


Passer de la commande vocale au dialogue : c’est tout le défi de l’intelligence artificielle pour produire des assistants virtuels plus vrais que nature.
Résumé
Dépasser le paradigme de la commande vocale et l’inscrire dans un dialogue : c’est tout le défi actuel de l’intelligence artificielle pour produire des assistants virtuels plus vrais que nature. Même si la recherche s’oriente dans ce sens depuis près de deux décennies, le cœur de la difficulté pour parvenir à des dialogues homme-machine naturels tient au caractère extrêmement dynamique de la résolution de tâches par le dialogue. Cette dynamique implique la définition de stratégies de gestion des échanges face à une complexité exponentielle – puisque chaque nouveau tour d’interaction se doit d’être traité en fonction de tous les précédents – et afin de prendre en compte des situations problématiques telles que des quiproquos ou un changement d’avis de l’usager.
On est donc encore loin des fantasmes de la science-fiction, mais les machines sont déjà capables de beaucoup de choses et la recherche s’oriente actuellement vers des pistes prometteuses. Parmi celles-ci la constitution automatique de systèmes de dialogues à partir de contenus, les assistants multitâche, ou encore la création de systèmes de dialogues incrémentaux : rompant le modèle de dialogue au tour par tour, cela laisse à chacun la possibilité de prendre la parole quand il le souhaite pour signaler une erreur ou ajouter une référence.
Article complet
Le mythe, initié par les livres de science-fiction, s’est matérialisé au grand public à travers le cinéma (HAL 9000, R2-D2, Samantha ou TARS), et les grandes compagnies ne se sont bien sûr pas privées de l’entretenir pour promouvoir leurs technologies d’assistants personnels : Siri, Google Now, Cortana, ou Echo. Les dernières avancées de la recherche académique et les multiples initiatives industrielles permettent d’entrevoir une réalité à la promesse de communication naturelle avec un système doté de la parole. Il reste cependant de nombreux défis techniques et scientifiques à relever pour atteindre cette promesse.
Il est vrai que le traitement du signal audio par des modèles appris avec du Deep Learning (Hinton 2012) ont considérablement amélioré les performances des technologies de reconnaissance vocale. Il est exact que couplé à des technologies de recherche d’information, on peut obtenir des réponses/actions à toutes sortes de commandes vocales : dois-je prendre un parapluie ? Quelle heure est-il ? Appelle maman.
Mais nous resterons à l’âge préhistorique de l’assistant personnel tant que nous ne saurons pas dépasser le paradigme de la commande vocale et l’inscrire dans un dialogue. On appelle formellement un dialogue un échange d’informations entre deux (ou plus) interlocuteurs. Un interlocuteur peut être un humain ou une machine. La plupart des dialogues ont pour objectif la réalisation d’une tâche. Autrement dit, ces interlocuteurs vont collaborer pour réaliser la tâche. La tâche peut elle-même être composée de sous-tâches. La résolution de la tâche et des potentielles sous-tâches se fait usuellement par rapport à l’instanciation d’une représentation sémantique. Le problème du dialogue est autrement plus complexe que celui du décodage de la voix. Il a même une complexité exponentielle, puisque chaque nouveau tour d’interaction se doit d’être traité en fonction de tous les précédents.
Un marché en très forte expansion
En intelligence artificielle, les premiers systèmes de dialogue commerciaux datent d’une vingtaine d’années et servent à automatiser les centres d’appel sous le nom de serveur vocal interactif, avec un accueil relativement mitigé de la part des utilisateurs finaux, puisque il était imposé en remplacement d’un service humain. Mais la démocratisation date seulement de 2011 avec la sortie de Siri, qui est proposée en supplément d’autres modes d’interaction plus classiques.
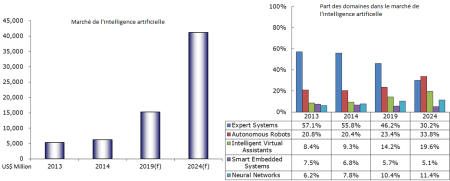
Pour illustrer cet intérêt grandissant pour la technologie des interfaces dialoguantes et des assistants personnels en particulier, nous pouvons citer une étude réalisée par MIC (Market Intelligence & Consulting Institute), qui montre que le marché de l’intelligence artificielle devrait suivre une évolution exponentielle sur les dix prochaines années et que les assistants personnels (appelés Virtual Intelligent Assistant dans l’étude) en seront l’acteur principal en multipliant par 2.5 sa part relative du marché de l’intelligence artificielle. Selon cette même étude, entre 2014 et 2024, le marché des assistants personnels devrait avoir un taux de croissance annuel moyen de 30.0 %, et ainsi voir son chiffre d’affaire multiplié par 14.
Une architecture modulaire entre traitement du signal, de la langue et de la stratégie d’interaction
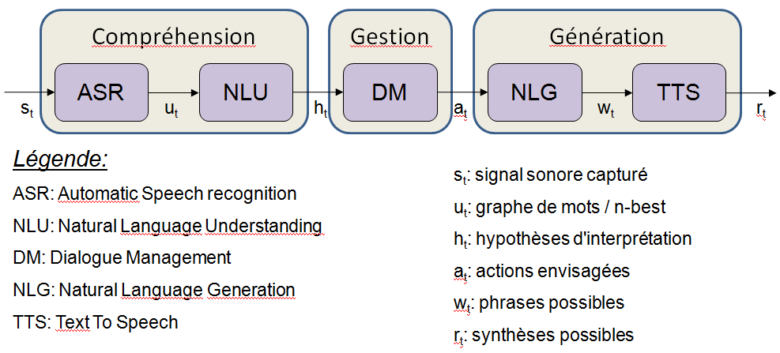
Usuellement, un système de dialogue homme-machine est composé de différents modules (Jurafsky 2009, Landragin 2013), que l’on peut regrouper sous trois grandes catégories :
- Compréhension : situé en sortie de l’input (qui peut être la reconnaissance vocale, la saisie textuelle), il s’agit d’extraire le sens de ce qu’a dit l’utilisateur, avec éventuellement prise en compte d’informations contextuelles. Les techniques utilisées ici relèvent du Traitement Automatique du Langage Naturel ; il s’agit d’utiliser une représentation sémantique (modèle de langage) définie de manière symbolique, par apprentissage automatique, ou hybride.
- Gestion : ici est pris en compte l’aspect… dialogique du dialogue. Le dialogue est en effet une suite dynamique d’échanges entre l’utilisateur et le système, ce qui implique la définition de stratégies de gestion de ces échanges, notamment pour remplir les différents sous-buts évoqués plus haut, et prendre en compte des situations problématiques telles que la non compréhension par le système de l’usager, un changement d’avis de ce dernier, etc.
- Génération : pour répondre à l’utilisateur, le système de dialogue a accès à une base de données qu’il interroge en fonction de ce qui est demandé (interprété au niveau de la compréhension automatique de la parole). Les informations récupérées sont ensuite formulées à l’utilisateur en langage naturel, comme le ferait un humain, via différentes modalités potentielles : vocale, mais aussi écrite. En plus de la formulation en langage naturel, le système peut aussi inclure d’autres types d’informations dans ses réponses à l’utilisateur : vidéos, lancement d’une application pertinente, etc. C’est aussi à ce niveau que sont produites les formulations du système liées aux stratégies de dialogue, par exemple des demandes de reformulation, de précision, …
 Orange Labs dispose d’une solution complète pour concevoir et implémenter un système de dialogue automatique : Orange Dialogue Studio (ODS). ODS a la particularité d’être une solution industrielle, utilisable par n’importe quel développeur, facilitant la réalisation d’applications de dialogue, et un support flexible pour la recherche académique.
Orange Labs dispose d’une solution complète pour concevoir et implémenter un système de dialogue automatique : Orange Dialogue Studio (ODS). ODS a la particularité d’être une solution industrielle, utilisable par n’importe quel développeur, facilitant la réalisation d’applications de dialogue, et un support flexible pour la recherche académique.
Un domaine de recherche reposant sur l’apprentissage par renforcement
Le renforcement, issu de la psychologie comportementale (Skinner 1948), est un processus qui construit un comportement animal de manière à répéter la génération d’un stimulus positif (récompense) ou à limiter l’apparition d’un stimulus négatif (sanction). En intelligence artificielle (Sutton 1998), il s’agit pour un agent, d’apprendre à adopter un comportement (c’est-à-dire un modèle d’action selon un état courant) permettant d’engendrer une somme de récompenses futures maximale. Le dialogue peut être modélisé en un problème d’apprentissage par renforcement (Lemon 2007, Young 2013) : l’état courant est déterminé par la compréhension que le système a de son utilisateur; sur la base de cet état, il décide d’une action à réaliser, de manière à optimiser son espérance de récompense, récompense qu’il reçoit lorsque la tâche est accomplie.
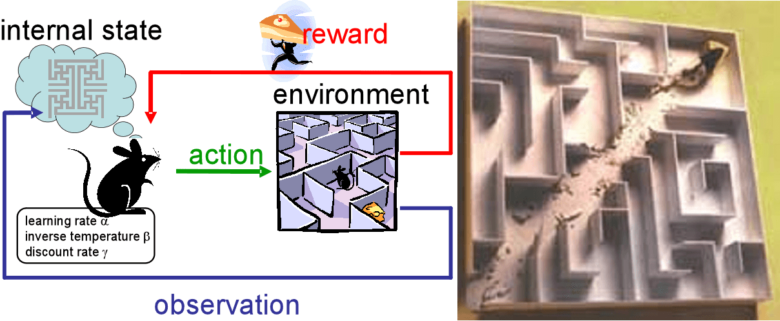
L’apprentissage par renforcement dans les systèmes de dialogue est la thématique de recherche principale depuis près de deux décennies (Levin 1997, Singh 1999). Le contexte applicatif du dialogue impose à l’apprentissage par renforcement d’être à la fois rapide (Gašić 2010, Pietquin 2011) : convergence en quelques centaines de dialogues ; et robuste au bruit (Williams 2007) : une bonne stratégie de dialogue n’est pas toujours gagnante et inversement, une mauvaise stratégie peut fonctionner par chance. Mais jusqu’à récemment, ces méthodes statistiques ne s’inscrivaient pas dans un processus industriel (Pieraccini 2005, Paek 2008).
De manière à remédier à cela, plusieurs travaux d’hybridation ont été menés de manière à ne laisser à l’algorithme d’apprentissage que des choix d’actions pertinentes, sans connaitre toutefois l’action optimale (Singh 2002, Williams 2008, Laroche 2009 & 2010a). Cependant, ces résultats ne restent utilisables que par des experts en apprentissage par renforcement. Dans le but de rendre accessibles à n’importe quel développeur ces techniques puissantes d’adaptation, plusieurs travaux ont été menés : le monitoring des résultats d’apprentissage (Laroche 2010b), la prédiction de la vitesse de convergence (El Asri 2013), ou encore la prédiction de la qualité de l’interaction (El Asri 2014).
Apple semble faire confiance à la recherche en dialogue, en particulier en provenance de l’université de Cambridge (Williams 2007, Gašić 2010, Young 2013) puisqu’ils ont racheté pour plus de 50M£ la start-up VocalIQ.
Une source inépuisable de nouveaux problèmes de recherche
Plus récemment d’autres thématiques de recherche prennent orthogonalement de plus en plus de place :
 L’évaluation des systèmes de dialogue : ils sont composés de plusieurs modules et l’évaluation individuelle technique de chacun de ces modules n’est pas suffisante. En effet, les comportements induits doivent être évalués en termes de justesse, conformité et satisfaisance (Dybkjaer 2004). L’évaluation subjective peut être réalisée par les utilisateurs après la réalisation d’un dialogue (Walker 1997), ou par des annotateurs experts (Evanini 2008). Il s’agit ensuite d’être capable d’estimer en ligne cette évaluation à partir de critères objectifs, tels que la longueur du dialogue, les états traversés, le nombre de rejets de l’ASR, etc. Cette estimation se fait par régression (Walker 2000), classification ou régression ordinale (El Asri 2014).
L’évaluation des systèmes de dialogue : ils sont composés de plusieurs modules et l’évaluation individuelle technique de chacun de ces modules n’est pas suffisante. En effet, les comportements induits doivent être évalués en termes de justesse, conformité et satisfaisance (Dybkjaer 2004). L’évaluation subjective peut être réalisée par les utilisateurs après la réalisation d’un dialogue (Walker 1997), ou par des annotateurs experts (Evanini 2008). Il s’agit ensuite d’être capable d’estimer en ligne cette évaluation à partir de critères objectifs, tels que la longueur du dialogue, les états traversés, le nombre de rejets de l’ASR, etc. Cette estimation se fait par régression (Walker 2000), classification ou régression ordinale (El Asri 2014).
![]() Les systèmes de dialogue incrémentaux (Skantze 2009, Schlangen 2011, Raux 2012, Khouzaimi 2014 & 2015) : l’objectif est de casser le modèle du dialogue au tour par tour, où chaque interlocuteur ne peut prendre la parole que lorsque l’autre lui la laisse explicitement, et d’offrir à chacun la possibilité de prendre la parole quand cela lui semble nécessaire pour corriger une erreur, notifier d’une incompréhension, faire référence à un élément particulier, etc. Cela implique un traitement incrémental de bout en bout de la chaîne de dialogue.
Les systèmes de dialogue incrémentaux (Skantze 2009, Schlangen 2011, Raux 2012, Khouzaimi 2014 & 2015) : l’objectif est de casser le modèle du dialogue au tour par tour, où chaque interlocuteur ne peut prendre la parole que lorsque l’autre lui la laisse explicitement, et d’offrir à chacun la possibilité de prendre la parole quand cela lui semble nécessaire pour corriger une erreur, notifier d’une incompréhension, faire référence à un élément particulier, etc. Cela implique un traitement incrémental de bout en bout de la chaîne de dialogue.
 Les systèmes de dialogue multi-tâche : les assistants personnels sont des couteaux suisses vocaux dont le rôle est de résoudre toutes sortes de tâches pour un utilisateur privilégié, ce qui implique plusieurs problématiques : l’extension d’un système existant à une nouvelle tâche (Gašić 2013), l’échange de contexte entre les différentes tâches (Planells 2013), la fusion de tâches de dialogue hétérogènes (Ekeinhor-Komi 2014), le dialogue avec les objets connectés, ou encore l’adaptation de l’assistant à l’utilisateur (Casanueva 2015, Genevay 2016).
Les systèmes de dialogue multi-tâche : les assistants personnels sont des couteaux suisses vocaux dont le rôle est de résoudre toutes sortes de tâches pour un utilisateur privilégié, ce qui implique plusieurs problématiques : l’extension d’un système existant à une nouvelle tâche (Gašić 2013), l’échange de contexte entre les différentes tâches (Planells 2013), la fusion de tâches de dialogue hétérogènes (Ekeinhor-Komi 2014), le dialogue avec les objets connectés, ou encore l’adaptation de l’assistant à l’utilisateur (Casanueva 2015, Genevay 2016).
 L’écoute des conversations homme-homme : sujet de recherche encore relativement confidentiel, et limité à des études très théoriques pour l’instant (Barlier 2015) parce qu’il s’agit d’un problème très dur, mais le besoin est réel : l’entreprise Expect Labs dont les investisseurs sont Google Ventures, Samsung, Intel, la CIA et d’autres en a fait son produit phare Mindmeld : une application qui écoute vos conversations téléphoniques et vous propose du contenu contextuel. Chez Orange, le besoin s’est exprimé depuis différents domaines : la maison connectée où les conversations sont nombreuses, les salles de réunions dont certaines tâches fastidieuses sont automatisables, les centres d’appel pour que l’opérateur puisse se focaliser sur son interaction avec le client sans perdre plus de temps que nécessaire avec ses outils, etc. Il est à noter que ce type d’application est fortement lié à des contraintes sur le respect de la vie privée qu’Orange prend très au sérieux.
L’écoute des conversations homme-homme : sujet de recherche encore relativement confidentiel, et limité à des études très théoriques pour l’instant (Barlier 2015) parce qu’il s’agit d’un problème très dur, mais le besoin est réel : l’entreprise Expect Labs dont les investisseurs sont Google Ventures, Samsung, Intel, la CIA et d’autres en a fait son produit phare Mindmeld : une application qui écoute vos conversations téléphoniques et vous propose du contenu contextuel. Chez Orange, le besoin s’est exprimé depuis différents domaines : la maison connectée où les conversations sont nombreuses, les salles de réunions dont certaines tâches fastidieuses sont automatisables, les centres d’appel pour que l’opérateur puisse se focaliser sur son interaction avec le client sans perdre plus de temps que nécessaire avec ses outils, etc. Il est à noter que ce type d’application est fortement lié à des contraintes sur le respect de la vie privée qu’Orange prend très au sérieux.
 La constitution automatique et directe de systèmes de dialogues à partir de contenus. Watson, le logiciel d’IBM qui a remporté Jeopardy face aux meilleurs concurrents humain est maintenant exploité industriellement pour répondre à ce genre de problématiques (Ferrucci 2012). Il s’agit d’utiliser des contenus susceptibles de faire l’objet d’un dialogue (par exemple, demande de renseignements sur un service public) pour en extraire les informations susceptibles de faire l’objet de requêtes d’utilisateurs, et les intégrer dans un système de dialogue. L’un des avantages serait une plus grande facilité et rapidité dans la conception et le déploiement des systèmes de dialogues (voir Laroche 2015 pour plus de détails). Cette thématique de recherche en est encore à ses balbutiements.
La constitution automatique et directe de systèmes de dialogues à partir de contenus. Watson, le logiciel d’IBM qui a remporté Jeopardy face aux meilleurs concurrents humain est maintenant exploité industriellement pour répondre à ce genre de problématiques (Ferrucci 2012). Il s’agit d’utiliser des contenus susceptibles de faire l’objet d’un dialogue (par exemple, demande de renseignements sur un service public) pour en extraire les informations susceptibles de faire l’objet de requêtes d’utilisateurs, et les intégrer dans un système de dialogue. L’un des avantages serait une plus grande facilité et rapidité dans la conception et le déploiement des systèmes de dialogues (voir Laroche 2015 pour plus de détails). Cette thématique de recherche en est encore à ses balbutiements.
 La multimodalité (Bellik 1995, Oviatt 2002, Bui 2006) : les systèmes de dialogue qui utilisent plus d’un mode de communication avec l’utilisateur (par exemple le vocal et le tactile) sont dits multimodaux. Les deux problématiques principales concernent la coordination entre les modalités : la fusion multimodale est la coordination de plusieurs entrées en provenance de modalités distinctes, tandis que la fission multimodale est la coordination de plusieurs sorties en direction de modalités distinctes.
La multimodalité (Bellik 1995, Oviatt 2002, Bui 2006) : les systèmes de dialogue qui utilisent plus d’un mode de communication avec l’utilisateur (par exemple le vocal et le tactile) sont dits multimodaux. Les deux problématiques principales concernent la coordination entre les modalités : la fusion multimodale est la coordination de plusieurs entrées en provenance de modalités distinctes, tandis que la fission multimodale est la coordination de plusieurs sorties en direction de modalités distinctes.
En conclusion, encore beaucoup de travail à réaliser
On est donc encore loin des fantasmes de la science-fiction, mais les machines sont déjà capables de comprendre et de faire beaucoup de choses. Leur usage va se démocratiser rapidement dans les années à venir. Les premières applications commerciales se multiplient et les perspectives de croissance sont élevées. Les utilisateurs vont apprendre à les utiliser, une co-adaptation va donc s’opérer dans un environnement changeant : de nouveaux écosystèmes, de nouvelles technologies, de nouvelles puissances de calcul et surtout de nouveaux usages. Orange s’est d’ores et déjà positionné et ce depuis plus de vingt ans, avec une solution industrielle et une activité soutenue en recherche, mais l’effort doit se maintenir en collaboration avec les bons partenaires comme en 2010 lors du projet Européen FP7 CLASSiC comprenant les laboratoires européens les plus influents en recherche sur les systèmes de dialogue, ou actuellement avec le projet d’anticipation FUI VoiceHome incluant entre autres des industriels à la pointe de la technologie : OnMobile, Technicolor et Delta Dore.
En savoir plus :
Dans leurs états actuels, Siri, Google Now et Cortana sont plus des solutions de recherche d’information vocale que des solutions de dialogue : la tâche est résolue en un tour de dialogue, et chaque nouvelle requête est traitée de façon indépendante de la précédente.
Un dialogue se place dans un contexte qui conditionne et définit la plupart des interactions. Ces informations de contexte peuvent être par exemple, la date, l’heure de la journée, le mode de communication (téléphone, face à face), le lieu (géolocalisation), la personne, etc.
Orange Dialogue Suite a servi à développer des services commerciaux recueillant plus de 200 millions d’appels par an. Côté recherche, Orange Dialogue Suite a été utilisé comme outil pour 14 articles de conférences internationales parus ces 2 dernières années.
La VUI-completeness est un ensemble de contraintes indispensables à l’application la recherche au monde de l’industrie. Elle impose un contrôle total des dialogues potentiellement générés par le système, ainsi qu’une interprétabilité des choix appris par les algorithmes d’apprentissage.







