

Plusieurs média ont déclaré 2016 Année de l’Intelligence Artificielle (IA dans la suite). Le sujet fait en effet le buzz, avec de nombreux articles, conférences, émissions qui lui sont consacrées.
Cet engouement fait suite à une séries d’annonces de progrès spectaculaires obtenus et surtout annoncés depuis environ 2 ans dans certains domaines, comme la reconnaissance faciale, la reconnaissance vocale, ou encore tout récemment le jeu de go (AlphaGo), principalement dues à l’utilisation d’algorithmes de Deep Learning, ou apprentissage neuronal profond, sur des grandes bases de données.
Ce qui frappe dans tout ce flot médiatique, c’est l’extrême diversité des solutions présentées comme relevant de l’IA, ce qui laisse à penser que l’IA ne constitue pas une unique technologie, mais un domaine technologique et scientifique traitant un vaste ensemble de questions différentes. Dans ce contexte, le but de cet article est de rappeler la définition de l’IA et d’en décrire les différentes facettes.
Définition et composantes de l’Intelligence Artificielle
L’intelligence Artificielle est un domaine vaste et pluridisciplinaire dont l’unité tient dans l’ambition initiale de faire reproduire par les machines des compétences cognitives qui sont normalement l’apanage de l’être humain : perception de l’environnement, représentation conceptuelle du monde, pensée, raisonnement, décision pour action.
De fait, l’IA est assez logiquement structurée en différents champs scientifiques traitant chacun une famille relativement homogène de problèmes et visant à mettre au point des solutions reproduisant, si possible en plus performantes, de telles compétences [1].
- le raisonnement constitue le cœur historique de l’IA. Il consiste à prédire des faits nouveaux à partir de règles ou de propriétés générales et de faits connus, donc de connaissances théoriques, et qui repose essentiellement sur les (langages) logiques mathématiques, mais également sur les probabilités pour prendre en compte l’incertitude inhérente aux connaissances dans certains domaines. Le raisonnement artificiel est basé sur l’exécution de moteurs d’inférence, c’est-à-dire de calcul logique sur des ensembles de connaissances formelles qui en constituent donc le carburant, les 2 aspects étant ainsi découplés.
pour approfondir, voir [2][3][4].

Les 4 types d’inférence
- la représentation des connaissances constitue le support au raisonnement, mais également à certaines approches de traitement automatique de la langue naturelle à des fins d’extraction d’information ciblée. Les modèles choisis pour représenter les connaissances varient selon le contexte. En ingénierie des connaissances et recherche d’information, on utilise les ontologies, pouvant revêtir des formes variées, depuis des thésaurus classiques de l’ingénierie documentaire, aux ontologies formelles retenues comme cadre par le W3C pour le Web Sémantique. Dans le domaine des systèmes dit « à base de connaissances », c’est-à-dire la version moderne des systèmes experts, on utilise plutôt la logique des prédicats du 1er ordre pour représenter des connaissances constituées de faits et des règles permettant de prendre aussi en compte des connaissances comportementales ou décisionnelles.
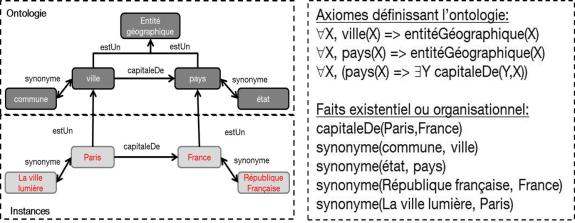
Représentation de connaissances sous forme ontologique (g) et en logique des prédicats du 1er ordre (d)
Les approches actuelles de production de telles connaissances formelles sont essentiellement manuelles, et se heurtent à des écueils de nature fondamentalement linguistique (synonymie, paraphrase, polysémie).
pour approfondir, voir [5][6][7][8].
- le traitement automatique de la langue naturelle (TALN) traite des grandes questions liées au langage humain : la production automatique de textes exprimant un sens donné, la compréhension automatique de la langue, la traduction. Le dialogue est parfois considéré comme relevant du TALN. Cependant, nous pensons plutôt qu’un agent dialoguant (conversationnel, chatbot) constitue une machine intelligente associant plusieurs composantes de l’IA, dont la planification (Dialog Planning). La compréhension automatique de la langue comprend l’analyse sémantique lexicale : signification des mots en contexte, l’analyse sémantique propositionnelle : extraction du sens de la phrase et l’analyse discursive : sens d’un énoncé ou discours multi-phrases.
L’extraction du sens lexical consiste, dans son principe, à rapprocher un mot ou plus généralement un terme (locution composée de plusieurs mots et désignant un concept) d’un référentiel sémantique lexical, de type ontologie ou thésaurus.
Une des approches phare en extraction du sens propositionnel est l’analyse en « cadres sémantiques » (Frames), consistant à identifier au sein d’une proposition (une phrase peut articuler plusieurs propositions), d’une part le prédicat pivot, et d’autre part les arguments de celui-ci ainsi que la sémantique de leurs rôles : en résumé, trouver qui a fait quoi, à qui, où, comment,…

Un exemple de frame sémantique
pour approfondir, voir [9][10][11].
- les technologies de reconnaissance sensorielle: reconnaissance visuelle, sonore, gestuelle, ainsi que de la parole (transcription),… La perception constitue la couche d’interface entre le monde extérieur et les centres de décision et de raisonnement au sein du cerveau. Les applications de la perception artificielle trouvent naturellement leur place dans l’Interaction Homme-Machine, l’indexation des contenus multimédia (photos, vidéo, audio) ou encore la sécurité (biométrie). C’était jusqu’à ce début d’année la discipline de l’IA qui avait connu les avancées les plus spectaculaire, grâce au Deep Learning, désormais rejointe par d’autres disciplines de l’IA.
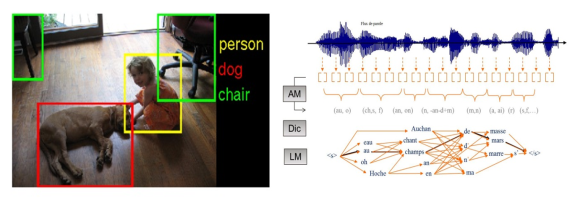
Deux exemples de perception des formes: la reconnaissance de concepts visuels (g) et la transcription de parole (d)
- Les fonctions décisionnelles, ou exécutives, dont le but est de permettre à des systèmes artificiels, les agents intelligents, de prendre des décisions d’actions.Des telles décisions peuvent être unitaires, isolées, comme par exemple décider d’une liste de films à proposer pour un système de recommandation, ou au contraire constituer des processus décisionnels c’est-à-dire des suites de décisions pour action at sur un système S pour atteindre un but donné (défini par une condition de fin Condf(st)) en visant un critère d’optimalité (récompense totale sur le long terme, appelée « utilité ») ou simplement en satisfaisant des contraintes d’exécution. Selon le contexte, la nature exacte des problèmes traités, mais surtout la communauté scientifique concernée, on parle de planification, contrôle automatique ou encore résolution de problèmes, qui recouvrent des réalités assez proches. De même, on désigne de tels processus décisionnels par les termes de plan, politique ou stratégie.
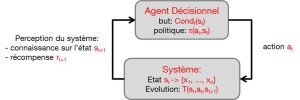
Formalisation générale d’un problème de planification / contrôle
pour approfondir, voir [12][13] [14][15].
- les systèmes multi-agents (SMA), modélisent une intelligence collective, à l’aide d’une collection d’agents intelligents, chacun mettant en œuvre chacun un processus décisionnel agissant sur une partie de l’environnement, en fonction de ses propres connaissances ou croyances locales, d’un intérêt personnel ou collectif, de manière coopérative, compétitive ou neutre. Il s’agit donc d’un processus de planification distribué, qui peut avoir des objectifs de pilotage optimal d’un système à l’instar d’une commande centralisée, mais peut également servir à simuler des organisations sociales de différentes natures : animales, humaines, artificielles,… Une application récente est par exemple la modélisation du marché du travail. On distingue d’une part les systèmes multi-agents rationnels où chaque agent cherche à maximiser son gain en anticipant sur les décisions des autres agents, et d’autre part les systèmes multi-agents réalistes, visant à reproduire au mieux des comportements réels.L’apprentissage multi-agents combine les modèles de la planification stochastique et de la théorie des jeux matriciels et consiste à entraîner un agent virtuel rationnel contre lui-même (self-play) pour déterminer des stratégies optimales, tandis que la simulation multi-agents réaliste vise à modéliser le comportement collectif réel d’une population animale ou humaine dans une situation donnée, par exemple en utilisant des modèles comportementaux individuels de type BDI (Belief, Desire, Intent).
pour approfondir, voir [16][17].

Modèle général d’un Système Multi-Agents
- Les machines ou systèmes intelligents sont des assemblages de technologies issues de tout ou partie des précédents domaines, dans le but de constituer une solution applicative spécifique, telle qu’un assistant virtuel personnel (Siri, Viv, Google Assistant, Cortana,…), un véhicule autonome, un système de gestion de contenu, un réseau télécom cognitif…
Les deux grandes familles d’Intelligence Artificielle
Il est coutume dans les structurations académiques de l’IA de distinguer une IA anthropomorphique visant à imiter le fonctionnement de l’intelligence humaine, et recouvrant essentiellement la reconnaissance des formes sensorielles et le traitement du langage, et une IA rationnelle, visant à la prise de décisions rationnelles, et recouvrant essentiellement les fonctions décisionnelles et le raisonnement, voire les systèmes multi-agents. La nature et la finalité des tâches relevant de ces 2 grands courants met en évidence une autre dénomination possible de ces branches en distinguant une Intelligence Artificielle d’Interface permettant un à un agent intelligent de s’interfacer et communiquer avec son environnement physique ou humain, et une Intelligence Artificielle Décisionnelle qui décide des actions à effectuer sur cet environnement. Sur le plan méthodologique, la 1ère branche est aujourd’hui largement dominée par les approches neuro-inspirées de l’apprentissage neuronal profond (Deep Learning), tandis que la 2nde fait largement appel aux outils mathématiques décisionnels, tels que les logiques, l’apprentissage machine et le raisonnement probabilistes, la recherche opérationnelle ou la théorie des jeux. De ce fait, cette dernière branche englobe les méthodes décisionnelles du Big Data (data analytics, data mining,…) qui consistent à appliquer les outils d’apprentissage machine sur de grands gisements de données pour en extraire de la connaissance et prendre des décisions statistiquement optimales.
En savoir plus :
- Introduction à l’IA : définitions, genèse, domaines, représentation des connaissances et langages dédiés, Fabrice Lauri, cours de l’Université Technologique de Belfort-Montbéliard, 2009.
- Systèmes à base de connaissances : une introduction, Alain Mille, LIRIS, 2007-2011
- Architecture des systèmes à base de connaissances et introduction à Prolog, Fabrice Lauri, cours de l’Université Technologique de Belfort-Montbéliard, 2009.
- Approche Agent en Intelligence Artificielle – Raisonnement probabiliste, B. Chaib-draa, cours de l’Université Laval.
- Tutoriel SPARQL.
- Ingénierie ontologique, concepts, méthodes et outils, Gilles Kassel.
- W3C/Semantic Web
- The unreasonable effectiveness of data, Alon Halevy, Peter Norvig and Fernando Pereira, in IEEE Intelligent Systems, 2009.
- Notion de base en lexicologie, Alain Polguère, Observatoire de Linguistique Sens-Texte (OLST), Université de Montréal, 2001.
- Introduction au TALN et à l’ingénierie linguistique, I. Tellier, cours de l’université de Lille3, 2007
- Dépendances syntaxiques de surface pour le français, Marie Candito, Benoît Crabbé, Mathieu Falco, Oct. 2009.
- Approche Agent en Intelligence Artificielle – Note de cours, B. Chaib-draa, cours de l’Université Laval.
- Apprentissage par renforcement, Bruno Bouzi, septembre 2014
- Reinforcement learning, Florentin Woergoetter and Bernd Porr, Scholarpedia,
- Le vieillissement des fonctions cognitives, Cécile Cimetière et Sophie Schumm, Hopital Charles Foix, Ivry sur Seine.
- Modélisation et simulation multi-agents – cours 1 – prolégomènes, Jean-Daniel Kant, LIP6, cours de l’Université Pierre et Marie Curie.
- Apprentissage multi-agent, Marc-Olivier LaBarre, Département d’Informatique et de recherche opérationnelle, Université de Montréal.