À l’heure où, dans la plupart des grandes entreprises européennes, tous les regards sont tournés vers le RGPD et certains de ses articles en particulier – comme l’Art. 20 sur la portabilité des données – les GAFAM montrent un état d’avancement contrasté pour se plier à ce règlement. Si certains semblent encore avoir du chemin à faire, les plus grands responsables de traitement semblent globalement très bien préparés à la nouvelle législation autour du droit à la portabilité des données, au point d’être prêts plusieurs mois avant sa mise en application. Au grand bénéfice de l’utilisateur ? Cela reste à explorer. En effet, les questionnements autour de la pertinence de services proposés pour la réutilisation des données récupérées et de l’intérêt que pourrait y trouver l’individu semblent encore loin d’avoir pu obtenir des éléments de réponse satisfaisants.
À quelques mois de la mise en application du Règlement Général de Protection des Données (RGPD), prévue le 25 mai 2018, les questionnements liés à la mise en œuvre opérationnelle de ce nouveau texte européen, notamment dans les entreprises, restent multiples. L’article 20, relatif au droit à la portabilité des données, est sans doute l’un des plus discutés. En élargissant le sens de la portabilité telle qu’elle était pratiquée jusqu’à présent en matière de numéro de téléphone ou plus récemment de données bancaires, le règlement laisse une marge de manœuvre à l’interprétation, qui fait débat chez les data controllers (responsables de traitement). En tout état de cause, il appelle des évolutions techniques et organisationnelles substantielles dans les entreprises.
Le droit à la portabilité des données
Le droit à la portabilité des données comporte deux volets. En premier lieu, le droit pour l’individu (le data subject) de récupérer, dans un format répondant à certains critères de lisibilité et d’interopérabilité, l’ensemble des données personnelles le concernant, qui ont été collectées par un organisme, public ou privé. Dès lors il peut transmettre ces dernières à un ou plusieurs autres services, sans que le service originel qui les lui a restituées ne puisse y faire obstacle. En second lieu, le responsable de traitement A doit transférer les données personnelles à un responsable de traitement B sur demande du data subject et sans l’intervention directe de ce dernier. Il est donc important de ne pas considérer le droit à la portabilité des données comme une simple transférabilité élargie entre différents organismes. La dimension récupération, qui s’ajoute aux droits d’accès et d’effacement préexistants sans les remplacer, est donc fondamentale.
Même si la finalité première de cet article 20 reste le renforcement de la protection des données personnelles, ce dernier participe également d’une politique de concurrence. En facilitant le passage d’un service à un autre, il ouvre une fenêtre d’opportunité pour lutter contre le caractère hégémonique des GAFAM (Google, Apple, Facebook, Apple, Microsoft) et permettre à d’autres acteurs, grands ou petits, de proposer des services concurrents. Pour autant, le droit à la portabilité des données, dont la compréhension et les modalités de mise en œuvre semblent encore balbutiantes dans la plupart des entreprises européennes, effraie-t-il vraiment les GAFAM ? Dans quelle mesure sont-ils préparés à appliquer l’article 20 ?
Google, Facebook et Twitter : les acteurs en avance
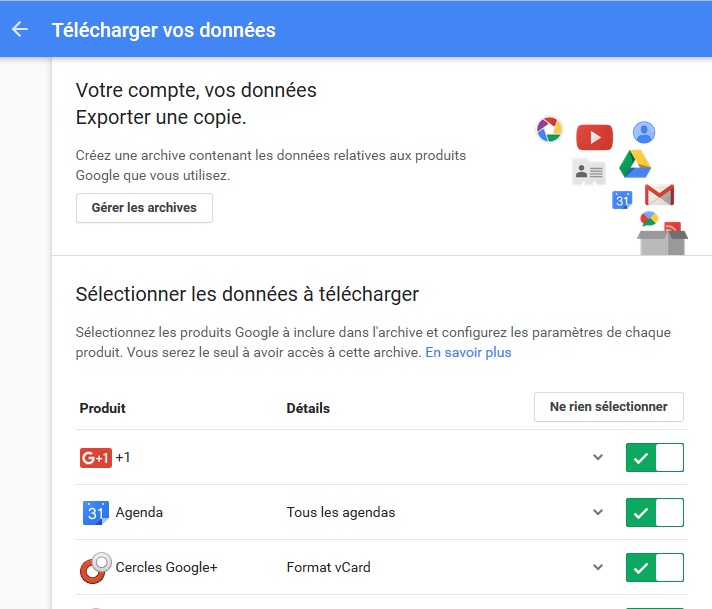
Google apparait comme un des acteurs les plus avancés en matière de droit à la portabilité. Dès 2009, la firme de Mountain View a ouvert le service Google Data Liberation Front ou GDLF, porté par une équipe d’ingénierie dédiée. Si le GDLF a jusqu’ici permis essentiellement à Google de jouer la carte de la transparence alors qu’elle est régulièrement critiquée pour sa collecte massive de données, il pourrait constituer un avantage décisif dans la mise en application de la portabilité. Suite à la récupération des données dans une archive qui peut se révéler volumineuse, il est possible d’en exporter l’intégralité vers des services de cloud tels que Microsoft OneDrive ou Dropbox. Les données d’un compte Google sont récupérables au format interopérable .JSON. Dans certains cas plus spécifiques, des données peuvent se télécharger en XML (données de géolocalisation) ou en vCard (données de contact). La manœuvre n’est cependant pas automatisée, c’est à l’utilisateur de faire le nécessaire. Pour l’heure, l’individu joue le rôle intermédiaire entre deux services, dans une logique de B to C to B. Il est également possible de récupérer directement son historique Google Search, ainsi que d’obtenir une liste exhaustive des applications gratuites et payantes téléchargées sur le Play Store depuis la création de son compte Google.
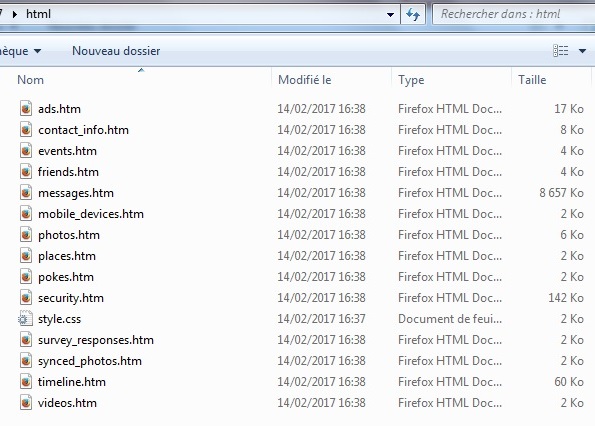
Facebook qui est régulièrement pointé du doigt pour la complexité de ses paramètres de confidentialité, propose également une archive téléchargeable de l’ensemble des données de l’utilisateur… ou presque. En effet, le volume de données accessibles et visibles depuis la version web de Facebook est supérieur à celui du contenu de l’archive téléchargeable. L’écart apparaît notamment pour l’historique des actions effectuées sur le compte (par exemple : mentions likes et commentaires postés sur le mur d’amis ou d’amis d’amis). Inversement, l’archive donne accès à certaines données qui ne sont pas consultables directement sur le site, comme les clics sur publicités (horodatés) ou l’historique des connexions au compte (géolocalisées par adresse IP). Les données accessibles sont de facto éparpillées entre l’archive, le site web, la version app mobile et même, parfois, la version mobile du site web. Cela engendre une pluralité de lieux, d’interfaces à maîtriser, de manipulations à effectuer qui, sans doute, perdent l’utilisateur. Les données récupérées dans l’archive sont au format HTML (cf. capture d’écran ci-dessous), ce qui facilite leur consultation : un double clic entraîne l’ouverture du navigateur internet et un utilisateur même novice peut facilement lire et comprendre le contenu de l’archive. En revanche, ce choix de format s’oppose à de futures perspectives de transférabilité.
Twitter propose également de télécharger les données personnelles liées à un compte dans une archive. L’accès à cette fonctionnalité est rapide et facile, et l’archive récupérée est disponible dans différents formats : en HTML ce qui facilité la consultation, mais également en CSV et JSON. A partir du fichier CSV, il est possible de consulter les données dans un tableur. La lecture est légèrement plus complexe et il est nécessaire de modifier la mise en forme lors de l’importation, mais les données restent lisibles sans nécessiter de connaissances particulières. Enfin, le format JSON permet une transférabilité du contenu de l’archive vers d’autres services. L’archive Twitter comprend l’historique des tweets, qui sont horodatés et géolocalisés si le possesseur du compte a activé cette fonctionnalité, mais aussi la source de l’envoi de chaque tweet (ex : Application tierce ou Twitter sur iOS, sur PC etc.), le ou les destinataire(s) et, bien sûr, le contenu du tweet. Dans les paramètres de confidentialité, Twitter propose par ailleurs une suppression rapide de la géolocalisation liée aux tweets. S’il est vrai que Twitter récolte beaucoup moins de données que d’autres applications, la plateforme de microblogging semble faire preuve d’une maturité certaine en matière de droit à la portabilité des données.
Apple, Microsoft et Amazon : encore du chemin à faire
Apple prétend apporter une exigence extrême à la protection des données personnelles de ses utilisateurs, et explique longuement sur son site officiel en quoi « les technologies les plus personnelles doivent aussi être les plus privées »… Mais si l’accent est clairement donné sur la sécurisation des données personnelles, leur récupération et leur transfert au sens du RGPD sont aux abonnés absents. L’écosystème Apple est véritablement hermétique : le seul transfert possible doit s’effectuer entre les différents produits de la marque, les données étant toutes reliées à un compte commun et pouvant être portées d’un iPhone à un iPad ou à un Macbook. Même la consultation des données s’avère parfois délicate. Par exemple, l’accès aux données de localisation est particulièrement compliqué. Un long voyage dans les paramètres d’iOS est indispensable pour découvrir qu’Apple collecte un historique des déplacements extrêmement précis. Comme sous Android, la récupération des données est soumise à un système de back up / restore géré par le logiciel iTunes. Les sauvegardes récupérées peuvent être utilisées dans différents terminaux iOS, mais la portabilité vers d’autres systèmes d’exploitation nécessite le recours à un logiciel tiers, tel que Kies proposé par Samsung pour passer d’iOS à Android. Si Apple se veut rassurante et idéalement, inattaquable sur la protection des données de ses utilisateurs, ces derniers n’ont finalement que bien peu de latitude sur la consultation, la récupération et le transfert de leurs données personnelles. Des initiatives telles que MoveToiOS, une application mobile d’Apple pour faciliter ces manipulations depuis un smartphone iOS vers un smartphone Android, ne fonctionne que dans ce sens et ne permet pas la réciproque.

Microsoft, l’un des plus gros responsables de traitement au monde, affirme également se préoccuper de la protection des données personnelles de ses utilisateurs et, à ce titre, prendre le RGPD très au sérieux : un pan entier de la partie « privacy » du site officiel de la marque, intitulé Trust Center, est consacré au nouveau règlement européen, et l’entreprise détaille pas à pas ses services, applications et initiatives en lien avec ce règlement. Cependant il est peu prolixe sur l’article 20 du RGPD, et pour cause : il n’est pas évident de récupérer ou de transférer ses données personnelles chez Microsoft. On devine que la mise en application de la portabilité est ici particulièrement complexe, en raison de la multiplicité des services proposés (Windows, Skype, Xbox OS, Cortana, Office, Bing, OneDrive, etc.). Une complexité renforcée par le fait que, contrairement à Google, Microsoft ne propose pas un lien vers un espace centralisant toutes les données utilisateur qui permettrait le téléchargement d’une archive. Le transfert n’est pas plus optimal : si Google propose par exemple de transférer l’intégralité des données de son compte sur Microsoft OneDrive, la réciproque n’est pour l’instant pas possible. Les données personnelles sont morcelées entre les différents services et leur consultation n’est pas toujours évidente.
Des six acteurs observés, Amazon semble le moins avancé en matière de droit à la portabilité des données. Le géant du e-commerce offre la possibilité au possesseur du compte de consulter et de contrôler (c’est-à-dire modifier et/ou supprimer) l’historique de navigation des produits du site, les commandes effectuées (historique d’achats) et les recommandations suggérées par l’algorithme. Le site propose également de masquer certains contenus (comme les commandes « sensibles » ou celles que l’on souhaite effectuer avec discrétion à l’occasion d’un anniversaire par exemple). Pour le reste, il n’est pas possible d’en récupérer une archive ni de les transférer à un autre service de e-commerce. Alors qu’Amazon semble efficace dans la sécurisation des données et a récemment concentré ses efforts sur ce point, avec par exemple la mise en place d’un blocage automatique du compte dès qu’une nouvelle adresse de livraison est ajoutée et qu’un utilisateur effectue une commande sur cette adresse, les prérequis pointés par l’article 20 du RGPD sont encore loin d’être atteints.
Un bilan plutôt mitigé, porté par certains acteurs bien avancés
Globalement, il ressort de notre étude que le chemin à parcourir pour rendre effectif le droit à la portabilité chez les grands acteurs du web reste important. Apple et Microsoft priorisent la sécurisation des données personnelles ; il leur reste à se focaliser sur la mise à disposition et la transférabilité de ces dernières pour se conformer au nouveau cadre légal à venir. Plus avancé, Facebook n’a pas attendu l’annonce du droit à la portabilité pour proposer à ses utilisateurs une archive de leurs données, mais celle-ci reste incomplète et son format rend toute interopérabilité inconcevable. Google et Twitter ont une certaine longueur d’avance, tant au niveau de l’exhaustivité du contenu de l’archive que de la praticité de sa récupération. Selon toute vraisemblance, ces trois derniers répondront donc présents dès la mise en application du droit à la portabilité des données et pourraient même bien devancer de nombreuses entreprises européennes, à l’heure où certaines réfléchissent encore au sens à donner au terme de « portabilité ». Google et Facebook prônent même, dans certaines déclarations publiques, une conformité plusieurs mois avant l’arrivée de la réglementation. Reste désormais ouverte la question substantielle de l’usage : qu’est-ce que l’individu pourra faire avec toutes ces archives de plusieurs gigaoctets de données sur son bureau ? Quels seront les services qui lui seront proposés et qui donneront tout son sens au droit à la portabilité ?