


Chronologie du développement des agents conversationnels
Depuis la première apparition d’ELIZA[1] en 1966, plusieurs tentatives de création d’agents conversationnels ont été proposées par des universitaires et des industriels (Google Home, Alexa par Amazon, Cortana par Microsoft, Siri par Apple, bots de service client sur de nombreux sites Internet, etc.). Bien que ces systèmes puissent maintenant automatiser avec succès de nombreuses tâches, qui n’a pas connu la frustration de parler à l’un de ces systèmes automatiques ? En général, ils ont du mal à comprendre et sont incapables de communiquer à la manière d’un être humain : ils ne saisissent pas correctement les malentendus, ils ne s’adaptent pas à des situations inédites, ils ne fournissent pas de réponses pertinentes et riches, etc. Incontestablement, l’une des raisons du succès de ChatGPT est qu’il repousse clairement ces limites encore plus loin. Mais les surmonte-t-il vraiment ?
Cet article traite de la complexité de la conversation et étudie ChatGPT à travers les phénomènes linguistiques, la compréhension et la planification.
Un chatbot aux 60 ans d’existence
La conversation est un acte si naturel chez les humains que pendant des décennies, les concepteurs en ont négligé sa complexité. Les premiers chatbots étaient basés sur des règles conçues pour analyser le langage et déclencher des réponses prédéfinies lorsque les intentions des utilisateurs étaient reconnues (par exemple, prendre un rendez-vous, décrire un problème technique, accepter une offre, demander plus d’informations, etc.) Par conséquent, les concepteurs devaient planifier le dialogue à l’avance en considérant toutes les intentions possibles de tout type d’utilisateur et toutes les façons possibles d’exprimer ces intentions. Bien que le manque de flexibilité de ces approches fondées sur des règles ait été un obstacle pendant des décennies et l’est encore aujourd’hui, les progrès en matière de deep learning ont permis l’émergence de solutions aux plus grandes capacités d’adaptation.
De manière générale, les systèmes de dialogue traditionnels sont construits autour de trois exigences principales dans un modèle en cascade. Tout d’abord, le système doit comprendre chaque message de l’intervenant et être capable d’intégrer les nouvelles informations dans une vue d’ensemble de la conversation. Cette étape de compréhension peut être effectuée à partir de données textuelles (lorsqu’un utilisateur discute avec un bot) ou de déclarations orales (centre d’appels). Puis, le système analyse l’état actuel de la conversation afin de planifier ce qu’il faut faire ensuite, c’est-à-dire pour décider de l’action à exécuter : poser une question pour mieux comprendre les besoins de l’utilisateur, rechercher des informations dans une base de données ou même interagir avec l’environnement (en lançant un redémarrage à distance du décodeur de l’utilisateur par exemple). Enfin, une fois cette décision prise, le système doit pouvoir en rendre compte à l’utilisateur en générant un message écrit ou oral au langage naturel. Cette façon de structurer les systèmes de dialogue se retrouve dans de nombreux cadres dédiés (comme Rasa, Dialogflow, Smartly, etc.), où chaque étape est mise en œuvre à l’aide de modèles basés sur des règles ou des statistiques[2].
Apprécié principalement des chercheurs, l’apprentissage par le renforcement permet également de créer un dialogue artificiel[3]. Cette approche est explorée depuis la fin des années 90. Le dialogue peut être vu comme un jeu de société dans lequel les orateurs sont des joueurs et le plateau représente l’état de la conversation. Cet état évolue constamment, et les intervenants doivent réagir et répondre de manière appropriée. Cette approche repose sur l’idée que les stratégies menant à la “victoire” (c’est-à-dire une conversation réussie) apportent une récompense au modèle, tandis que les stratégies menant à une “défaite” se traduisent par une pénalité, “pilotant” ainsi le modèle de manière efficace. Aussi attrayante qu’elle soit, l’adaptation de cette approche dans de véritables environnements industriels s’est révélée compliquée. En effet, celle-ci a besoin de beaucoup d’interactions pour trouver la stratégie optimale et le signal de récompense reste rare puisque les utilisateurs ne sont pas toujours disposés à remplir des questionnaires pour évaluer les réponses. Après le succès d’AlphaGo en 2016, le concept d’apprentissage par le renforcement a suscité un nouvel intérêt dans les scénarios de recherche.
Une approche récente consiste à s’appuyer sur un modèle neural unique, dont l’objectif principal est de produire des réponses pertinentes aux déclarations des utilisateurs. On parle alors d’un modèle de bout en bout[4] (c’est-à-dire sans étapes intermédiaires comme l’approche traditionnelle en cascade : comprendre-planifier-générer). Deux approches de bout en bout ont vu le jour : l’approche basée sur la récupération et l’approche générative. Dans la première, les systèmes de dialogue peuvent classer les réponses des candidats à une question, de la même manière que Google classe les pages Web. Dans la deuxième, comme GPT-3 ou Bloom, la réponse est générée grâce à des modèles de langue, qui prédisent systématiquement le mot suivant. En général, après avoir reçu les commentaires des utilisateurs, il est capable de générer la réponse. Ces solutions neurales avaient pour objectif de résoudre le problème de la conversation. Bien que très prometteuses, elles ont rapidement atteint leurs limites. Les réponses générées pouvaient contenir des incohérences, des inventions, des déformations et des omissions. Le grand succès de ChatGPT est qu’il combine à la fois la génération et le classement de réponse[5] pendant l’entraînement. En outre, il utilise l’apprentissage par le renforcement de manière subtile afin d’apprendre à classer les réponses en utilisant un modèle de récompense formé par des réponses à des instructions précédemment classées par les humains.
Les approches de bout en bout ont considérablement bénéficié de l’architecture neurale Transformer[6], proposée en 2017 par Google. Outre leur performance, l’un de leurs principaux avantages est qu’elles peuvent être utilisées à la fois pour comprendre et générer des textes. Elles utilisent un mécanisme d’attention qui permet au modèle d’apprendre d’une manière ou d’une autre la structure du langage. ChatGPT fait partie de ces modèles, avec quelques caractéristiques spécifiques qui le distinguent des autres modèles, notamment sa stratégie d’apprentissage basée sur les instructions et les exemples de dialogue soigneusement sélectionnés par l’être humain[7], sans être fondamentalement différent.
Le dialogue représente bien plus que du texte
Bien que les règles de grammaire puissent expliquer le langage naturel, le langage reste flexible. Cette flexibilité nous permet de maximiser l’efficacité de nos déclarations, de trouver un bon compromis entre clarté et concision, en particulier dans les conversations. En général, nous évitons les répétitions lorsqu’une option plus courte est tout aussi valide, sans être ambiguë. En effet, une conversation fluide évite naturellement les répétitions. Par exemple, dans la phrase « j’ai laissé ma glace dehors et elle a fondu », le pronom « elle » évite la répétition de « glace » sans créer d’ambiguïté. Plus tard dans la conversation, vous pourrez choisir de dire : « le dessert« . De plus, si vous voulez préciser que vous l’aimez, vous pouvez dire « j’aime son parfum ». Prenons un autre exemple : « Sarah, Julie et Nadia étaient dehors. Julie est rentrée, suivie de Nadia. ». Ici, la répétition de « rentrée » est évitée car, dans ce contexte, la formulation abrégée : « suivie de Nadia » indique clairement que Nadia est également rentrée. Bien que ces phénomènes linguistiques soient présents dans les documents, les conversations en contiennent beaucoup plus.
Bien que la gestion de ces phénomènes ait longtemps été un défi pour les modèles d’IA, l’arrivée des Transformer a largement résolu le problème grâce à leur architecture qui lie intrinsèquement les mots ou les passages d’un texte (ce mécanisme est appelé auto-attention dans la littérature dédiée), et permet ainsi de trouver l’information manquante. En ce sens, ChatGPT s’en sort relativement bien avec ces phénomènes (voir exemples 1 et 2), bien qu’il n’apporte rien de nouveau par rapport à ses prédécesseurs et qu’il peut encore faire des erreurs (exemple 3).

Exemple n° 1 : Bonne résolution du pronom : dans ce cas, le pronom « elle » évite la répétition de « glace ».

Exemple n° 2 : Bonne résolution d’une déclaration abrégée.
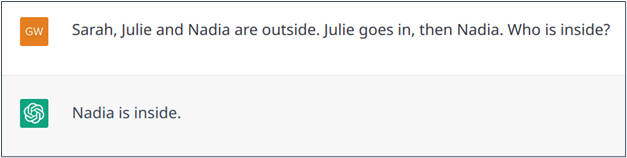
Exemple n° 3 : Échec de la résolution d’une déclaration abrégée.
Parfois, il peut y avoir une ambiguïté. Par exemple, si on dit, « J’ai laissé ma glace sur la table et elle a fondu« . Il est évident que « elle » ne peut se référer qu’à « glace » parce qu’une table ne peut pas fondre. De même, dans la déclaration « J’ai laissé ma glace sur la table et elle s’est effondrée« , il est beaucoup plus probable que « elle » se réfère à la table qu’à la glace. Là encore, de manière générale, ChatGPT gère plutôt bien ces ambiguïtés (comme le font les modèles de Transformer), mais peut aussi se tromper (exemples 4 et 5).
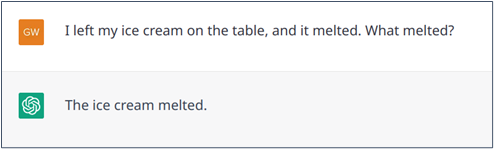
Exemple n° 4 : Bonne résolution d’une déclaration ambiguë dans laquelle la connaissance du bon sens peut être utile.
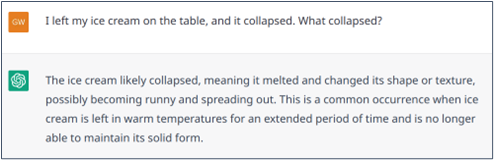
Exemple n° 5 : Échec de la résolution d’une déclaration ambiguë dans laquelle la connaissance du bon sens peut être utile.
Dans certains cas, l’ambiguïté ne peut pas être résolue implicitement. Par exemple, dans l’énoncé « Julie et Nadia sont dehors. Puis, elle rentre« , on ne sait pas clairement qui est rentré. Dans une telle situation, un être humain clarifierait ses propos avant de répondre. À l’inverse, comme le montrent les exemples 6.a et 6.b, ChatGPT peut avoir tendance à chercher une réponse, en supposant que si on lui pose une question, il doit y avoir une réponse. L’exemple 6.c montre un cas où ChatGPT indique qu’il ne connaît pas la réponse, mais son explication révèle que le modèle a émis une hypothèse précoce injustifiée (lorsqu’il affirme que « elle » se réfère à « Julie »).

Exemple n° 6.a : Échec de la résolution d’une ambiguïté.

Exemple n° 6.b : Échec de la résolution d’une ambiguïté.
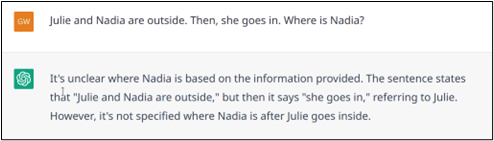
Exemple n° 6.c : Échec de la résolution d’une ambiguïté.
Par rapport aux textes écrits classiques, les interactions spontanées (dialogues parlés ou discussions) sont également très susceptibles d’inclure des déclarations « bruyantes » telles que des fautes d’orthographe, des hésitations ou des disfluences (par exemple, lorsqu’un orateur s’interrompt pour réfléchir au reste de sa phrase ou pour corriger ce qu’il vient de dire). Comme l’entraînement des Transformer inclut ce type de textes bruyants, ils sont plutôt efficaces pour traiter ces phénomènes (exemples 7 et 8).

Exemple n° 7 : La faute d’orthographe « glasse » au lieu de « glace » aurait pu ajouter de l’ambiguïté au modèle, mais celui-ci le gère correctement.
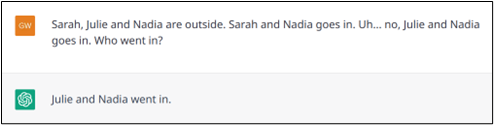
Exemple n° 8 : Une autre résolution réussie d’une hésitation et d’une correction du contenu.
Enfin, les dialogues dans la vie réelle peuvent être multipartites. Cette situation rend les phénomènes susmentionnés encore plus complexes parce qu’il est nécessaire de déterminer à quel message précédent un nouveau message fait écho et à qui il est adressé. Même si ce n’est pas pour cela que ChatGPT a été conçu, il pourrait probablement relier les phrases des différentes personnes participant à un dialogue. Pour ce faire, comme illustré dans l’exemple 9, le modèle doit être informé de ce paramètre de dialogue multipartite. Le modèle semble ainsi comprendre la structure du dialogue (Sarah répond à Julie et non à Nadia, bien que l’ordre de la conversation suggère qu’elle répond au dernier message, c’est-à-dire celui de Nadia).
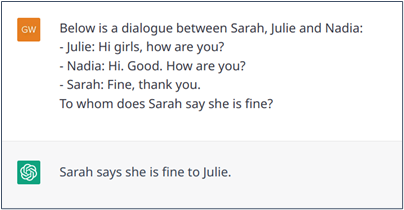
Exemple n° 9 : Dialogue imbriqué dans lequel ChatGPT comprend la structure du dialogue.
Compréhension mutuelle
Puisque le dialogue est un acte social, il est important de vérifier que la conversation se passe bien. Pendant la conversation, les intervenants vérifient toujours qu’ils se comprennent. Ils échangent des réactions informelles qui montrent, par exemple, qu’ils comprennent, qu’ils sont d’accord ou qu’ils sont surpris. Par conséquent, un orateur qui reçoit de tels commentaires sait s’il doit reformuler son discours ou le continuer. La compréhension[8] consiste à s’assurer que les participants à une conversation parlent des mêmes concepts, s’entendent sur leur compréhension mutuelle par rapport aux connaissances générales, au bon sens ou à la conversation elle-même.
Il est particulièrement important de lever toute ambiguïté en faisant preuve de bon sens et de demander des éclaircissements au besoin dans les conversations qui se concentrent sur la résolution de problèmes concrets et/ou complexes. L’exemple 10 fournit une retranscription d’une conversation entre un client Orange et un assistant technique.
| > ASSISTANT : il faut appuyer plusieurs fois sur les touches jusqu’à ce que vous voyiez les lettres. C’est le même principe que les anciens téléphones portables
> CLIENT : je vois les lettres, ce sont les chiffres que je ne vois pas. Par ailleurs, je n’arrive pas à passer d’une lettre à l’autre avec les flèches de la télécommande. > ASSISTANT : vous ne voyez les caractères que vous tapez, vous devez avoir des étoiles ou des points ? > CLIENT : lorsque je tape par exemple la touche 9 je vois apparaitre wxyz un court instant puis les lettres se transforment en un point. Si j’essaye avec les flèches de passer du w au x, j’ai immédiatement un point qui apparait sans savoir s’il s’agit d’ w ou d’un x. > ASSISTANT : quel modèle de télécommande avez-vous ? le tour est arrondi ou rectangulaire ? > CLIENT : rectangulaire fourni avec la livebox > ASSISTANT : vous avez changé les piles ? ou plutôt avec le décodeur uhd 86 > CLIENT : non, mais je peux essayer > ASSISTANT : oui SVP > CLIENT : j’ai mis des piles neuves mais cela ne change rien. je précise que ma télécommande fonctionne bien par ailleurs > ASSISTANT : il ne faut pas vous servir des flèches pour sélectionner la bonne lettre, vous tapez toujours sur la même touche. par exemple la touche 9 : vous avez wxyz qui apparait, pour sélectionner vous tapez toujours sur la touche 9 > CLIENT : OK tout fonctionne merci beaucoup. |
Exemple n° 10 : Transcription d’une conversation entre un client Orange et un assistant technique. Notez que, dans les discussions, il y a beaucoup de fautes de frappe.
Cet exemple montre à quel point il peut être crucial que les deux interlocuteurs parviennent à une compréhension commune de la situation. Cette compréhension mutuelle est obtenue par plusieurs moyens :
- Questions et clarifications. Ils demandent les informations dont ils ont besoin et fournissent les informations dont ils disposent. Pour ce faire, ils devinent ce que leurs interlocuteurs savent déjà (en le leur demandant) et ce qu’ils ne savent pas encore (pour leur fournir des informations utiles)
- Connaissances de base. Ils commencent la conversation avec une connaissance riche du monde, qu’ils peuvent mettre à jour au cours de la conversation avec des faits spécifiques concernant la situation. Cette connaissance comprend à la fois des informations spécialisées (par exemple, les caractéristiques techniques de la Livebox) et des connaissances générales (l’alphabet, la façon dont les gens écrivaient sur leurs anciens téléphones portables, qu’est-ce qu’une batterie, etc.)
- Du bon sens. Ils font preuve de bon sens pour déduire des informations de ce qui a été dit explicitement. Sur ces trois aspects, ChatGPT surpasse les systèmes de dialogues traditionnels, même s’il est encore loin d’être parfait.
Premièrement, en ce qui concerne les questions et les clarifications, les systèmes de dialogue traditionnels peuvent uniquement donner et recevoir des informations prédéfinies (et donc très limitées). Au contraire, ChatGPT peut donner et recevoir des informations efficacement pendant la conversation. Toutefois, bien qu’il soit difficile d’évaluer toutes les capacités de ChatGPT, il ne semble pas être en mesure de comprendre les besoins d’information de son interlocuteur si ceux-ci n’ont pas été explicitement énoncés dans l’instruction. Il ne semble pas capable non plus d’identifier son propre manque d’information (et donc de poser une question) dans la plupart des cas. Enfin, la saisie de texte de ChatGPT offre une capacité limitée. Par conséquent, si un dialogue se poursuit trop longtemps, ChatGPT oubliera ce qui a été dit au début.
Deuxièmement, en ce qui concerne les connaissances de base, les systèmes de dialogue existants sont typiquement conçus pour gérer les connaissances spécialisées de certaines bases de données externes mais ils possèdent peu de connaissances générales. Les grands modèles de langue comme ChatGPT ont “mémorisé” beaucoup de connaissances de leurs données d’entraînement (qui incluent, par exemple, Wikipédia). Toutefois, on ne sait pas encore clairement comment le doter efficacement de connaissances plus spécialisées provenant de ressources externes. Il s’agit en effet d’un problème de recherche ouverte, mais des solutions telles que les plugins ChatGPT sont en train d’émerger rapidement. En ce qui concerne les connaissances spécialisées, la même limitation pourrait s’appliquer aux systèmes de dialogue traditionnels et aux grands modèles de langue. Toutes les connaissances utiles ne se trouvent pas forcément dans les sources existantes. Par exemple, il est rare de stocker des informations telles que la forme précise (« rectangulaire ou arrondie ») d’une télécommande dans une base de données. Stocker un maximum d’informations sur tout ce dont un système automatisé pourrait parler n’est pas une chose aisée, et ChatGPT ne résout pas vraiment ce problème. En outre, il est important de comprendre que ChatGPT génère du texte sans « se soucier » de la vérité. Celui-ci se base sur un modèle de langue dont la fonction principale est de prédire le mot le plus susceptible de continuer le texte qui lui est fourni. Par conséquent, bien qu’il génère souvent de vraies affirmations, il peut aussi produire des déclarations absurdes, voire des informations erronées, mais convaincantes (voir exemples 11, 12 et 13). Enfin, le monde est en constante évolution. De nouveaux événements se produisent (la guerre, la covid, la coupe du monde de football, etc.), de nouvelles choses sont créées (des films, des vaccins, de nouveaux modèles Livebox), les cultures changent et de nouveaux mots d’argot apparaissent. Un problème majeur de recherche consiste à savoir comment maintenir le modèle à jour, ce qui pourrait nécessiter de le former de manière régulière.

Exemple n° 11 : ChatGPT a tendance à se fier aux informations fournies par l’utilisateur, même si cela perturbe complètement les connaissances de base (Source : https://twitter.com/pretendsmarts/status/1610544851711320064/photo/2).
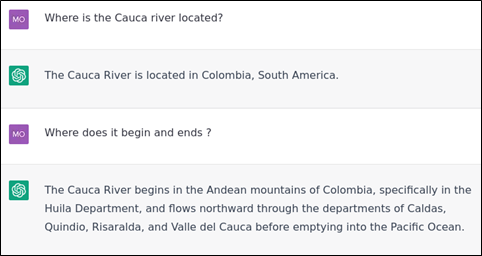
Exemple n° 12 : C’est un fait : ChatGPT manque encore de connaissances sur le monde réel. ChatGPT invente des informations, car la rivière Cauca se termine dans le fleuve Magdalena qui se jette dans la mer des Caraïbes et non dans l’océan Pacifique. Il y a aussi des omissions importantes : les départements ne sont pas mentionnés dans le bon ordre vers le nord et il en manque certains.
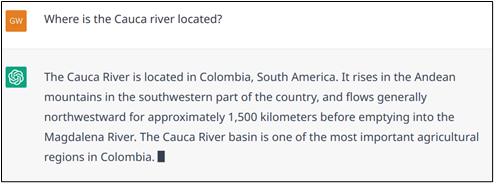
Exemple n° 13 : Les réponses de ChatGPT sont stochastiques, il répond différemment à la même question posée dans la figure 1. Les bots fiables doivent fournir la même réponse bien qu’il soit recommandé de paraphraser pour diversifier les réponses. Dans cet exemple, ChatGPT invente la longueur de la rivière, la bonne réponse est d’environ 1 350 km.
Troisièmement, en ce qui concerne le bon sens, bien que ChatGPT puisse fournir des réponses excellentes et rationnelles, de nombreuses situations nous permettent de constater que son bon sens n’est pas aussi développé que celui de la plupart des êtres humains (voir exemple 14).
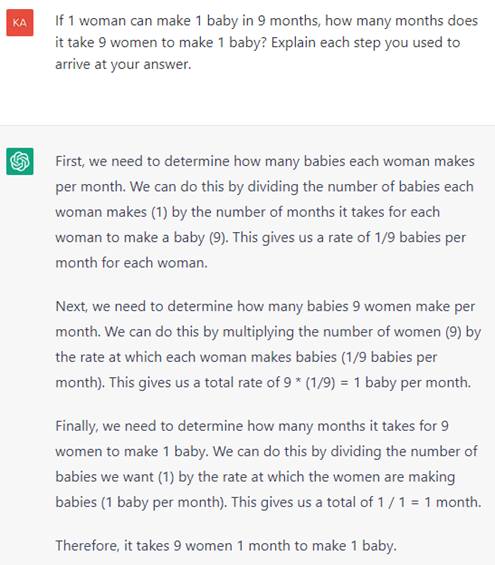
Exemple n° 14 : ChatGPT n’a pas connaissance du monde réel ou bien il n’a aucun bon sens. Il est tout simplement impossible de faire un bébé en un mois. Cet exemple est extrait du site Internet https://github.com/giuven95/chatgpt-failures. Le fait que ChatGPT soit trop confiant en fournissant de mauvaises réponses pourrait être trompeur et porter préjudice.
Prendre des décisions à long terme
Derrière toute conversation humaine se trouve un but inhérent, qu’il soit conscient ou non. Ensuite, la conversation peut être vue comme la réalisation d’un plan pour atteindre cet objectif. En tant qu’orateur, vous pouvez, par exemple, influencer votre auditeur ou collaborer avec lui. Réciproquement, en fonction de ses réponses, vous ajustez constamment votre plan. Cet ajustement dynamique est un concept clé du dialogue, appelé planification. Comme indiqué précédemment dans l’article, la planification peut être comparée au mécanisme de décision des personnes jouant à un jeu de société et qui ont besoin de décider de la prochaine action à mener en simulant dans leur esprit la meilleure façon d’atteindre leur but.
La planification est conditionnée par différents aspects. Tout d’abord, elle repose fortement sur les obligations du discours social. Par exemple, après avoir posé une question, l’orateur attend une réponse. Après avoir fait une offre, l’orateur attend une acceptation ou un rejet. Certaines de ces obligations impliquent une communication, d’autres non. Par exemple, après avoir ordonné à quelqu’un de faire quelque chose, l’orateur attend de l’auditeur qu’il exécute cette action. Cela donne une interaction plus cohérente et plus efficace. Cependant, les situations de conversation quotidiennes sont si diverses qu’un plan capable de s’adapter à l’environnement ne peut tout simplement pas faire l’objet d’un codage en dur. La planification est également très liée à la notion de compréhension : pour savoir quelle réponse donner dans une conversation, il faut comprendre la situation et maîtriser les connaissances inhérentes. Par exemple, pour aider un utilisateur à réserver un restaurant (un cas d’usage fréquent dans le domaine), un bot doit savoir que la date de départ et la destination sont des informations essentielles. Enfin, les objectifs de conversation peuvent être très divers et la façon de réagir à une conversation dépend de leur nature. Par exemple, l’objectif peut être de répondre à une question de connaissances générales, d’aider à résoudre une tâche ou de discuter de la météo. L’être humain peut aussi déduire ou être informé de l’objectif de son interlocuteur et planifier son discours en conséquence.
Les systèmes de dialogue traditionnels (déployés dans de nombreuses applications) sont souvent basés sur des cas d’usage fixes et limités. Ainsi, un système est généralement conçu pour gérer un seul type d’objectif (par exemple, la résolution de tâches). Finalement, l’illusion d’un agent plus généralisé peut être donnée par un mécanisme d’orchestration qui dirige le système vers des sous-modules spécialisés. Par exemple, si l’on demande à l’agent de raconter une blague, cet objectif sera repéré et transmis à un générateur de blagues (basé sur une base de données de blagues ou un générateur d’IA). De même, en ce qui concerne les connaissances et les concepts sous-jacents, les actions sont souvent données par des règles antérieures (par exemple, « si l’utilisateur a donné une date, alors le bot doit demander l’heure »…). Plutôt que d’utiliser des règles statiques, l’analogie de la planification avec le jeu a conduit à l’émergence de modèles plus flexibles par le biais de techniques de machine learning, et dans ce cas l’apprentissage par renforcement. Toutefois, dans le cas d’une utilisation sans restriction, l’un des principaux inconvénients de l’adaptation de l’apprentissage par le renforcement au dialogue est la quantité limitée d’actions possibles à un état donné (à un moment donné de la conversation). Devant tant d’actions et d’états possibles, le choix de l’action optimale peut se révéler difficile.
Aussi convaincant que ChatGPT puisse paraître, il s’agit simplement d’un modèle de langue. Il n’inclut pas explicitement de notion de planification, et l’algorithme pour générer ses réponses n’inclut pas de mécanisme pour explorer les possibilités futures d’une discussion en cours. Dans la pratique, ces réponses sont le résultat d’un compromis entre deux aspects. D’une part, elles sont basées sur l’historique de la conversation et les observations au cours de l’entraînement du modèle, dans le sens où ces réponses reflètent le choix le plus souvent observé dans des situations que le modèle assimile à la situation actuelle. D’autre part, ChatGPT a appris de telle manière que la réponse renvoyée est celle qui maximise le critère d’acceptabilité. OpenAI souligne donc qu’une bonne réponse doit être utile, honnête et inoffensive. La modélisation de ce critère d’acceptabilité implique de nombreuses annotations humaines dans un grand nombre de situations. Ainsi, si vous demandez des informations à ChatGPT, il vous répond. Et si vous bavardez avec lui, il joue le jeu. Ces types d’objectifs exigent peu ou pas de planification et sont généralement satisfaisants (avec quelques inconvénients, comme les problèmes de compréhension mentionnés ci-dessus ou le fait que le critère d’acceptabilité pousse le modèle à ne pas prendre d’initiatives dans une discussion).
La notion de planification est particulièrement présente lorsque l’objectif de l’utilisateur est de résoudre une tâche (par exemple, réserver un restaurant, résoudre un problème logique…). Dans ce cas, ChatGPT déduit l’intention de l’utilisateur. Comme mentionné précédemment, si la situation a été vue pendant l’entraînement, le modèle sait comment résoudre la tâche (l’exemple 15 montre comment le modèle répond à une tâche de réservation de restaurant : le modèle sait ce qu’il faut demander, dans quel ordre pour l’anglais et le français. Toutefois, en espagnol, il n’a pas été en mesure de poser des questions dans le bon ordre, il ne faisait que répertorier toutes les questions à la fois.) Étant donné l’énorme quantité de données d’entraînement (y compris des sites Internet comme WikiHow ou des forums d’aide, des ensembles de données publics, etc.), le modèle connaît un grand nombre de tâches et d’ensembles de données (l’exemple 16 montre comment le modèle répond à une tâche technique).
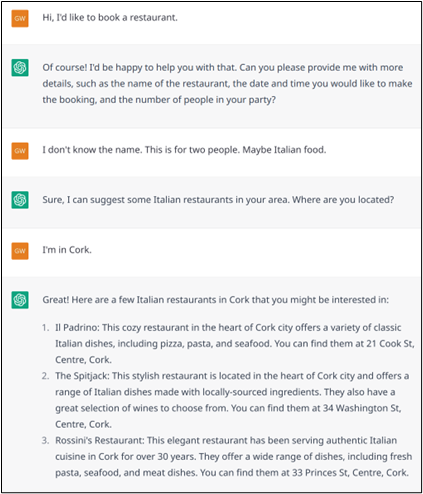
Exemple n° 15 : Réserver un restaurant est une tâche très classique. ChatGPT ne rencontre aucun problème pour la traiter correctement.

Exemple n° 16.a : Exemple d’une tâche moins courante que le modèle traite ensuite d’une manière unique en fournissant des solutions possibles.
Comme mentionné dans la section précédente, l’une des faiblesses du modèle est qu’il n’est pas conscient qu’il ne le sait pas. Cela le conduit à improviser plutôt qu’à rechercher de nouvelles connaissances. Ainsi, l’exemple 16.b (suite de l’exemple 16.a) évoque un outil que le modèle ne connaît pas (parce que celui-ci n’existe pas, mais cela pourrait être le cas) et le modèle invente ainsi un mode d’utilisation qui est certainement plausible mais totalement faux. Le modèle ne dispose pas des connaissances procédurales qui lui permettraient d’expliquer comment l’utiliser. La solution est de transmettre ces connaissances avant le début du dialogue. Ainsi, chaque dialogue comporterait un premier tour caché, grâce aux explications textuelles fournies par les concepteurs du dialogue. Par exemple, le fonctionnement de l’outil MySender dans l’exemple 16.b (et bien d’autres outils) peut être expliqué au modèle, afin qu’il puisse ensuite aider un utilisateur.

Exemple n° 16.b : Situation dans laquelle le modèle ne possède pas les connaissances requises, mais tente tout de même de résoudre la situation.
Cependant, encore une fois, il est important de garder à l’esprit que ChatGPT n’effectue pas de planification. Par exemple, s’il doit faire face à un problème logique où l’avenir doit être simulé pour trouver la bonne action à exécuter, le modèle ne réussira pas (ou seulement par hasard, ou grâce à des modèles acquis pendant l’entraînement). L’exemple 17 (a, b, c et d) illustre cela avec un problème simple. Pour résoudre ce problème, les exemples démontrent que le modèle enfreint les règles (voir exemples 17.b et 17.d), rendant le dialogue assez grotesque lorsque le modèle est invité à résoudre le problème pas à pas (17.d).

Exemple n° 17.a : Résolution illégale d’un problème logique dont l’environnement, les actions possibles et les objectifs sont définis dans un langage naturel.

Exemple n° 17.b : Résolution réussie d’un problème logique dont l’environnement, les actions possibles et les objectifs sont définis avec plus de formalité.
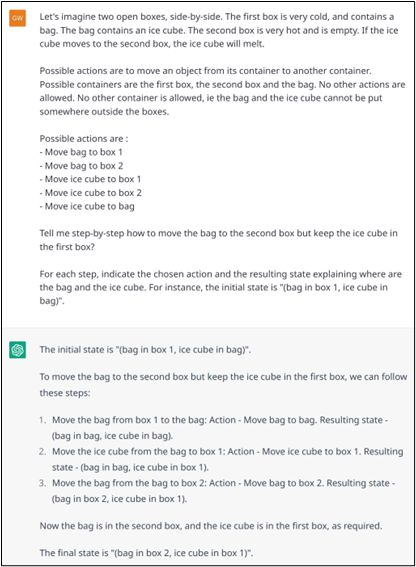
Exemple n° 17.c : Mauvaise résolution d’un problème logique dont l’environnement, les actions possibles et les objectifs sont définis avec plus de formalité.

|


Exemple n° 17.d : Résolution interactive (échec) d’un problème logique.
Quelles sont les orientations futures ?
Comme le suggère la couverture médiatique sans précédent, ChatGPT représente un pas important dans le développement d’une intelligence artificielle capable de converser avec les êtres humains. À certains égards, le modèle va au-delà des performances humaines. En effet, qui peut se vanter de posséder un si large éventail de connaissances et de fournir des réponses à n’importe quelle question en quelques secondes ? Cependant, cet article montre les limites de ChatGPT : celui-ci donne l’illusion d’être intelligent tout en fournissant des informations imprécises au cours d’un dialogue. Il peut faire des erreurs, soit dans l’interprétation linguistique des messages échangés, soit dans leur substance par une connaissance insuffisante, en particulier parce que ces modèles sont encore statiques et n’évoluent pas dans le temps.
Néanmoins (même si cela peut arriver à chacun d’entre nous), le modèle ne se rend pas compte qu’il peut se tromper et n’essaie généralement pas de clarifier une situation ou de compléter ses connaissances. D’autre part, alors que le dialogue exige d’anticiper le cours d’une conversation, ChatGPT ne fait aucune planification. Il ne s’appuie que sur les phrases précédentes au cours de la discussion et ses connaissances fixes. Grâce à la grande capacité de ChatGPT à produire du texte convaincant et naturel, cela crée l’illusion d’un raisonnement. Cette illusion d’intelligence peut être dangereuse dans certaines situations, au cours desquelles le modèle fournit des informations trompeuses à des personnes crédules. En résumé, même si ChatGPT ne doit pas être utilisé de manière autonome pour discuter avec des utilisateurs, il peut néanmoins être utile pour aider les êtres humains à réaliser efficacement des tâches spécifiques tant que l’utilisateur est conscient de ses limites et de ses défauts. Cette démarche s’inscrit dans un besoin plus général d’éducation des gens sur les risques éthiques induits par tous ces nouveaux modèles d’IA générative comme ChatGPT, MidJourney, etc.
De plus, les grands modèles comme ChatGPT comportent un impact écologique important. Ils ont besoin d’une énorme quantité d’énergie pour être formés et exploités à l’aide d’infrastructures matérielles massives dont l’empreinte carbone n’est pas viable. En outre, dans certains cas, la performance de ChatGPT est comparable à celle de modèles plus petits, donc moins chers, formés sur la même tâche, comme la reconnaissance d’entités nommées ou l’analyse de sentiment. Ou pire encore, par exemple, ChatGPT (et d’autres modèles similaires) est souvent recherché pour sa capacité à faire des calculs, alors que les calculatrices existent déjà, font preuve de précision et induisent une faible consommation d’énergie. Bien que des propositions aient émergé pour déléguer des tâches à des sous-systèmes plus petits (par exemple, ToolFormer par Meta), l’accent est plutôt mis sur la fourniture de réponses plus précises plutôt que sur la réduction de l’empreinte carbone.
Il y a actuellement une explosion de grands modèles de langue, également formés sur des conversations comme BlenderBot de Meta. Il existe des équivalents de ChatGPT : Bard de Google, Sparrow de DeepMind, Alpaca de Stanford et Llama de Meta. Les faiblesses soulignées dans cet article figurent dans le programme de ces modèles. En outre, et pour conclure, les conversations entre êtres humains ne se limitent pas au langage naturel, mais comprennent également d’autres modalités qui apportent des informations complémentaires (par exemple, l’élocution ou l’expression du visage peuvent informer sur les émotions, les gestes peuvent clarifier des ambiguïtés, etc.). Ici encore, les premiers modèles multimodaux émergent, comme l’illustre la récente version d’OpenAI GPT4.
[1] ELIZA est le tout premier chatbot. Un psychanalyste laissait l’utilisateur diriger la conversation en répondant par des commentaires génériques et des questions ouvertes, https://en.wikipedia.org/wiki/ELIZA
[2] Les modèles d’IA auxquels nous nous référons sont ceux qui ont été formés en utilisant des techniques de machine learning telles que l’apprentissage supervisé (par exemple, les Transformer).
[3] Sutton and Barto, Reinforcement Learning: An Introduction, 2nd edition.
https://web.stanford.edu/class/psych209/Readings/SuttonBartoIPRLBook2ndEd.pdf. Steve Young et al. POMDP-based Statistical Spoken Dialogue Systems: a Review. http://mi.eng.cam.ac.uk/~sjy/papers/ygtw13.pdf
[4] Jinjie ni et al. Recent Advances in Deep Learning Based Dialogue Systems: A Systematic Survey. https://arxiv.org/abs/2105.04387
[5] L. Ouyang et al. Training language models to follow instructions with human feedbacks, NEURIPS 2022. https://proceedings.neurips.cc/paper_files/paper/2022/hash/b1efde53be364a73914f58805a001731-Abstract-Conference.html
[6] A. Vaswani et al. Attention is all you need, NEURIPS 2017. https://papers.nips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
[7] Au moment de la rédaction de ce document, OpenAI n’a publié que très peu d’informations publiques sur la façon dont ChatGPT a été formé.
[8] H. H. Clark & S. E. Brennan, Grounding in communication (1991). http://www.psychology.sunysb.edu/sbrennan-/papers/old_clarkbrennan.pdf







