


La performance des modèles d’IA dépend conjointement de l’optimisation logicielle et de la puissance du matériel. L’analyse des interactions entre ces deux dimensions constitue un enjeu central pour le déploiement efficace de l’IA générative à grande échelle.
La bande passante mémoire reste le facteur limitant principal, et les innovations actuelles tentent de contourner cette contrainte.
La bande passante mémoire augmente bien moins vite que la puissance de calcul. Elle est de très loin le facteur limitant des LLMs. Toutes les optimisations actuelles tentent de compenser ce handicap.
Qu’est-ce qu’un GPU et pourquoi est-il si important ?
Les modèles d’intelligence artificielle génératives, comme ChatGPT ou Claude, sont des programmes informatiques extrêmement gourmands en calculs. Pour fonctionner rapidement, ces derniers ont besoin de processeurs spécialisés appelés GPU (processeurs graphiques) qui peuvent exécuter des milliers d’opérations en parallèle. Un GPU peut être considéré comme un ordinateur miniature dédié aux calculs parallèles. Contrairement au processeur principal (CPU) de votre ordinateur qui traite les tâches une par une, le GPU peut traiter des milliers d’opérations simultanément.
Le GPU possède ses propres unités de traitement, sa hiérarchie mémoire, et ses interfaces de communication. Cette architecture autonome permet au GPU de fonctionner indépendamment une fois les données chargées, sans intervention constante du CPU hôte.
Le GPU NVIDIA H200, par exemple, contient :
- 132 unités de calcul qui travaillent en parallèle
- 141 GB de mémoire ultra-rapide
- Des connexions spécialisées pour communiquer avec d’autres GPU
La figure suivante illustre l’architecture :
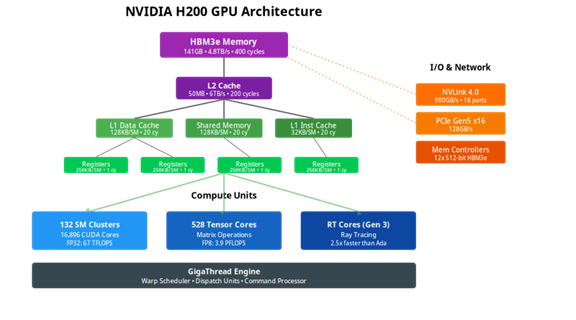
Le défi de la mémoire, principal goulet d’étranglement
Le frein majeur n’est pas la vitesse de calcul, mais l’accès à la mémoire. Par analogie ce serait comme disposer d’une équipe de 1000 ouvriers très rapides, mais d’un seul ascenseur pour leur apporter les matériaux. La mémoire HBM3e du GPU peut transférer 4,8 téraoctets par seconde, ce qui est 40 fois plus rapide que les connexions avec la mémoire principale de l’ordinateur. Cette différence crée un goulot d’étranglement majeur lors des transferts CPU-GPU. Les systèmes d’inférence efficaces minimisent donc ces transferts en maintenant les données sur le GPU pendant toute la durée du traitement. Chaque transfert inutile entre CPU et GPU peut ralentir le temps de traitement par plusieurs ordres de grandeur.
Comment fonctionnent les modèles Transformer ?
Les modèles de langage modernes utilisent une architecture appelée Transformer, qui fonctionne en deux phases pendant l’inférence.
La phase de prefill traite l’intégralité du texte d’entrée en parallèle afin de construire le contexte initial. La phase de génération produit ensuite les tokens de sortie, de manière séquentielle. Ces deux phases ont des profils computationnels opposés : le prefill est contraint par la puissance de calcul (compute-bound), tandis que la génération est limitée par la bande passante mémoire (memory-bound). En effet, l’ensemble des poids du modèles doivent être transférés de la mémoire du GPU vers les registres à travers les caches mémoire. Cette différence détermine les stratégies d’optimisation appropriées pour chaque phase.
Le mécanisme d’attention
Le mécanisme d’attention constitue le cœur de l’architecture Transformer. Pour chaque token dans une séquence, le modèle calcule trois matrices appelées : Query (Q), Key (K), et Value (V). La matrice Query représente ce que le token actuel recherche, Key représente les informations qu’offre chaque token, et Value stocke le contenu réel à transmettre.
Le calcul d’attention fonctionne de la manière suivante : le modèle calcule des scores en multipliant la Query du token actuel avec toutes les Keys de la séquence. Ces scores sont ensuite normalisés via une fonction softmax pour obtenir des poids entre 0 et 1. Et ces poids sont ensuite appliqués aux Values pour produire la sortie finale. Le modèle utilise plusieurs « têtes » d’attention en parallèle (des sous-matrices pour Q, K et V), chacune capturant différents types de relations dans le texte. Cette architecture permet au modèle de comprendre des relations complexes, comme identifier à quoi se réfère un pronom dans une phrase longue.
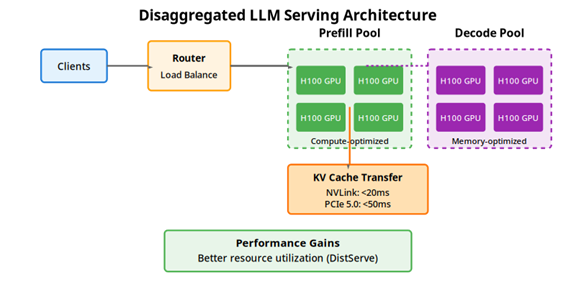
Figure: Disaggregated LLM Serving Architecture
Les optimisations fondamentales
- Le : éviter les calculs inutiles
Au lieu de recalculer les mêmes informations à chaque nouveau mot généré, le système stocke les résultats précédents dans un cache KV. - FlashAttention : optimiser les accès mémoire
Cette technique combine plusieurs opérations en une seule pour éviter les allers-retours inutiles vers la mémoire. Au lieu de faire 6 transferts de données, elle n’en fait que 2, ce qui améliore l’efficacité de 35% à 75%. - La : échanger la précision contre la vitesse
Les modèles peuvent fonctionner avec moins de précision numérique. Au lieu d’utiliser 32 bits par nombre, on peut utiliser 16, 8 ou même 4 bits. Cela divise la taille du modèle par 2, 4 ou 8, permettant de traiter plus de requêtes simultanément.
Les défis de la mise à l’échelle : stratégies de parallélisme Tensor vs Pipeline
Les plus gros modèles ne tiennent pas sur un seul GPU. Il faut donc les répartir sur plusieurs GPU qui doivent communiquer entre eux. Deux stratégies principales existent. Le Parallélisme Tensoriel (TP) divise chaque couche du modèle entre les GPU : chaque GPU calcule une partie de chaque opération matricielle et les résultats sont combinés. Cette approche nécessite une communication constante entre GPU (après chaque couche), donc une bande passante élevée est indispensable. Le Parallélisme Pipeline (PP) assigne des couches entières à chaque GPU : le GPU 1 exécute les couches 1-20, le GPU 2 les couches 21-40, etc. Les données passent de GPU en GPU comme dans une chaîne de montage. Cette approche nécessite moins de bande passante mais crée des temps morts quand certains GPU attendent les résultats des autres.
Spécialisation matérielle, orchestration distribuée et IA sur mobile pour faire toujours mieux
Alors que les modèles frontières dépassent le trillion de paramètres et que les fenêtres de contexte s’étendent à des millions de tokens, trois tendances émergent clairement :
- La spécialisation matérielle s’accélère.
Les Tensor Cores, les accélérateurs FP8, et les architectures comme Blackwell montrent que l’ère du GPU généraliste touche à sa fin. Chaque nouveau design optimise spécifiquement pour les patterns d’accès mémoire des Transformers. Surveillons l’arrivée des circuits encore plus spécialisés, comme GroQ, Cerebras, Etched.
- L’orchestration distribuée devient critique.
Avec des modèles nécessitant 8, 16, voire des dizaines de GPU connectés, l’efficacité de la communication inter-accélérateurs détermine directement la viabilité économique. NVLink, InfiniBand et les interconnexions optiques ne sont plus des luxes mais des nécessités.
- L’intelligence s’approche de l’edge (IA sur mobile).
Les puces mobiles commencent à exécuter des modèles de plusieurs milliards de paramètres localement. Cette démocratisation de l’inférence transformera radicalement l’interaction homme-machine, éliminant la latence réseau et garantissant la confidentialité, mais les capacités des modèles embarqués sont encore très limitées.
Conclusion
L’évolution conjointe des architectures GPU et des modèles Transformer a créé une synergie remarquable qui alimente la révolution de l’IA générative. Chaque niveau de l’architecture matérielle – des registres ultra-rapides à la mémoire HBM3e – joue un rôle crucial dans la performance globale. La bande passante mémoire reste le goulet d’étranglement fondamental, dictant les stratégies d’optimisation à tous les niveaux.
Les innovations logicielles comme FlashAttention, PagedAttention et la quantification ne sont pas de simples optimisations marginales ; elles représentent des changements clés dans notre approche du calcul parallèle. Le passage de FP32 à FP8 ou INT4 n’est plus un compromis mais une nécessité stratégique pour déployer des modèles toujours plus grands. La désagrégation prefill-decode montre que l’optimisation système dépasse la simple accélération matérielle pour repenser fondamentalement l’architecture de service.
Le paradoxe central reste : alors que la puissance de calcul continue d’augmenter fortement, la bande passante mémoire progresse linéairement. Cette divergence force l’innovation constante dans les algorithmes et architectures.
Pour les praticiens, le message est clair : comprendre l’interaction entre matériel et logiciel n’est plus optionnel. Choisir entre FP16 et INT4, entre parallélisme tensoriel et pipeline, entre vLLM et TensorRT-LLM, ces décisions techniques déterminent si un service sera économiquement viable ou non. Un modèle de 70B paramètres peut coûter 0,01€ ou 1€ par requête selon l’implémentation.
L’avenir immédiat promet des défis fascinants. Les architectures MoE (Mixture of Experts) comme Gemini 3 Pro montrent qu’on peut contourner certaines limites en activant sélectivement des parties du modèle. Mais à court terme, l’optimisation de l’existant – réduire chaque transfert mémoire inutile, maximiser l’utilisation de chaque cycle GPU – reste le défi quotidien.
Nous sommes à un point d’inflexion où la compréhension profonde de ces systèmes sépare les déploiements réussis des échecs coûteux. L’inférence efficace n’est pas qu’une question de performance ; c’est la clé qui déverrouille le potentiel transformateur de l’IA générative pour des applications réelles à grande échelle.
4,8 To/s :
Bande passante de la NVIDIA H200. Le débit mémoire d’une carte GPU haut de gamme est 5000 fois plus élevé que celui que la fibre résidentielle.
Sources :
– [NVIDIA H200 Architecture Whitepaper] (https://www.nvidia.com/en-us/data-center/h200/)
– [FlashAttention 2] (https://arxiv.org/abs/2307.08691)
– [vLLM: Easy, Fast, and Cheap LLM Serving] (https://vllm.ai/)
En savoir plus :
– [Attention Is All you Need: l’architecture du Transformer] (https://arxiv.org/abs/1706.03762)
– [A White Paper on Neural Network Quantization] (https://arxiv.org/abs/2106.08295)
– Billet du Blog de la Recherche Orange : ChatGPT est-il un agent conversationnel de type humain ? – Hello Future







