


“Alors que le chiffrement de l’Internet accroit le contrôle des plateformes sur les données, l’IA pourrait contribuer à opérer indépendamment les réseaux”
Le chiffrement du trafic Internet hier, aujourd’hui et demain
Le chiffrement du trafic est la pratique qui vise à rendre incompréhensible aux observateurs non autorisés les données échangées sur les réseaux.
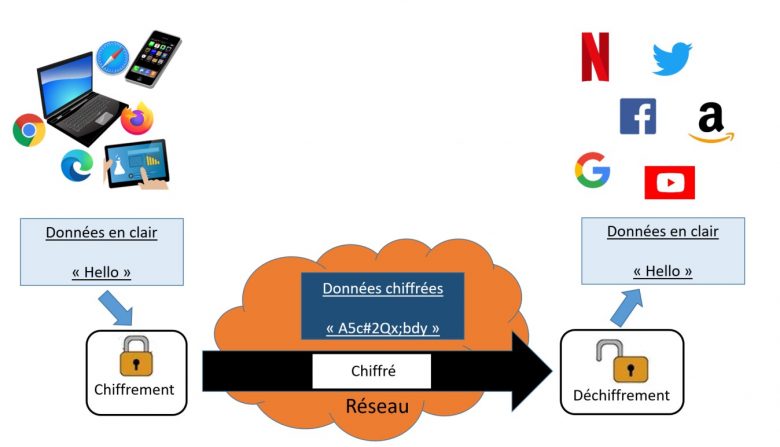
Figure 1: Le chiffrement de bout-en-bout du trafic sur l’Internet
Sur l’Internet le chiffrement du trafic a été popularisé par Netscape, avec l’introduction de SSL, l’ancêtre de TLS, à partir de 1995 et s’est développé avec l’essor du commerce électronique. Le chiffrement du trafic permet aux Internautes de vérifier que les sites sur lesquels ils se connectent correspondent bien aux noms affichés par le navigateur dans sa barre d’adresse (mais il ne protège pas contre les ressemblances de noms). D’autre part ce chiffrement rend incompréhensible aux tiers les données échangées à travers le réseau entre le navigateur et ces sites : un attaquant capable d’intercepter les communications sur le réseau est ainsi incapable d’accéder aux contenus de ces communications, comme par exemple les numéros de cartes bancaires.
Les écoutes de masse révélées par l’affaire Snowden en 2013 ont fait naitre la volonté de généraliser le chiffrement du trafic. Cette même année, l’Internet Engineering Task Force (IETF), l’organisme coordonnant l’élaboration des standards de l’Internet, déclare que les écoutes de masse sont une attaque technique contre la vie privée des utilisateurs de l’Internet [1]. Par la suite, les protocoles de l’Internet vont massivement faire usage du chiffrement.
En 2020, la part chiffrée du trafic Internet dans le monde était estimée autour de 85% du volume total [2]. Sur les réseaux d’Orange, cette part est passée de 50% fin 2015 à 85% début 2021. Avec les applications de certains acteurs comme Google, la part du trafic chiffré approche les 100% [3].
Dans sa forme actuelle, le chiffrement s’applique aux contenus applicatifs, comme les vidéos regardées, leurs titres ou les pages web parcourues.
Cependant le chiffrement actuel est imparfait et des informations sensibles pour la protection de la vie privée transitent encore en clair sur les réseaux (certaines sont contenues dans les 15% de volume de trafic en clair, d’autres sont échangées lors de la mise en place du chiffrement et révèlent des informations sensibles). Dans le détail, les applications émettent encore à ce jour en clair le nom du service Internet auxquelles les utilisateurs accèdent (par exemple https://www.youtube.com/). Cela se produit à deux moments : avec le DNS, lorsqu’il y a besoin de traduire un nom de service en une adresse sur le réseau Internet et lors de la mise en place du chiffrement avec le “Server Name Indication” contenu dans la poignée de main TLS.
La mobilisation des acteurs de l’Internet est forte pour corriger le non-chiffrement du nom de service, des expérimentations sont menées et des standards interopérables existent [4] ou sont en cours de conception [5].
Des motivations moins avouables à chiffrer le nom de service
Le chiffrement sécurise le commerce électronique, améliore la protection de la vie privée et rend difficile les écoutes de masse à partir des réseaux.
Les plateformes promouvant le chiffrement en retirent également un bénéfice d’image et un contrôle accru des données échangées.
Avec le chiffrement du service de traduction de nom en adresse Internet [4] et grâce à leur puissance de marché, elles ont même la possibilité de capter des données personnelles supplémentaires en poussant l’utilisation de leur propre service de traduction de nom en adresse Internet à la place de celui des opérateurs de réseau.
Conséquences pour les opérateurs de réseau
Les conséquences du chiffrement du trafic sur l’opération des réseaux sont nombreuses [6].
Ainsi, certaines pratiques des opérateurs de réseau ont été largement transformées. C’est par exemple le cas de la mise en cache des contenus populaires. La mise en cache permet d’optimiser la qualité d’expérience des utilisateurs et les coûts des réseaux et des plateformes. Avant la généralisation du chiffrement, cette mise en cache était réalisée de façon transparente, c’est-à-dire au niveau du réseau, sans implication des plateformes. Dorénavant, elle est mise en œuvre sous le contrôle de la plateforme qui détient les clefs de chiffrement. Cet exemple, illustre que malgré une communication centrée sur la protection des données personnelles, le chiffrement sert d’autres objectifs des plateformes : ici éviter de perdre le contrôle du contenu.
Lorsque le chiffrement des noms de services sera effectif, d’autres pratiques vont être largement transformées. Il s’agit particulièrement des opérations reposant sur la classification par catégorie d’application (e.g. streaming vidéo, chat, webmail) ou par fournisseur de service (e.g. YouTube, Gmail, WhatsApp).
Classifier le trafic, à quoi ça sert ?
La classification permet de connaître les parts de marché des différentes applications ou catégories d’applications. L’analyse des usages par segments de clients et par offres permet alors de mettre sur le marché des offres plus pertinentes.
La classification de trafic permet aussi d’associer des mesures de qualité de service aux applications ou catégories d’applications. Ceci permet de prévoir au mieux les évolutions du trafic pour adapter les capacités réseau et offrir la meilleure qualité possible aux utilisateurs. Par exemple, la classification a permis d’anticiper le passage à la 4K de Netflix. Elle permet aussi de tenir compte de l’impact d’un match de foot sur le débit, en fonction de la chaine qui le diffuse.
Pour la détection de fraude, la classification permet d’identifier des usages abusifs, par exemple lorsque le trafic non-facturé est utilisé pour d’autres applications que celles prévues.
Comment classifier le trafic chiffré ?
Avec le trafic laissant apparaitre le nom du service en clair, la classification du trafic pouvait se faire directement en lisant des informations protocolaires non-chiffrées, comme les noms de service, dans les paquets IP constituant le trafic des applications. On parle d’inspection en profondeur des paquets ou de DPI pour Deep Packet Inspection.
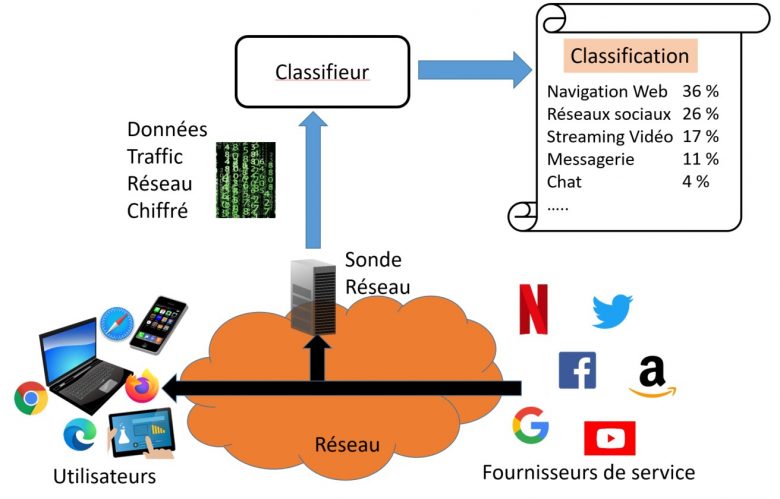
Figure 2: La classification du trafic chiffré
Avec le chiffrement à venir des noms de services, l’inspection en profondeur ne révélera plus directement l’application concernée. La question qui se pose est donc : est-ce que les caractéristiques intrinsèques des flux chiffrés constituant le trafic réseau permettent d’identifier l’application ou la catégorie d’application concernée ?
Les caractéristiques intrinsèques des flux sont les propriétés du trafic chiffré restant observables. Il s’agit d’abord des séries temporelles constituées des tailles des paquets, des délais entre les paquets, du sens du trafic (utilisateur vers serveur ou serveur vers utilisateur) et éventuellement des quelques données protocolaires non chiffrées des paquets échangés mais aussi des statistiques résumant l’ensemble d’un flux comme sa durée, les statistiques de débits et de volume de donnée par direction. Enfin, les informations échangées au moment de l’établissement de la session de chiffrement sont riches et peuvent aussi aider à identifier en partie l’application concernée.
Orange, en collaboration avec l’université de Waterloo au Canada, a développé un modèle d’IA (Intelligence Artificielle), composé de réseaux de neurones convolutifs et de réseaux récurrents à mémoire court et long terme, permettant de classifier les catégories d’applications (navigation web, streaming vidéo, chat, etc.) avec une réussite de 96% et les applications (Facebook, Gmail, Netflix, etc.) avec un taux de succès de 97%. Les tests ont été effectués pour classifier en 8 catégories d’applications (cf. Figure 4) et en 19 applications.
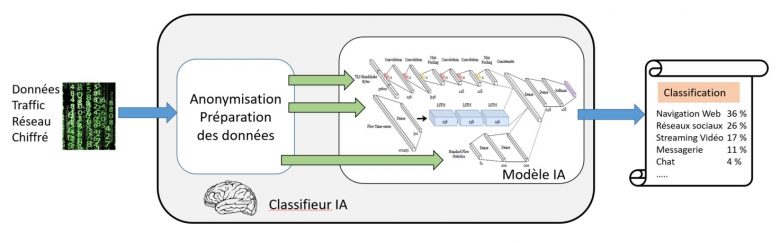
Figure 3: La classification du trafic par IA
La solution Orange-Waterloo présente des performances supérieures aux autres solutions de l’état de l’art, comme C4.5 [7], une solution basée sur des arbres de décision, largement utilisée pour la classification, qui n’assure qu’un taux de réussite de 81% ou que la solution de réseaux de neurones, CNN UCDavis [8], qui présente un taux de détection de 91 %. CNN UCDavis présente une détection assez proche d’Orange-Waterloo, cependant, elle présente de nombreux faux-positifs (mauvaise classification) alors qu’Orange-Waterloo réduit ce taux de faux-positifs de 50% par rapport à CNN UCDavis.
Avec la solution Orange-Waterloo, les valeurs de précision (proportion de prédictions correctes parmi toutes les prédictions faites) et de rappel (proportion de prédictions positives pour des échantillons qui sont réellement positifs) sont entre 90% et 100% suivant les catégories. Le taux de f1-score, combinaison des valeurs de précision et de rappel, présente une moyenne globale d’environ 94%, démontrant la bonne qualité du modèle (cf. Figure 5).
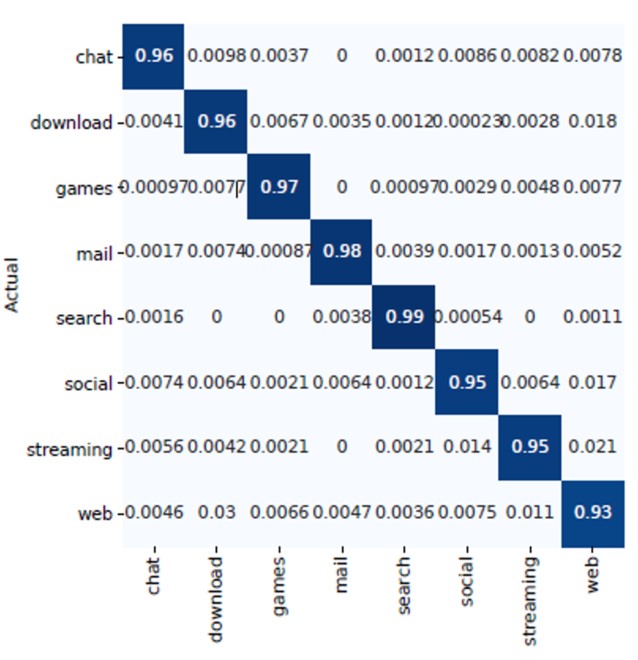
Figure 4:Matrice de confusion pour la classification des catégories d’applications
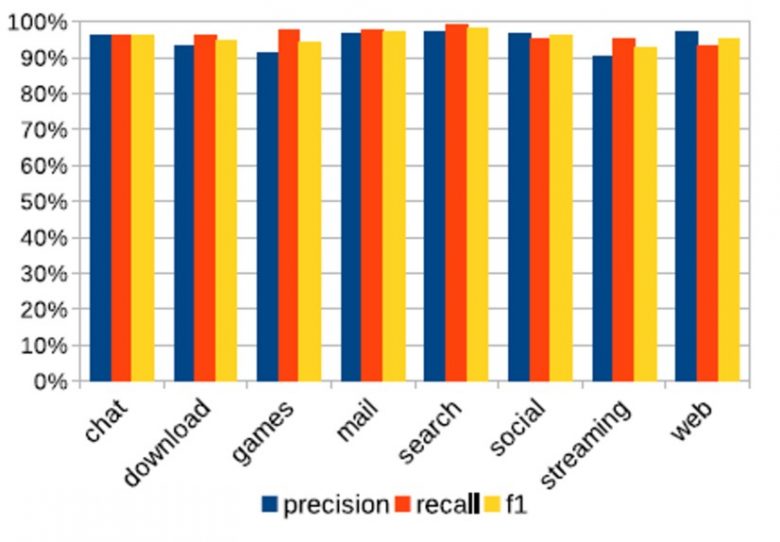
Figure 5:Valeurs de précision, de rappel et f1 score pour la classification des catégories d’applications
Ces résultats de recherche ont été acceptés pour publication à la conférence mondiale porte-drapeau du domaine : Sigmetrics 2021 et récompensé par le prix du meilleur papier d’étudiant. Le papier de conférence peut être consulté ici [9].
Perspectives
Le chiffrement du trafic Internet vise à renforcer la sécurité des échanges et la protection de la vie privée des utilisateurs vis-à-vis d’attaques menées depuis des réseaux. Il ne protège pas les données sensibles des attaques une fois stockées ou des usages abusifs des plateformes. La focalisation de la défiance sur les réseaux pourrait même permettre à certaines plateformes de collecter des données personnelles supplémentaires.
Le chiffrement du trafic Internet chamboule les opérations des réseaux basées sur la classification du trafic : conception d’offres réseau pertinentes ; amélioration de l’expérience client et détection de fraude. A terme, il y aurait le risque d’un transfert de contrôle vers les plateformes Internet disposant des données nécessaires. Ceci pose des questions d’évolution du marché des télécoms et de souveraineté.
Néanmoins les caractéristiques intrinsèques des flux chiffrés pourraient encore permettre, grâce à l’intelligence artificielle, d’identifier les applications et catégories d’applications.
Dans la méthode imaginée, l’algorithme d’intelligence artificielle est entrainé à partir de la “vérité terrain”, c’est-à-dire qu’il est entrainé à reconnaitre quel flux chiffré correspond à quelle application, connaissant l’application concernée. Avec l’amélioration du chiffrement, la “vérité terrain” ne sera plus disponible. Il est donc nécessaire de se passer de la vérité terrain dans une prochaine version de l’algorithme. Un autre défi consistera alors à opérationnaliser ces techniques d’intelligence artificielle de façon à les rendre applicables pour les opérations réseaux concernées avec notamment le probable besoin de cartes réseau capables d’exécuter de tels algorithmes aux vitesses élevées des artères réseau à un cout compatible avec les enjeux de la classification.
Références
[1] Pervasive Monitoring Is an Attack
[2] Fortinet Blog
[3] Google transparency report
[5] TLS Encrypted Client Hello
[6] Effects of Pervasive Encryption on Operators
[7] C4.5 Algorithm
[8] CNN UCDavis
[9] A Look Behind the Curtain: Traffic Classification in an Increasingly Encrypted Web
Informations additionnelles
Une version détaillée de ces travaux est disponible dans le journal “Proceedings of the ACM on Measurement and Analysis of Computing Systems”, volume 5, pages 1-26, publié en 2021.







