


- Les utilisateurs sont tous différents, certains n’ont pas de contrainte particulière mais ont des habitudes d’usage, des préférences. D’autres, telles les personnes en situation de handicap ou les séniors, peuvent avoir, en plus de ces habitudes, des contraintes lors de l’utilisation d’un service numérique.
- Ces contraintes peuvent être très diverses, d’ordre perceptif (visuel, auditif, tactile), d’ordre moteur (pointage, manipulation, parole) ou cognitif (compréhension, lecture). Toutefois, il est peu envisageable de les prévoir toutes lors de la conception d’un service.
- Et si tout service, toute interface pouvait s’ajuster continuellement à ces contraintes ou habitudes d’usage ? C’est là qu’un algorithme d’apprentissage automatique (« Machine Learning » en anglais) peut s’avérer fort pertinent.
Besoin de personnalisation des interfaces numériques
Aujourd’hui, force est de constater que le numérique est devenu omniprésent dans la société, augmentant la diversité des utilisateurs ainsi que les situations d’usage, mais avec pour conséquence l’apparition de freins dans l’usage des services, voire de points de blocage chez une part importante de la population.
La mise en œuvre adaptative et originale d’une approche bayésienne non paramétrique permet de répondre aux exigences des interfaces adaptatives en matière de robustesse et d’apprentissage sur peu de données
Comment dans ces conditions concevoir des interfaces numériques qui répondent aux besoins du plus grand nombre ? Ou comment rendre tout service, toute interface accessible à chaque personne qui l’utilise, c’est-à-dire, à la fois perceptible, manipulable, compréhensible et robuste ? La réponse classique se traduit aujourd’hui par une mise en conformité, principalement technique, aux règles des WCAG 2.2[1], incluant la compatibilité avec les aides techniques (zoom, lecteur d’écran, plage Braille, etc.). Mais cela implique de nombreux réglages pouvant engendrer de la complexité pour l’utilisateur lors de la prise en main de son interface. Par ailleurs, cette approche standard de l’accessibilité, bien que nécessaire, ne prend pas en compte les habitudes d’usage, telle que l’usage plus ou moins fréquent et selon différentes stratégies de tel ou tel service ou fonction. C’est pourquoi, dans une perspective d’amélioration de l’utilisabilité de ses produits et services, la recherche d’Orange explore une approche où l’interface s’ajuste aux besoins spécifiques de l’utilisateur courant. Il s’agit d’une approche de personnalisation de l’interface telle que définie par Simonin & Carbonell [1]. Ces besoins peuvent être liés à des contraintes sensorielles, actionnelles, cognitives en lien avec des déficiences, ou bien à des contextes particuliers (peu ou pas de luminosité, bruit ambiant, situation assise, double tâche, stress…). Ces besoins peuvent également être liés à des habitudes d’usage, ce qui est rarement pris en compte aujourd’hui dans les services ou les outils numériques. Aussi, une interface adaptative devrait permettre d’apporter à l’utilisateur des modifications de son expérience pour répondre à ses besoins spécifiques en configurant la mise en page [2], le contenu ou les fonctionnalités du système. Cette personnalisation peut impliquer le déplacement d’éléments dans une interface pour refléter ses priorités, la mise en exergue de ses éléments d’interface préférés et de ses parcours usuels, l’anticipation de ses actions, etc.
Système adaptatif et modèle d’interaction
Plus généralement, un système adaptatif sera défini comme un système capable de modifier de manière automatique ou semi-automatique ses caractéristiques en fonction des besoins de l’utilisateur, pour un usage défini dans un contexte précis. Il s’agira notamment de prendre en compte la diversité :
- des profils utilisateurs (leurs préférences et capacités physiques),
- de leurs habitudes d’usage ou stratégies d’utilisation (modèle de tâches),
- des contextes environnementaux dans lesquels ils évoluent.
En effet, les recherches sur la personnalisation des interfaces [3] [4] [5] ont montré que l’utilisateur ne parvenait souvent pas à configurer/personnaliser lui-même son interface, et qu’une aide fournie par le système était souhaitable pour l’aider à déterminer son propre profil utilisateur, à prendre conscience de ses habitudes d’usage, de leurs changements au cours du temps, ainsi que des variations des contextes d’usage. Ce paradigme a été exploré pour des applications spécifiques, comme la consultation des actualités sur un smartphone [6] afin notamment de faciliter la navigation et d’aller au-delà de la recommandation de contenus : « les personnes comme vous qui ont fait ceci ont ensuite choisi cela ». Il repose sur un modèle d’interaction conçu comme une extension du profil utilisateur : « vous avez l’habitude de faire ceci et allez probablement choisir cela ». Sa génération implique d’une part, une captation continue de l’activité de l’utilisateur (quels boutons il sélectionne, quels liens il clique, quels menus il actionne…) et d’autre part, des heuristiques ou un modèle prédictif produit par un algorithme d’apprentissage automatique capable d’inférer les caractéristiques du profil utilisateur au cours du temps. Par exemple, dans Constantinides & Dowell [6] l’inférence des trois caractéristiques dites de « haut-niveau » (comme la stratégie de navigation de l’utilisateur) utilise un modèle prédictif (de type classifieur) ayant été entrainé hors-ligne sur des données étiquetées issues d’un corpus de « logs d’activité ». Ce type d’approche est cependant peu flexible et peu apte à rendre compte de changements de comportement au cours du temps. C’est pourquoi, la recherche d’Orange vise une approche plus souple où l’apprentissage du modèle se fait au fil de l’eau. Loin du Big Data et de l’IA générative, cette recherche se préoccupe ici du “Small Data”, c’est-à-dire, les données particulières issues de l’utilisateur et pour son usage personnel. Ces données d’activité sont utilisées par le système pour générer un modèle de tâche probabiliste réactualisé en permanence. Il constitue la pierre angulaire de la personnalisation de l’expérience. Au plan [2], elle se concentre sur un paradigme de personnalisation permettant à l’utilisateur de mieux se repérer dans son interface et d’agir plus facilement en fonction de ses propres habitudes d’usage. Concrètement, il s’agira d’effectuer des statistiques d’usage de l’interface pour chaque habitude, chaque contrainte propre à chaque individu, afin de proposer à l’utilisateur d’ajuster l’usage du service, soit en le guidant sur ses parcours habituels (par des surlignements, des mises en focus), soit en rendant l’interface plus efficiente (par des réorganisations ou des créations de raccourcis). Pour atteindre cet objectif il faut résoudre des difficultés algorithmiques de conception et de mise en œuvre de ce paradigme, puis des difficultés ergonomiques.
Problématique algorithmique de la personnalisation
Une mise en œuvre opérationnelle exige d’automatiser la génération du modèle d’interaction et de le rendre évolutif au cours du temps, de sorte qu’il s’ajuste en permanence au comportement changeant de l’utilisateur. Comment faire alors pour qu’une application puisse créer automatiquement et mettre à jour continuellement un modèle d’interaction propre à l’utilisateur courant ? Pour ce faire, nous partons du principe que le modèle prédictif doit satisfaire à plusieurs propriétés, notamment en termes d’ [3] et d’apprentissage continu, ce qui n’est pas sans poser de difficultés. En effet, en apprentissage automatique, les modèles prédictifs sont généralement statiques [7]. Ils ne peuvent s’adapter dans le temps [8] ou seulement à la marge au moyen de techniques de « fine tuning » [9]. De fait, ils ont régulièrement besoin d’être réentraînés. Mais dans un environnement dynamique changeant régulièrement, comme celui du comportement humain, cette approche n’est pas appropriée. C’est pourquoi, le domaine émergeant du « Continual Learning » encore nommé « incremental learning » ou « lifelong learning » [10] [11] [8] [12] étudie des algorithmes capables d’apprendre continuellement en environnement changeant, avec la capacité de retenir et d’accumuler les connaissances passées, de pouvoir en tirer des inférences, d’utiliser ces connaissances pour en apprendre plus facilement de nouvelles et ainsi résoudre de nouvelles tâches. Plus précisément, il s’agit de développer la capacité d’apprentissage séquentiel. Cette propriété est généralement associée à un apprentissage continu. Elle revêt un aspect crucial dans le contexte de l’interaction homme-machine. En effet, contrairement à un apprentissage classique où toutes les tâches sont apprises simultanément à partir d’un jeu de données équilibré, dans un apprentissage séquentiel les tâches ne sont pas toutes présentes dans les données au même moment, car certaines apparaîtront ultérieurement, voire disparaîtront après un certain temps. Tout l’enjeu est alors de disposer d’un modèle prédictif capable d’apprendre de nouvelles tâches mais sans devoir rejouer les données passées, ce qui implique de conserver en mémoire les apprentissages anciens. Dans cette problématique d’adaptation continue de l’interface, la solution repose sur des systèmes autonomes apprenant à partir d’un flux de données continu [8].
Les chercheurs d’Orange visent en particulier un apprentissage auto-supervisé de type incrémental en ligne. Cela signifie qu’un seul exemple est présenté à chaque fois pour mettre à jour le modèle prédictif [12]. De tels systèmes continuent donc d’apprendre après leur déploiement de façon autonome et économe. Toutefois, ce nouveau domaine, très orienté « réseaux de neurones », se heurte au phénomène d’instabilité connu sous le nom de « catastrophic forgetting » [11] qui apparaît lorsque l’on tente d’apprendre une nouvelle tâche sans rejouer les exemples passés qui ont servi à apprendre les tâches anciennes. Plusieurs stratégies ont été élaborées pour contrer ce problème, mais qui ne semblent pas abouties à ce jour. En outre, le « Deep Learning » implique des données d’apprentissage en grand nombre, ce dont on ne dispose pas ici vu que la captation porte sur l’activité d’un seul utilisateur. Qui plus est, même en disposant de données en quantité, cette approche rend difficile l’obtention de mesures d’incertitude fiables sur les prédictions. En effet, Contrairement à certains modèles probabilistes, la plupart des réseaux de neurones ne produisent pas directement des distributions de probabilité, ces dernières constituant un indicateur fiable de la confiance. De plus, ils ont tendance à s’adapter parfaitement aux données d’entrainement, ce qui peut conduire à une surestimation de la confiance en cas de nouvelles données à traiter. Pour toutes ces raisons, les chercheurs d’Orange ont privilégié une approche probabiliste bayésienne, car mieux à même de quantifier et de gérer l’incertitude de manière rigoureuse, en particulier dans un environnement changeant.
Problématique ergonomique de la personnalisation
D’un point de vue UX, plusieurs travaux de recherche [13][14][15] pointent l’importance du rapport bénéfice/coût (humain) des adaptations dans l’acceptation de ces mécanismes, ainsi que les critères de stabilité, de fiabilité (au sens « accuracy ») et de prédictibilité. En effet, la fiabilité des prédictions alliée à la prédictibilité de l’interface sont une composante clé de la confiance de l’humain envers la machine. Dans sa démarche « d’initiative mixte », Eric Horvitz [14] explique que le système doit pouvoir évaluer en continu le rapport bénéfice/coût des adaptations initiées par le système. Le bénéfice correspond ici à la valeur perçue par l’utilisateur (par exemple un guidage réussi). Il tient compte du taux de réussite de l’IA que l’on peut mesurer à l’aide de probabilités (ou degrés de confiance). Il est d’autant plus grand que le système se trompe rarement (incertitude faible). Quant au coût, il correspond aux conséquences pour l’utilisateur en cas d’erreur d’adaptation (une proposition inadaptée engendrant des actions supplémentaires inutiles pour l’utilisateur). Dans ce schéma, la nature des adaptations (réorganisation, création de raccourcis, suggestions, etc.) est guidée par ce rapport évalué au fil de l’eau. Horvitz souligne que la mesure d’incertitude (l’inverse du degré de confiance) est centrale pour pouvoir gérer à tout moment le niveau d’automatisation du service et le dialogue avec l’utilisateur. Dit autrement, le défi est de trouver à chaque instant le bon niveau de délégation accordé au système et les moyens de contrôle de cette délégation. Une des conséquences est qu’en présence d’incertitude, il faut préférer « faire moins » mais correctement. C’est par exemple le cas avec la navigation guidée qui engendre peu de modifications d’interface et qui peut donc se mettre en place rapidement sans attendre d’avoir un niveau de confiance élevé sur les intentions de l’utilisateur, les conséquences en cas de maladaptation étant limitées.
Cette démarche est d’une vive actualité avec la question de l’utilisation/adoption de l’IA dans les services numériques. Elle est reprise aujourd’hui par la société LangChain au travers du cadre de conception basé sur la formule [4]. Cette formule empirique permet de quantifier la confiance perçue par l’utilisateur lors de l’utilisation d’un service assisté par l’IA, ceci en mettant en balance la valeur pour l’utilisateur, lorsque l’IA réussit, et les barrières psychologiques liées à l’appréhension de l’erreur et à l’effort de réparation.
Modélisation probabiliste robuste et continue des habitudes d’usage
Comme déjà mentionné, l’humain étant un être changeant, un apprentissage continu et séquentiel s’impose. Les chercheurs d’Orange étudient par conséquent la question de l’apprentissage robuste et continu (de type auto-supervisé et incrémental) dans le but de créer et de maintenir au cours du temps un modèle d’interaction propre à l’utilisateur courant. La Recherche d’Orange a ainsi conçu une approche d’apprentissage automatique robuste visant à concevoir des interfaces numériques capables de s’adapter dynamiquement à différents utilisateurs et stratégies d’utilisation. L’algorithme, qui s’appelle [5], utilise des statistiques bayésiennes pour modéliser le comportement de navigation des utilisateurs, se concentrant sur leurs habitudes plutôt que sur des préférences de groupe. Il se distingue par son apprentissage incrémental en ligne, permettant des prédictions fiables même avec peu de données et dans le cas d’un environnement changeant. Cette méthode d’inférence adaptative vise donc à modéliser les habitudes d’usage de l’utilisateur courant. L’algorithme apprend de nouvelles tâches tout en préservant les connaissances antérieures. Une tâche habituelle sera alors considérée comme une séquence d’actions que l’utilisateur effectue de manière routinière sur l’interface afin d’atteindre un but (par exemple effectuer un virement bancaire ou lancer un épisode de sa série préférée). Notons que cette technique, centrée sur les habitudes d’usage, ne traite pas des autres dimensions du profil utilisateur comme ses préférences ou capacités physiques [17] qui peuvent être traitées par d’autres moyens, notamment par des interfaces flexibles et adaptables dans une logique de Conception Universelle [18].
Au travers de ABIT-H, la Recherche d’Orange met en œuvre une technique d’inférence adaptative originale combinant la théorie des réseaux bayésiens [19] avec celle du filtrage numérique. L’approche bayésienne non paramétrique, en s’appuyant sur le théorème de Bayes, permet de déterminer la classe la plus probable pour une nouvelle observation en se basant sur la distribution a priori des classes (les hypothèses de sortie) et la distribution conditionnelle des données. Quant à la théorie du filtrage, elle est exploitée pour construire des estimateurs adaptatifs de fréquences relatives. Ces derniers permettent d’estimer les probabilités en jeu de façon adaptative, chaque nouvelle observation venant mettre à jour leur valeur. À noter que ces estimateurs sont dotés d’une mémoire interne dont la taille s’ajuste automatiquement au problème. Cette caractéristique permet de maintenir dans le temps les estimations de probabilité et de garantir leur combinaison cohérente dans le calcul de la probabilité bayésienne de sortie (i.e. la probabilité a posteriori). Grâce à cette technique adaptative de la recherche d’Orange, les distributions de probabilité sont estimées avec précision au fil de l’eau. L’application du critère de maximisation de la probabilité a posteriori fournir alors la solution qui minimise l’erreur de classification globale. La [6] de l’algorithme découle de cette approche mathématique optimale, conçue pour s’adapter à un environnement en évolution.
Cette technique a été mise en œuvre au sein de l’application mobile [7] et éprouvée dans le cas d’une manipulation réelle effectuée par un utilisateur ayant créé des habitudes d’usage.
La Recherche d’Orange s’est concentrée sur les deux paradigmes suivants de personnalisation :
- Le guidage de l’utilisateur le long de ses chemins habituels, à l’aide d’un focus de sélection (matérialisé par un rectangle orange) se positionnant automatiquement sur les boutons d’action les plus probables.
- La création automatique sur la page d’accueil de raccourcis d’actions (le bouton «Étiquettes vocales ») liés aux habitudes les plus fortes de l’utilisateur, comme illustré dans la Figure 1.
Le guidage automatique lors d’une tâche d’interaction permet de réduire la charge mentale de l’utilisateur, ce qui profite à tous, et ce qui permet aussi de compenser un handicap cognitif. La création automatique de raccourcis d’actions permet de diminuer le nombre d’actions pour exécuter une tâche, ce qui profite également à tous, et qui est très utile pour pallier notamment le handicap moteur.
À travers ce prototype, la Recherche d’Orange a également voulu tester la capacité de ABIT-H à modéliser finement l’activité d’interaction de l’utilisateur, ceci au moyen d’un « modèle de tâches » pouvant être généré automatiquement par l’algorithme. En effet, ce modèle interprétable fournit une représentation graphique de l’interaction (codée en langage Dot) incorporant les statistiques d’usage de l’utilisateur, comme illustré dans la Figure 1. Dans ce graphe orienté, chaque nœud correspond à un menu qui a été sélectionné par l’utilisateur. Chaque branche du graphe correspond à une tâche de navigation de l’utilisateur, comme la séquence : Menu -> Réglages -> Autre Audio -> Étiquettes vocales. Le modèle fait apparaître la structure logique de navigation de l’interface ainsi que les probabilités conditionnelles de transitions entre les menus. La probabilité globale pour chaque tâche est indiquée en fin de chemin (à droite) sur l’échelle dite des évidences en décibans (dB). Cette probabilité reflète le niveau d’usage de chaque tâche à l’instant courant. On peut par exemple déduire de ce modèle que l’accès à la fonction « Étiquettes vocales » (évidence de -6 dB) correspond à la tâche la plus probable de l’utilisateur au moment considéré.
Le modèle de tâches permet de suivre en temps réel l’évolution de l’usage de l’application par l’utilisateur, en discriminant les usages ponctuels de ceux habituels, et en mettant en exergue les stratégies de navigation personnelles, comme ici la façon d’atteindre la fonction « Mon numéro » en passant par la catégorie « Menu » plutôt que « Communiquer ».
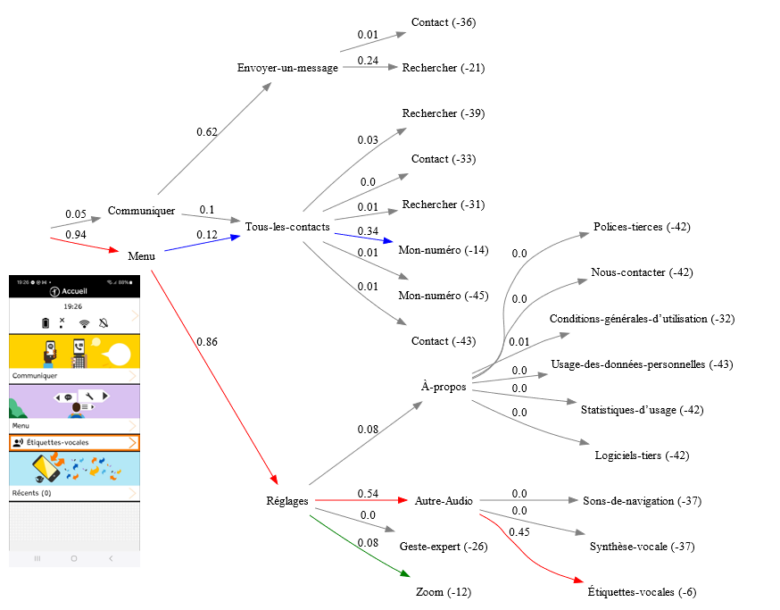
Figure 1: modèle de tâches généré en temps réel par ABIT-H à partir de l’interaction d’un utilisateur avec l’application mobile Tactile Facile.
Pour une validation plus globale et quantitative, les chercheurs d’Orange ont réalisé des simulations numériques [16] démontrant la capacité d’apprentissage séquentiel de l’algorithme. Soulignons que cette caractéristique forte implique aussi bien l’apprentissage de nouvelles habitudes, que le désapprentissage d’habitudes anciennes devenues obsolètes. Dans ce nouveau schéma, la relation entre l’homme et la machine fait l’objet d’un ajustement permanent de part et d’autre, dans une forme de co-apprentissage.
Conclusion
Notre article décrit une approche innovante pour améliorer l’interaction entre l’utilisateur et une interface numérique, en utilisant des statistiques bayésiennes pour analyser et comprendre les habitudes et contraintes propres à chaque utilisateur.
Parce que l’être humain est un être changeant, la Recherche d’Orange s’est concentrée sur l’apprentissage continu et séquentiel dans un environnement dynamique. Dans ce contexte, l’inférence bayésienne confère au modèle la capacité de réviser ses croyances à chaque nouvelle donnée, de façon rationnelle en présence d’incertitude. Ces travaux ont abouti à l’algorithme ABIT-H permettant une mise en œuvre itérative et incrémentale, à même de produire des mesures d’incertitude fiables sur les prédictions, ce qui est crucial dans un contexte UX où le système est susceptible de prendre des décisions autonomes entraînant des modifications d’interface. La technique a été éprouvée au travers de l’application mobile Tactile Facile et au moyen de simulations de tâches de navigation dans un menu hiérarchique, démontrant ainsi la capacité du modèle à apprendre rapidement de nouvelles tâches, de manière robuste, tout en maintenant ses connaissances passées.
Ces résultats de recherche ouvrent la voie à des systèmes adaptatifs améliorant l’expérience de l’utilisateur en l’aidant à mieux se repérer et à agir sur son interface. À travers cette approche, la conception de l’interaction homme-machine est repensée pour que l’utilisateur ait moins à s’adapter aux contraintes de la machine, celle-ci devant s’adapter à l’humain.
[1] Règles pour l’accessibilité des contenus web
[2] UX pour User Experience ; fait référence à une conception ergonomique centrée utilisateur.
[3] La notion d’inférence robuste fait référence ici à la capacité de l’IA à savoir douter raisonnablement, ce qui implique de pouvoir détecter une situation incertaine, qu’elle soit engendrée par un manque de connaissance, par la variabilité intrinsèque des données ou la présence d’exemples contradictoires.
[4] CAIR pour Confidence in Artificial Intelligence Results: https://blog.langchain.com/the-hidden-metric-that-determines-ai-product-success
[5] ABIT-H : « Adaptive Bayesian Inference Technique with Hierarchical structure” est un algorithme pour la classification adaptative multi-label, employée pour la modélisation de séquences d’actions [16].
[6] La robustesse s’entend comme la capacité d’un système à se maintenir stable (à court terme) et viable (à long terme) malgré les fluctuations de l’environnement, selon la définition du biologiste Olivier Hamant. Ce dernier de préciser que la robustesse s’oppose à la performance qui est liée à un milieu stable et contrôlé.
[7] Tactile Facile : prototype de recherche d’Orange donnant accès aux fonctions de base de la téléphonie et mettant en œuvre les principes de la conception universelle.
Sources :
[1] Simonin & Carbonell, 2007. Interfaces adaptatives Adaptation dynamique à l’utilisateur courant. Interfaces numériques.
[2] Vanderdonckt, Bouzit, Calvary, & Chêne, 2020. Exploring a Design Space of Graphical Adaptive Menus: Normal vs Small Screens. ACM Transactions on Interactive Intelligent Systems.
[3] Oppermann, 1994. Adaptively supported adaptability. International Journal of Human-Computer Studies, Vols. 40-3, pp. 455-472.
[4] McGrenere , Baecker , & Booth, 2002. An evaluation of a multiple interface design solution for bloated software. In CHI ‘02(ACM Press).
[5] Bunt & Conati, 2004. What role can adaptive support play in an adaptable system? In Proceedings of the 9th international conference on Intelligent user interfaces (ACM), pp. 117–124.
[6] Constantinides & Dowell, 2018. A Framework for Interaction-driven User Modeling of Mobile News Reading Behaviour. Proceedings of the 26th Conference on User Modeling, Adaptation and Personalization, pp. 33 – 41.
[7] Wikipédia, Apprentissage supervisé, 2025. Apprentissage automatique supervisé
[8] Shaheen, Hanif, Hasan, & Shafique, 2022. Continual Learning for Real-World Autonomous Systems: Algorithms, Challenges and Frameworks. Journal of Intelligent & Robotic Systems, Volume 105, Issue 1.
[9] IBM, 2025. fine tuning.
https://www.ibm.com/think/topics/fine-tuning
[10] Chen & Liu, 2018. Lifelong machine learning. Synthesis Lectures on Artificial Intelligence and Machine Learning. Morgan & Claypool Publishers.
[11] Luo, Yin, Bai, & Mao, 2020. An Appraisal of Incremental Learning Methods. Entropy – Open Access Journals, 22, 1190. (doi.org/10.3390/e22111190).
[12] Hoi, Sahoo, Lu, & Zhao, 2021. Online learning: A comprehensive survey. Neurocomputing, 459, C, 249–289 (doi.org/10.1016/j.neucom.2021.04.112).
[13] Sears, A., & Shneiderman, B. (1994). Split menus: effectively using selection frequency to organize menus. ACM Transactions on Computer-Human Interaction (TOCHI), Volume 1, Issue 1, pp. 27 – 51.
[14] Horvitz, 1999. Principles of mixed-initiative user interfaces. In Proceedings of the SIGCHI conference on Human Factors in Computing Systems, CHI ‘99, pp. 159-166.
[15] Gajos, K., Everitt, K., Tan, D., Czerwinski, M., & Weld, D. (2008). Predictability and Accuracy in Adaptive User Interfaces. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pp. 1271 – 1274.
[16] Apprentissage automatique robuste et continu des habitudes d’usage pour adapter les interfaces numériques aux besoins des utilisateurs, HAL 2025.
https://hal.science/hal-05204331v1/
[17] Martin-Hammond, et al., 2018. Designing an Adaptive Web Navigation Interface for Users with Variable Pointing Performance. Proceedings of the 15th International Web for All Conference W4A ‘18, Vols. 31, 1–10(ACM NY USA).
[18] Stephanidis, 2001. User Interfaces for All: New perspectives into Human-Computer Interaction. Concepts, Methods, and Tools (Mahwah, NJ: Lawrence Erlbaum Associates), pp. 3-17.
[19] Wikipédia : réseaux bayésiens
En savoir plus :
En pratique il n’est pas rare de trouver dans une application (web, mobile, TV) une fonction qui soit atteignable par différents chemins. Ainsi, plusieurs stratégies sont généralement possibles lorsque l’on manipule une interface utilisateur riche. Le fait d’arriver par un certain chemin peut déterminer la façon d’utiliser une fonction ou peut conditionner la suite des actions effectuées. Dans ce cas, le graphe logique de navigation/actions fait apparaitre des nœuds ayant plusieurs entrées et plusieurs issues. Une approche bayésienne naïve ne fonctionne pas dans ce cas, d’où l’importance de considérer une approche optimale prenant en compte toutes les relations de dépendance entre les variables.







