à l’idée, et il est assez curieux que les Sciences de l’Information, dans la manière dont elles peuvent jouer, à l’opposé du réductionnisme physicaliste, le rôle de « meta-science » à la fois pour la physique et la biologie, renouent à leur manière avec ce dualisme.
Références :
[1] Ogden, C. K., Richards, I. A., Ranulf, S., & Cassirer, E. (1923). The Meaning of Meaning. A Study of the Influence of Language upon Thought and of the Science of Symbolism.
[2] Gruber, T., 1993. A translation approach to portable ontology specifications. Knowledge acquisition.
[3] Cyganiak, R., Wood, D. & Lanthaler, M., 2014. RDF 1.1 Concepts and Abstract Syntax.
[4] Brickley, D. & Guha, R.V., 2000. Resource Description Framework (RDF) Schema Specification 1.0.
[5] McGuiness, D. & Van Harmelen, F., 2004. OWL Web Ontology Language.
 Yoan Chabot
Yoan Chabot