


Les biais dans les systèmes basés sur l’Intelligence Artificielle (SIA) peuvent entraîner des décisions erronées voire des discriminations qui affectent négativement les individus et les groupes sociaux. Par exemple une étude récente révèle que les fiches de poste générées par des IA génératives véhiculent bien plus de stéréotypes que celles rédigées par des personnes : ainsi, les descriptions de postes rédigées par GPT-4o sont plus biaisées que le travail produit par un être humain. Avec l’usage exponentiel et la popularité croissante des grands modèles de langage (LLMs), ces préoccupations deviennent critiques. Les , utilisés dans divers domaines allant de l’assistance virtuelle à la génération de contenu, sont de plus en plus intégrés dans des applications à grande échelle, que ce soient les moteurs de recherche ou les suites bureautiques par exemple. Cette adoption massive par les utilisateurs et entreprises souligne la nécessité de comprendre et gérer les biais pour garantir des systèmes équitables et responsables. Selon le Stanford AI Index 2024, les publications scientifiques concernant l’équité et les biais ont augmenté de 25% depuis 2022.
Les biais dans les LLMs peuvent être dans les représentations internes au modèle ainsi que dans les décisions finales. L’atténuation des biais dans les LLMs peut se faire avec ou sans entrainement supplémentaire.
Enjeux règlementaires
En parallèle, le règlement européen sur l’intelligence artificielle (AI Act), entré en vigueur progressivement à compter du 2 aout 2024, vise à encadrer le développement, la mise sur le marché et l’utilisation de SIA. La loi classifie les SIA selon les risques qu’ils présentent, allant des risques inacceptables aux risques minimaux. Ainsi, tout système de notation sociale basé sur l’IA est interdit, un SIA assistant dans les taches de recrutement ou de formation est considéré à haut risque et assujetti à des obligations renforcées, tandis que les robots conversationnels (chatbots) aux risques limités ne sont soumis qu’à des obligations de transparence. En cas de système classé à haut risque, des mesures « appropriées » doivent être mises en place pour détecter, prévenir et atténuer les éventuels biais dans les données ayant servi à l’entrainement des modèles. Ces obligations revêtent une importance accrue lorsque ces biais sont susceptibles d’affecter la santé et la sécurité des personnes, d’avoir une incidence négative sur les droits fondamentaux ou d’entraîner une discrimination prohibée par le droit de l’Union, notamment lorsque les données de sortie influencent les données d’entrée pour des opérations futures. Ainsi, un SIA classé à haut risque, tel qu’un outil d’assistance au recrutement ou à la formation, est soumis à ces exigences strictes en matière de gestion des biais. Nous détaillerons dans cet article plus particulièrement le cas de la gestion des biais des LLM.
Mais qu’est-ce qu’un LLM ?
Un modèle de langue (LM) est un modèle statistique conçu pour représenter le langage naturel. Les LLMs sont des versions avancées de ces modèles, entraînés sur des ensembles de données massifs et utilisant des architectures sophistiquées. Leur capacité à comprendre et à générer du texte de manière cohérente et contextuellement pertinente révolutionne les applications du , améliorant les performances des systèmes de traduction automatique, de génération de texte, d’analyse de sentiments et d’interactions homme-machine.
Et qu’est-ce qu’un biais ?
Un biais peut être défini comme un écart à la norme. Dans le domaine de l’IA, quatre grandes familles de normes ont été identifiées et par là même quatre types de biais : biais statistique (exemple: retenir une moyenne qui simplifie le phénomène étudié), biais méthodologique (exemple: utiliser un appareil pas assez précis pour mesurer le phénomène étudié ou encore utiliser aujourd’hui un LLM entrainé avec des données qui ne sont pas d’actualité), biais cognitifs (exemple: prendre une décision subjective et non rationnelle) et enfin biais socio-historique (exemple: entrainer un LLM avec des données d’un seul pays pour l’utiliser dans d’autre pays ne partageant pas les mêmes visions du monde).
Les LLM sont biaisés
Les biais dans les SIA trouvent leur source dans les données ayant servi à entrainer le modèle, dans les choix d’architecture et dans l’usage inadapté du SIA. Dans les LLMs, le corpus massif de données de pré-entrainement, le processus d’adaptation (alignement avec des valeurs humaines, spécialisation dans une langue ou un domaine…), le choix d’atténuation des biais et la nature du (ex. quel jeu de rôle) peuvent causer des préjudices d’allocation (distribution inégale des ressources) ou de représentation (renforcement des stéréotypes). Si les préjudices d’allocation produisent des effets immédiats, faciles à formaliser, les préjudices de représentation quant à eux produisent des effets à long terme et sont plus difficiles à formaliser.
En ce qui concerne les LLMs génératifs, leur pipeline de développement s’appuie majoritairement sur deux blocs : un modèle de base, développé pour encoder le langage et ses règles et un deuxième modèle, plus adapté pour répondre à des instructions spécifiques (ex : questions/réponses ouvertes). Ce deuxième modèle peut encore être modifié ensuite pour mieux correspondre à la tâche voulue (ex : agent conversationnel pour relation client) et/ou être aligné avec des valeurs choisies (ex : respect de la charte éthique de l’entreprise).
La chaîne de construction d’un s’illustre de la manière suivante :
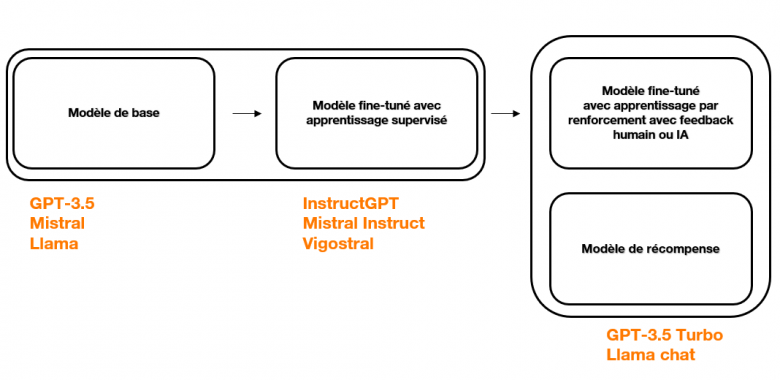
Les biais dans les LLMs peuvent ainsi se manifester à la fois dans le modèle en lui-même (biais intrinsèque, présent dans les représentations internes aux modèles) et dans les décisions finales prises par le modèle (biais extrinsèques, présents dans les décisions et prédictions finales).
Comment évaluer les biais dans les LLMs ?
L’évaluation des biais dans les LLMs passe par des méthodes intrinsèques et extrinsèques. Les méthodes intrinsèques incluent l’analyse des relations entre les mots dans les représentations internes du modèle ou l’observation des différences dans la façon dont le modèle attribue des probabilités aux mots. Les méthodes extrinsèques, quant à elles, se concentrent sur les performances des modèles sur des tâches spécifiques. Des métriques d’évaluation existent, spécifiques aux tâches classiques de TAL, qui visent à mesurer la qualité des LLMs sur des jeux de données de référence ou du texte généré. De plus, l’utilisation de (ensembles comprenant un jeu de données de test ainsi que des métriques d’évaluation adaptées à une tache spécifique du Traitement Automatique du Langage ) peuvent permettre de mesurer la qualité et l’efficacité des modèles sur des tâches spécifiques, telles que la traduction automatique, la génération de texte, etc. Cependant, les jeux des données de tests proposés dans les benchmarks peuvent apporter eux-mêmes leur lot de biais. La question de la pertinence des benchmarks utilisées est donc un enjeu primordial pour l’évaluation des LLMs.
Atténuer les biais
L’atténuation des biais dans les LLMs peut se faire avec ou sans entrainement supplémentaire.
- Avec un entraînement supplémentaire, on peut utiliser des méthodes pour fine-tuner (fine-tuning supervisé ou semi-supervisé), ou encore des méthodes pour aligner les modèles avec les valeurs attendues (via l’apprentissage par renforcement avec des retours humains ou des autodiagnostics). Ces méthodes permettent d’ajuster les modèles pour réduire les biais tout en maintenant leurs performances mais sont gourmandes en ressources et peuvent intégrer de nouvelles opinions, à savoir de nouvelles représentations, et par conséquent de nouveaux biais, consubstantiels aux nouvelles données ajoutées pour ces techniques d’atténuation.
- Sans entraînement supplémentaire, des techniques comme l’auto-diagnostic post-génération[1] ou le prompt engineering peuvent être utilisées. Ces techniques, qui ne demandent pas d’entraînement supplémentaire, sont plus frugales et nécessitent moins d’expertise. Elles sont donc plus faciles à mettre en place. D’une part, l’auto-diagnostic post-génération consiste à concevoir des instructions spécifiques pour guider le modèle dans la génération de réponses plus équitables et moins biaisées. Celui-ci repose sur la capacité du modèle à évaluer ses propres sorties après les avoir générées. D’autre part, en utilisant des prompts soigneusement formulés, il est possible de contraindre le modèle à adopter des perspectives variées et à éviter les stéréotypes. Le prompt engineering avec jeu de rôle, où le profil du répondant est précisé (ex. genre, niveau d’éducation) est également une méthode efficace pour révéler et atténuer certains biais. Par exemple, en demandant au modèle de répondre à une question en se mettant à la place d’un expert ou d’une personne d’un groupe social spécifique, les biais implicites dans les réponses générées peuvent être identifiées et corrigés.
La vigilance et le compromis sont parfois nécessaires pour que les actions menées pour limiter les biais n’entraînent pas une baisse de la performance du modèle.
Quel plan d’action en entreprise ?
Une gouvernance appropriée doit être associée et mise en place, comprenant une définition de lignes directrices pour la gestion des biais, la nomination de référents éthique, ainsi que des responsables en charge du déploiement de la formation destinées aux employés et, enfin, la mise en place d’une veille active et de développement d’outils techniques. Il est essentiel de garantir une diversité des profils dans les équipes impliquées dans le développement des SIA.
En complément, plusieurs actions doivent être menées au cas par cas, en fonction du cas d’usage, du contexte de déploiement et des personnes concernées.
Dans un premier temps, il convient de choisir les critères et métriques d’équités poursuivis, puis d’identifier la tâche de TAL sous-jacente au cas d’usage et les biais connus. Ensuite, il est nécessaire de comparer différents LLMs en s’appuyant sur un benchmark qui, s’il n’est pas préexistant dans la littérature, devra être développé. Développer un benchmark nécessite la collecte de données, leur annotation si nécessaire, la définition de la tâche et les façons de mesurer que la tâche est bien réalisée sur le corpus de données (métriques d’évaluation). Puis il s’agit de sélectionner le modèle le moins biaisé (et suffisamment performant) en comparant les résultats de différents modèles sur le benchmark utilisé. Enfin, via le prompt engineering, la dernière étape consiste à comparer les résultats obtenus sur le benchmark avec différents prompts pour essayer d’optimiser le prompt, selon les critères d’équité choisis. A noter que les performances des modèles peuvent varier en fonction des paramètres du prompt (température[2], instruction[3], contexte[4], fournir des exemples[5] ou pas et prompt système[6]) et du rôle pris dans le prompt. Tester et ajuster les modèles en fonction des cas d’usage spécifiques est donc essentiel.
Conclusion
En conclusion, la gestion des biais dans les LLMs reste un sujet complexe et en pleine évolution. Bien que des méthodes existent pour évaluer (méthodes intrinsèques et extrinsèques, benchmark existant ou à créer) et atténuer les biais (avec ou sans entrainement supplémentaire), le domaine n’a pas encore atteint une maturité complète. Au sein des entreprises, l’accent est actuellement mis sur l’organisation, le développement de prototypes et d’expérimentations. Développer des LLMs équitables et responsables aidera sans doute à l’adoption à grande échelle des LLMs.
[1] Cette technique repose sur la capacité du modèle à évaluer ses propres sorties après les avoir générées. Le modèle utilise des critères prédéfinis pour évaluer la qualité et l’équité de la sortie générée (ex: donne-moi la réponse et dis-moi si elle est biaisée). Ces critères peuvent inclure des mesures de biais, de stéréotypes ou de toxicité. Si la sortie initiale est jugée biaisée ou inappropriée, le modèle peut soit ajuster la sortie en temps réel, soit générer une nouvelle réponse en tenant compte des critères d’évaluation. La sortie révisée est ensuite validée pour s’assurer qu’elle répond aux critères d’équité et de qualité avant d’être présentée à l’utilisateur.
[2] Régler la température du modèle permet de contrôler la créativité et la diversité des réponses générées. La température est un hyperparamètre qui contrôle la probabilité de sélection des mots suivants dans une séquence. Une température basse (proche de 0) rend le modèle plus déterministe, tandis qu’une température élevée (proche de 1) augmente la diversité des réponses.
[3] Les Instructions fournissent des directives claires sur la tâche à accomplir. Les instructions doivent être rédigées de manière concise et précise pour minimiser les ambiguïtés et guider le modèle vers une réponse spécifique.
[4] Un contexte peut être ajouté dans le prompt pour apporter des informations générales pour aider à la compréhension de l’instruction. Le contexte est à intégrer au début du prompt pour situer le modèle dans un cadre spécifique et orienter ses réponses.
[5] Fournir un ou plusieurs exemples de la prédiction attendue peut aider le modèle à comprendre la tâche. L’exemple doit être représentatif de la tâche et être placé en fin de prompt pour maximiser son impact.
[6] Il s’agit d’ajouter des directives pour limiter les réponses du modèle à un format spécifique, réduisant ainsi le bruit et les réponses non pertinentes.
Traitement Automatique du Langage (TAL)
Également connu sous le nom de Traitement du Langage Naturel (TLN), c’est un domaine de l’intelligence artificielle qui se concentre sur la compréhension et la manipulation du langage humain par des machines. Il englobe des tâches telles que la traduction automatique, la reconnaissance vocale, l’analyse de sentiment, la génération de texte, etc.
Courte phrase ou court texte donné en entrée à un modèle de langage pour l’orienter dans la génération de texte. Il peut être utilisé pour spécifier le sujet, le style ou les contraintes du texte à générer. Le prompt peut influencer le contenu et la structure du texte généré par le modèle.
Type spécifique de modèle de langage capable de générer du texte de manière autonome. Lorsque vous formez un LLM comme Llama, Bard ou GPT-4, vous lui apprenez à générer du texte basé sur un large éventail d’exemples précédents.
En Traitement Automatique du Langage (TAL), un benchmark est un ensemble comprenant un corpus de données, des tâches et des façons de mesurer que la tâche est bien réalisée sur le corpus (métriques d’évaluation). Les benchmarks servent de référence pour mesurer la qualité et l’efficacité des modèles sur des tâches spécifiques, telles que la traduction automatique, la génération de texte, l’analyse de sentiment, etc. Ils permettent aux chercheurs et aux développeurs de déterminer comment un modèle se comporte par rapport à d’autres modèles sur des critères objectifs et reproductibles.
 Christèle Tarnec
Christèle Tarnec
 Anais Bekolo
Anais Bekolo
 Emilie Sirvent-Hien
Emilie Sirvent-Hien







