

“Une réponse doit pouvoir être apportée à une question essentielle: comment faire confiance aux décisions calculées par des systèmes à base d’IA?”
Une prise de conscience de tous les acteurs : régulateur, entreprises, société
Depuis 2018, au travers de différentes études, l’Europe promeut une IA éthique en proposant de simples recommandations. En 2021 néanmoins elle va préciser un cadre législatif contraignant sur l’usage des algorithmes utilisés en IA avec l’introduction des systèmes basés sur l’intelligence artificielle à hauts risques[1]. En parallèle, les entreprises mettent en place une gouvernance de l’IA. Orange notamment, après avoir signé la première charte internationale pour une Intelligence Artificielle inclusive[2] il y a un an avec le Fond Arborus, se dote aujourd’hui de son Conseil d’éthique de la data et de l’IA [3] afin d’accompagner la mise en œuvre de principes éthiques encadrant l’utilisation des technologies de data et d’Intelligence Artificielle. Enfin, devant la généralisation de l’usage de l’IA, certaines inquiétudes du public se font jour et un certain désarroi grandit face aux décisions prises automatiquement par les algorithmes issus des technologies d’apprentissage automatique. Ainsi, un individu peut se retrouver dans une situation où il ignore si une décision le concernant provient d’une réflexion humaine ou du calcul d’une machine. De très nombreux exemples existent, impactant plus ou moins fortement, d’une manière volontaire ou involontaire, l’individu dans sa vie personnelle. L’utilisation de systèmes basés sur l’intelligence artificielle peut être préjudiciable tant sur le plan matériel (en matière de sécurité et de santé) qu’immatériel (atteinte à la vie privée) et impliquer des risques de types très divers résultant de failles dans la conception globale des systèmes basés sur l’intelligence artificielle où de l’utilisation de données sans correction de biais éventuels.
Développer au plus tôt la confiance grâce à une approche éthico-technique
Dans le contexte de la cinquième révolution industrielle, axée sur les données numériques et l’intelligence artificielle, une prise de conscience a lieu quant aux risques potentiels qui l’accompagnent. Des principes éthiques issus de réflexions philosophiques millénaires doivent être respectés. Néanmoins, il s’agit d’en réinterpréter certains pour les adapter au domaine de l’IA avec l’objectif de concevoir une éthique du numérique. En particulier, une réponse doit pouvoir être apportée à une question essentielle: “Comment faire confiance aux décisions calculées par ces systèmes à base d’IA ?” Cette notion de confiance est centrale et il faut la prendre en compte au plus tôt, dès la conception du système basé sur l’intelligence artificielle. C’est une approche éthico-technique qui va permettre de répondre à cette question. Pour le Groupe d’expert européens (HLEG) [4] un système d’intelligence artificielle de confiance doit avoir trois caractéristiques essentielles: être licite en respectant des lois et réglementations applicables, être robuste techniquement et socialement et enfin être éthique en respectant un certain nombre de principes et de valeurs. Parmi les principes éthiques à respecter, l’équité et l’explicabilité peuvent être pris en compte au plus tôt grâce à la collaboration de deux acteurs centraux que sont le responsable de produit et le data scientist. Dans ce contexte, le premier se charge de la conception d’un système basé sur l’intelligence artificielle tandis que le second en assure le développement. De l’interaction entre ces deux métiers à chaque phase du développement du système va dépendre le succès final.
Le Système basé sur l’Intelligence Artificielle et son moteur à 4 temps
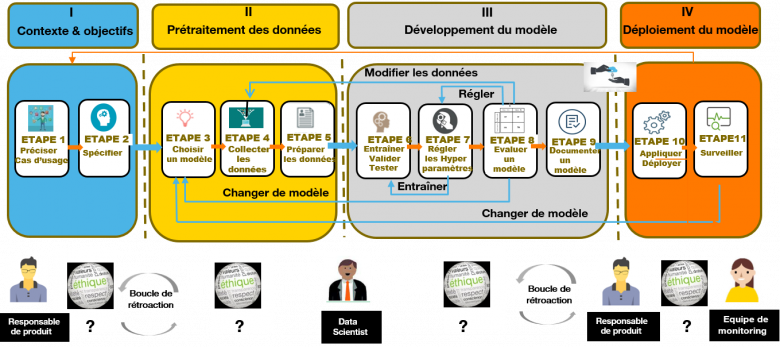
Il faut avoir un questionnement éthique à chaque phase du cycle de vie du développement d’un modèle et le dialogue entre Responsable Produit et Data Scientist est primordial
Dans un premier temps, dédié à la présentation des objectifs et du contexte d’usage, le data scientist doit prendre connaissance des exigences éthiques que le responsable de produit va lui demander d’intégrer. Ces exigences portent sur l’équité (nature des différences de traitement à combattre s’il existe des risques de biais) et sur l’explicabilité du modèle lui-même ou des décisions prises par celui-ci. Le deuxième temps consiste à sélectionner les algorithmes et les données qui vont permettre d’entrainer le modèle avec un risque de biais dans ces données. Dans un troisième temps le data scientist développe son modèle en intégrant les exigences éthiques. Enfin, dans un quatrième temps, lorsque le modèle est assez performant, il est intégré dans le service final puis mis à la disposition des utilisateurs. La gestion des questions éthiques doit donc être examinée dans chacune des phases mais principalement dans la phase de spécification et lors du développement proprement dit du système. Néanmoins, un autre facteur déterminant concerne les données utilisées pour la construction du modèle.
Avant tout des données de qualité
Concevoir un modèle performant mais également éthique dépend de la qualité des données. Il faut bien connaître le processus suivi pour les collecter et s’assurer de leur bonne représentativité (adéquation avec le contexte opérationnel réel), de leur conformité avec la Règlement général sur la protection des données et de leur intégrité (l’introduction de données malveillantes dans un système d’IA peut modifier son comportement). Le tableau suivant fournit les principales dimensions à prendre en compte pour développer un modèle :

Table 1: Quelques dimensions de la qualité des données
Puis prioriser ensemble
Une fois les exigences éthiques détaillées, le binôme responsable produit/data scientist peut s’appuyer sur une matrice de criticité. Selon le contexte, le binôme définira la gravité et la probabilité d’occurrence des problèmes éthiques. Cette matrice les aidera à prioriser les actions à mettre en place en fonction des risques et de leur gravité, comme le montre l’exemple ci-dessous.
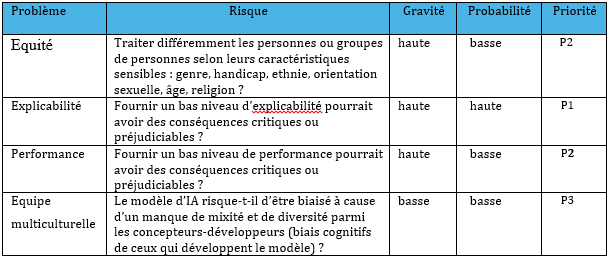
Table 2 La matrice de criticité permet de voir, dans cet exemple, que la priorité la plus haute est sur l’explicabilité puis sur l’équité et la performance alors que la présence d’une équipe multiculturelle n’est pas une priorité.
Le data scientist, lors la phase de développement du modèle, en fonction de ces priorités, intègre dans son code les exigences éthiques, d’une part en atténuant les biais susceptibles de provoquer des inégalités de traitement et, d’autre part, en fournissant les explications nécessaires pour la compréhension soit de son modèle lui-même soit des décisions prises, par exemple l’accord ou non d’un prêt bancaire.
Contre quelles inégalités de traitement lutter ?
Si les algorithmes sont aujourd’hui accusés de reproduire certains biais, ils peuvent aussi contribuer à les corriger. En quête d’équité, l’intelligence artificielle représente un formidable outil au profit de la lutte contre les inégalités [5], à condition de choisir la bonne stratégie. Le responsable de produit doit donc s’assurer que le système basé sur l’intelligence artificielle, une fois développé, ne va pas à l’encontre de principes inscrits dans une Charte de l’entreprise ou le cadre réglementaire auquel le service doit se soumettre. Il est de la responsabilité du responsable de produit de décider du type d’équité à mettre en œuvre (équité individuelle ou de groupe) et de la responsabilité du data scientist de développer un système basé sur l’intelligence artificielle répondant à cette exigence. L’équité individuelle assure que des individus aux profils proches seront traités de la même façon, autrement dit, les individus sont traités en fonction de leurs propres mérites. L’équité de groupe peut être obtenue en évitant que des impacts disproportionnés (Disparate Impact/DI) affectent certains groupes comme par exemple une décision défavorable ou bien en essayant d’obtenir des taux d’erreur identiques pour chacun des groupes (Disparate Mistreatment/DM).
Une fois le type d’équité à rechercher identifié, pour le data scientist, assurer l’équité revient généralement à intégrer un certain nombre de contraintes dans le programme d’optimisation permettant d’apprendre une règle de décision à partir des données mesurables. Il peut intervenir soit sur les données servant à entrainer le modèle d’IA (pre-processing) soit sur les paramètres de construction du modèle (in-processing), soit sur les résultats du modèle (post-processing). Lorsqu’il s’intéresse plus particulièrement à l’équité de groupe, pour l’aider à choisir, le data scientist peut se reposer sur un arbre de décisions comme celui proposé ci-dessous qui va permettre de découvrir, en fonction de la stratégie choisie, le bon algorithme à utiliser.
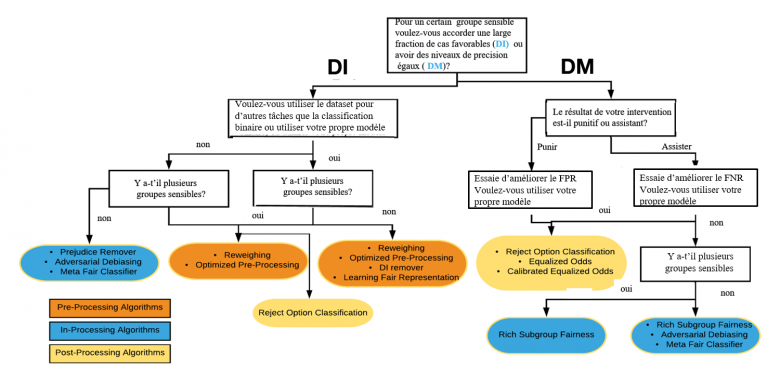
Sélectionner l’algorithme adapté pour répondre aux besoins d’équité de groupe (inspiré de l’arbre proposé par la société Aequitas [6])
Quelle explicabilité offrir ? Une histoire de contexte
La capacité à expliquer le fonctionnent d’un modèle et/ou pourquoi il a pris telle ou telle décision est la dernière exigence à satisfaire car elle suppose que le modèle est suffisamment performant et que les problèmes d’équité sont résolus. La nécessité d’expliquer s’impose pour trois raisons principales: atteindre un écosystème de confiance voulu par la commission européenne, être en conformité avec le Règlement général sur la protection des données et améliorer la sécurité des systèmes basés sur l’intelligence artificielle, en particulier pour les problèmes de cybersécurité.
A l’idéal, selon le principe de transparence, il devrait toujours être possible de fournir une justification rationnelle à toute décision prise avec l’aide d’un système basé sur l’intelligence artificielle et de traduire les calculs effectués dans une forme compréhensible pour l’être humain. Mais ce n’est pas toujours possible et, comme expliqué dans un article précédent [7] un nouveau champ de recherche a vu le jour et de nombreux algorithmes sont maintenant disponibles qui permettent d’expliquer le fonctionnement des modèles prédictifs. Par ailleurs, des implémentations de ces algorithmes commencent à être disponibles dans des boîtes à outils fournies par différents éditeurs logiciels comme IBM avec AIX360 et AIF360, Google avec What-If Tool ou encore Aequitas développé par l’université de Chicago. Mais choisir le bon algorithme d’explicabilité pour chaque cas d’usage est affaire de contexte et d’équilibre entre performance technique et respect éthique.
Pour aider au choix de la méthode la plus adéquate, notre binôme doit s’interroger sur le contexte d’usage du système basé sur l’intelligence artificielle. Plusieurs facteurs peuvent aider le data scientist à identifier la manière la plus appropriée pour fournir une explication : le destinataire, l’impact du système, l’environnement réglementaire, les facteurs opérationnels. Selon le profil du destinataire, les explications à lui fournir seront très différentes, comme l’illustre le tableau ci-dessous.

En fonction des profils des utilisateurs ce ne sera pas la même explication à fournir.
Imaginons que le data scientist développe un modèle d’IA aidant à sélectionner les demandeurs de prêts bancaires solvables. Il doit développer un modèle qui permette à la fois d’expliquer à un demandeur malheureux pourquoi sa demande n’a pas été acceptée et au conseiller financier de comprendre le fonctionnement général du modèle. Pour ce faire, il va choisir d’une part un algorithme d’explicabilité basé sur une approche dite locale pour expliquer la décision individuelle, et d’autre part un algorithme d’explicabilité basé sur une approche dite globale pour expliquer le fonctionnement global du modèle. Au-delà de ce choix, selon le modèle prédictif utilisé, le data scientist peut choisir un modèle directement explicable ou bien un algorithme spécifique d’explicabilité qu’il utilisera après avoir entraîné son modèle (approche post-hoc). De même, il peut choisir d’utiliser un algorithme d’explicabilité, soit spécifique au modèle développé, soit agnostique et utilisable avec tout type de modèle.
Sur la base des attentes du responsable de produit en termes d’explicabilité, il appartient au data scientist de définir l’algorithme qui permet de fournir l’explication attendue. Ceci peut être fait en utilisant un arbre de décisions, comme présenté ci-dessous, qui présente les différentes solutions disponibles. La méthode consiste alors à naviguer de haut en bas dans cet arbre jusqu’à identifier l’algorithme adéquat en fonction des objectifs.
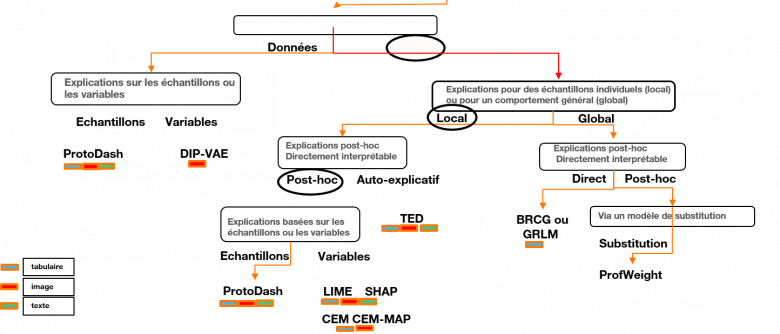
Algorithmes pour l’explicabilité des modèles d’IA : arbre de décision proposé par IBM [8.] Les feuilles finales de l’arbre fournissent les algorithmes disponibles.
On suit alors le chemin a, b, c, d et enfin e qui propose un des quatre algorithmes disponibles pour réaliser cette tâche, en l’occurrence l’algorithme SHA [9]. Lorsque le data scientist aura développé son modèle d’apprentissage, il utilisera SHAP pour fournir une explication.
L’éthique concerne chacun de nous
Au sein de l’entreprise, il devient nécessaire d’introduire une véritable culture éthique et d’y faire adhérer l’ensemble des collaborateurs. Car, au-delà du binôme responsable de produit-data scientist, un nombre de plus en plus important de métiers va être impliqué dans la conception de SIA responsables. Chez Orange, le numérique doit être responsable, soutenable et à sa juste place. Les chercheurs travaillent sur l’IA éthique qui fait face aux enjeux environnementaux et d’inclusion [10].
D’autre part, une formation à l’éthique et aux impacts sociétaux des technologies devrait être conduite dans les cycles de formation des ingénieurs afin de rendre naturelle et évidente la prise en compte de cette dimension lorsque ces derniers seront intégrés dans des entreprises et contribueront à la conception de nouveaux produits.
De plus, depuis une dizaine d’années, une prise de conscience des problèmes soulevés par un usage généralisé de l’IA est désormais effective et, aux niveaux politique aussi bien que scientifique, de nombreux travaux et réflexions sont engagés pour rendre les systèmes basés sur l’intelligence artificielle plus compréhensibles, plus équitables, plus transparents.
Certes, l’IA forte est encore dans son berceau et il ne faut craindre, ni à court ni à moyen terme, qu’elle puisse produire des systèmes basés sur l’intelligence artificielle dotés de consciences artificielles omniscientes. Pour autant, certains futuribles dystopiques pourraient nous conduire, à plus brève échéance, vers une algocratie reposant sur un usage immodéré de l’IA et des algorithmes. Gageons que le choix européen d’intégrer des exigences fortes d’éthique dans le développement de ces systèmes constitue un élément de réponse aux défis qui nous attendent.
En savoir plus
[1] Livre blanc sur l’intelligence artificielle Une approche européenne axée sur l’excellence et la confiance https://ec.europa.eu/info/sites/info/files/commission-white-paper-artificial-intelligence-feb2020_fr.pdf
[3] https://www.orange.com/fr/newsroom/communiques/2021/orange-cree-un-conseil-dethique-de-la-data-et-de-lia
[4] HLEG Groupe d’experts de haut niveau sur l’intelligence artificielle Lignes directrices en matière d’éthique pour une IA digne de confiance https://ec.europa.eu/digital-single-market/en/high-level-expert-group-artificial-intelligence
[5] https://hellofuture.orange.com/fr/comment-lia-peut-aider-a-reduire-les-inegalites/
[7] https://hellofuture.orange.com/fr/x-ia-comprendre-comment-les-algorithmes-raisonnent/
[8] IBM AIX360 https://github.com/Trusted-AI/AIX360
[9] https://github.com/slundberg/shap ; voir aussi https://www.quantmetry.com/blog/valeurs-de-shapley/
 Christèle Tarnec
Christèle Tarnec







